I’ve been talking a lot recently about how quantum algorithms don’t work. But last week JR Minkel, an editor at Scientific American, asked me to write a brief essay about how quantum algorithms do work, which he could then link to from SciAm‘s website.”OK!” I replied, momentarily forgetting about the 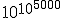 quantum algorithm tutorials that are already on the web. So, here’s the task I’ve set for myself: to explain Shor’s algorithm without using a single ket sign, or for that matter any math beyond arithmetic.
quantum algorithm tutorials that are already on the web. So, here’s the task I’ve set for myself: to explain Shor’s algorithm without using a single ket sign, or for that matter any math beyond arithmetic.
Alright, so let’s say you want to break the RSA cryptosystem, in order to rob some banks, read your ex’s email, whatever. We all know that breaking RSA reduces to finding the prime factors of a large integer N. Unfortunately, we also know that “trying all possible divisors in parallel,” and then instantly picking the right one, isn’t going to work. Hundreds of popular magazine articles notwithstanding, trying everything in parallel just isn’t the sort of thing that a quantum computer can do. Sure, in some sense you can “try all possible divisors” — but if you then measure the outcome, you’ll get a random divisor, which almost certainly won’t be the one you want.
What this means is that, if we want a fast quantum factoring algorithm, we’re going to have to exploit some structure in the factoring problem: in other words, some mathematical property of factoring that it doesn’t share with just a generic problem of finding a needle in a haystack.
Fortunately, the factoring problem has oodles of special properties. Here’s one example: if I give you a positive integer, you might not know its prime factorization, but you do know that it has exactly one factorization! By contrast, if I gave you (say) a Sudoku puzzle and asked you to solve it, a priori you’d have no way of knowing whether it had exactly one solution, 200 million solutions, or no solutions at all. Of course, knowing that there’s exactly one needle in a haystack is still not much help in finding the needle! But this uniqueness is a hint that the factoring problem might have other nice mathematical properties lying around for the picking. As it turns out, it does.
The property we’ll exploit is the reducibility of factoring to another problem, called period-finding. OK, time for a brief number theory digression. Let’s look at my favorite sequence of integers since I was about five years old: the powers of two.
2, 4, 8, 16, 32, 64, 128, 256, 512, 1024, …
Now let’s look at the powers of 2 “mod 15”: in other words, the remainder when 15 divides each power of 2.
2, 4, 8, 1, 2, 4, 8, 1, 2, 4, …
As you can see, taking the powers of 2 mod 15 gives us a periodic sequence, whose period (i.e., how far you have to go before it starts repeating) is 4. For another example, let’s look at the powers of 2 mod 21:
2, 4, 8, 16, 11, 1, 2, 4, 8, 16, …
This time we get a periodic sequence whose period is 6.
You might wonder: is there some general rule from which we could predict the period? Gee, I wonder if mathematicians ever thought of that question…
Well, duh, they did, and there’s a beautiful pattern discovered by Euler in the 1760’s. Let N be a product of two prime numbers, p and q, and consider the sequence
x mod N, x2 mod N, x3 mod N, x4 mod N, …
Then provided x is not divisible by p or q, the above sequence will repeat with some period that evenly divides (p-1)(q-1).
So for example, if N=15, then the prime factors of N are p=3 and q=5, so (p-1)(q-1)=8. And indeed, the period of the sequence was 4, which divides 8. If N=21, then p=3 and q=7, so (p-1)(q-1)=12. And indeed, the period was 6, which divides 12.
Now, I want you to step back and think about what this means. It means that, if we can find the period of the sequence
x mod N, x2 mod N, x3 mod N, x4 mod N, …
then we can learn something about the prime factors of N! In particular, we can learn a divisor of (p-1)(q-1). Now, I’ll admit that’s not as good as learning p and q themselves, but grant me that it’s something. Indeed, it’s more than something: it turns out that if we could learn several random divisors of (p-1)(q-1) (for example, by trying different random values of x), then with high probability we could put those divisors together to learn (p-1)(q-1) itself. And once we knew (p-1)(q-1), we could then use some more little tricks to recover p and q, the prime factors we wanted.
So what’s the fly in the ointment? Well, even though the sequence
x mod N, x2 mod N, x3 mod N, x4 mod N, …
will eventually start repeating itself, the number of steps before it repeats could be almost as large as N itself — and N might have hundreds or thousands of digits! This is why finding the period doesn’t seem to lead to a fast classical factoring algorithm.
Aha, but we have a quantum computer! (Or at least, we’re imagining that we do.) So maybe there’s still hope. In particular, suppose we could create an enormous quantum superposition over all the numbers in our sequence: x mod N, x2 mod N, x3 mod N, etc. Then maybe there’s some quantum operation we could perform on that superposition that would reveal the period.
The key point is that we’re no longer trying to find a needle in an exponentially-large haystack, something we know is hard even for a quantum computer. Instead, we’re now trying to find the period of a sequence, which is a global property of all the numbers in the sequence taken together. And that makes a big difference.
Look: if you think about quantum computing in terms of “parallel universes” (and whether you do or don’t is up to you), there’s no feasible way to detect a single universe that’s different from all the rest. Such a lone voice in the wilderness would be drowned out by the vast number of suburb-dwelling, Dockers-wearing conformist universes. What one can hope to detect, however, is a joint property of all the parallel universes together — a property that can only be revealed by a computation to which all the universes contribute.
(Note: For safety reasons, please don’t explain the above to popular writers of the “quantum computing = exponential parallelism” school. They might shrivel up like vampires exposed to sunlight.)
So, the task before us is not hopeless! But if we want to get this period-finding idea to work, we’ll have to answer two questions:
- Using a quantum computer, can we quickly create a superposition over x mod N, x2 mod N, x3 mod N, and so on?
- Supposing we did create such a superposition, how would we figure out the period?
Let’s tackle the first question first. We can certainly create a superposition over all integers r, from 1 up to N or so. The trouble is, given an r, how do we quickly compute xr mod N? If r was (say) 300 quadrillion, would we have to multiply x by itself 300 quadrillion times? That certainly wouldn’t be fast enough, and fortunately it isn’t necessary. What we can do instead is what’s called repeated squaring. It’s probably easiest just to show an example.
Suppose N=17, x=3, and r=14. Then the first step is to represent r as a sum of powers of 2:
r = 23 + 22 + 21.
Then
^2)^2%20\cdot%20(3^2)^2%20\cdot%203^2)
Also, notice that we can do all the multiplications mod N, thereby preventing the numbers from growing out of hand at intermediate steps. This yields the result
314 mod 17 = 2.
OK, so we can create a quantum superposition over all pairs of integers of the form (r, xr mod N), where r ranges from 1 up to N or so. But then, given a superposition over all the elements of a periodic sequence, how do we extract the period of the sequence?
Well, we’ve finally come to the heart of the matter — the one part of Shor’s quantum algorithm that actually depends on quantum mechanics. To get the period out, Shor uses something called the quantum Fourier transform, or QFT. My challenge is, how can I explain the QFT to you without using any actual math? Hmmmm…
OK, let me try this. Like many computer scientists, I keep extremely odd hours. You know that famous experiment where they stick people for weeks in a sealed room without clocks or sunlight, and the people gradually shift from a 24-hour day to a 25- or 26- or 28-hour day? Well, that’s just ordinary life for me. One day I’ll wake up at 9am, the next day at 11am, the day after that at 1pm, etc. Indeed, I’ll happily ‘loop all the way around’ if no classes or appointments intervene. (I used to do so all the time at Berkeley.)
Now, here’s my question: let’s say I tell you that I woke up at 5pm this afternoon. From that fact alone, what can you conclude about how long my “day” is: whether I’m on a 25-hour schedule, or a 26.3-hour schedule, or whatever?
The answer, of course, is not much! I mean, it’s a pretty safe bet that I’m not on a 24-hour schedule, since otherwise I’d be waking up in the morning, not 5pm. But almost any other schedule — 25 hours, 26 hours, 28 hours, etc. — will necessarily cause me to “loop all around the clock,” so that it’d be no surprise to see me get up at 5pm on some particular afternoon.
Now, though, I want you to imagine that my bedroom wall is covered with analog clocks. These are very strange clocks: one of them makes a full revolution every 17 hours, one of them every 26 hours, one of them every 24.7 hours, and so on for just about every number of hours you can imagine. (For simplicity, each clock has only an hour hand, no minute hand.) I also want you to imagine that beneath each clock is a posterboard with a thumbtack in it. When I first moved into my apartment, each thumbtack was in the middle of its respective board. But now, whenever I wake up in the “morning,” the first thing I do is to go around my room, and move each thumbtack exactly one inch in the direction that the clock hand above it is pointing.
Now, here’s my new question: by examining the thumbtacks in my room, is it possible to figure out what sort of schedule I’m keeping?
I claim that it is possible. As an example, suppose I was keeping a 26-hour day. Then what would happen to the thumbtack below the 24-hour clock? It’s not hard to see that it would undergo periodic motion: sure, it would drift around a bit, but after every 12 days it would return to the middle of the board where it had started. One morning I’d move the thumbtack an inch in this direction, another morning an inch in that, but eventually all these movements in different directions would cancel each other out.
On the other hand — again supposing I was keeping a 26-hour day — what would happen to the thumback below the 26-hour clock? Here the answer is different. For as far as the 26-hour clock is concerned, I’ve been waking up at exactly the same time each “morning”! Every time I wake up, the 26-hour clock is pointing the same direction as it was the last time I woke up. So I’ll keep moving the thumbtack one more inch in the same direction, until it’s not even on the posterboard at all!
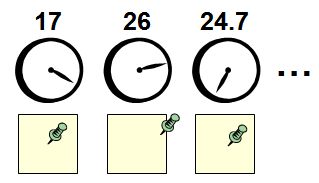
It follows, then, that just by seeing which thumbtack travelled the farthest from its starting point, you could figure out what sort of schedule I was on. In other words, you could infer the “period” of the periodic sequence that is my life.
And that, basically, is the quantum Fourier transform. Well, a little more precisely, the QFT is a linear transformation (indeed a unitary transformation) that maps one vector of complex numbers to another vector of complex numbers. The input vector has a nonzero entry corresponding to every time when I wake up, and zero entries everywhere else. The output vector records the positions of the thumbtacks on the posterboards (which one can think of as points on the complex plane). So what we get, in the end, is a linear transformation that maps a quantum state encoding a periodic sequence, to a quantum state encoding the period of that sequence.
Another way to think about this is in terms of interference. I mean, the key point about quantum mechanics — the thing that makes it different from classical probability theory — is that, whereas probabilities are always nonnegative, amplitudes in quantum mechanics can be positive, negative, or even complex. And because of this, the amplitudes corresponding to different ways of getting a particular answer can “interfere destructively” and cancel each other out.
And that’s exactly what’s going on in Shor’s algorithm. Every “parallel universe” corresponding to an element of the sequence contributes some amplitude to every “parallel universe” corresponding to a possible period of the sequence. The catch is that, for all periods other than the “true” one, these contributions point in different directions and therefore cancel each other out. Only for the “true” period do the contributions from different universes all point in the same direction. And that’s why, when we measure at the end, we’ll find the true period with high probability.
Obviously there’s a great deal I’ve skipped over; see here or here or here or here or here or here or here or here or here or here or here or here for details.
 Follow
Follow