My AI Safety Lecture for UT Effective Altruism
Monday, November 28th, 2022Two weeks ago, I gave a lecture setting out my current thoughts on AI safety, halfway through my year at OpenAI. I was asked to speak by UT Austin’s Effective Altruist club. You can watch the lecture on YouTube here (I recommend 2x speed).
The timing turned out to be weird, coming immediately after the worst disaster to hit the Effective Altruist movement in its history, as I acknowledged in the talk. But I plowed ahead anyway, to discuss:
- the current state of AI scaling, and why many people (even people who agree about little else!) foresee societal dangers,
- the different branches of the AI safety movement,
- the major approaches to aligning a powerful AI that people have thought of, and
- what projects I specifically have been working on at OpenAI.
I then spent 20 minutes taking questions.
For those who (like me) prefer text over video, below I’ve produced an edited transcript, by starting with YouTube’s automated transcript and then, well, editing it. Enjoy! –SA
Thank you so much for inviting me here. I do feel a little bit sheepish to be lecturing you about AI safety, as someone who’s worked on this subject for all of five months. I’m a quantum computing person. But this past spring, I accepted an extremely interesting opportunity to go on leave for a year to think about what theoretical computer science can do for AI safety. I’m doing this at OpenAI, which is one of the world’s leading AI startups, based in San Francisco although I’m mostly working from Austin.
Despite its name, OpenAI is famously not 100% open … so there are certain topics that I’m not allowed to talk about, like the capabilities of the very latest systems and whether or not they’ll blow people’s minds when released. By contrast, OpenAI is very happy for me to talk about AI safety: what it is and and what if anything can we do about it. So what I thought I’d do is to tell you a little bit about the specific projects that I’ve been working on at OpenAI, but also just, as an admitted newcomer, share some general thoughts about AI safety and how Effective Altruists might want to think about it. I’ll try to leave plenty of time for discussion.
Maybe I should mention that the thoughts that I’ll tell you today are ones that, until last week, I had considered writing up for an essay contest run by something called the FTX Future Fund. Unfortunately, the FTX Future Fund no longer exists. It was founded by someone named Sam Bankman-Fried, whose a net worth went from 15 billion dollars to some negative number of dollars in the space of two days, in one of the biggest financial scandals in memory. This is obviously a calamity for the EA community, which had been counting on funding from this individual. I feel terrible about all the projects left in the lurch, to say nothing of FTX’s customers.
As a tiny silver lining, though, instead of writing up my thoughts for that essay contest, I’ll just share them with you right now, for free!
The Scaling of AI
Let’s start with this: raise your hand if you’ve tried GPT-3. That’s maybe half of you. OK, raise your hand if you’ve tried DALL-E. That’s again maybe half of you.
These are the two best-known products that are made by OpenAI, and as I think most people would agree, two of the most impressive AIs that exist in the world right now. They certainly go far beyond what I would’ve predicted would be possible now, if you’d asked me 10 years ago or even 5 years ago.
And whenever I try to explain them to people, I’m, like, well, you have to see them. No abstract description can substitute in this case.
All right, so here’s what GPT-3 produced when a New Yorker writer asked it to write a poem about cryptocurrency in the style of Philip Larkin, who was a famous 20th-century poet. The subject seems particularly appropriate given current events.
The Invention (by GPT-3)
Money is a thing you earn by the sweat of your brow
And that’s how it should be.
Or you can steal it, and go to jail;
Or inherit it, and be set for life;
Or win it on the pools, which is luck;
Or marry it, which is what I did.
And that is how it should be, too.
But now this idea’s come up
Of inventing money, just like that.
I ask you, is nothing sacred?
Okay, it won’t always produce something of this quality (incidentally, I don’t think GPT-3 actually “married money”!). Often you’ve got to run it several times and take the best output—much like human poets presumably do, throwing crumpled pages into the basket. But I submit that, if the above hadn’t been labeled as coming from GPT, you’d be like, yeah, that’s the kind of poetry the New Yorker publishes, right? This is a thing that AI can now do.
So what is GPT? It’s a text model. It’s basically a gigantic neural network with about 175 billion parameters—the weights. It’s a particular kind of neural net called a transformer model that was invented five years ago. It’s been trained on a large fraction of all the text on the open Internet. The training simply consists of playing the following game over and over, trillions of times: predict which word comes next in this text string. So in some sense that’s its only goal or intention in the world: to predict the next word.
The amazing discovery is that, when you do that, you end up with something where you can then ask it a question, or give it a a task like writing an essay about a certain topic, and it will say “oh! I know what would plausibly come after that prompt! The answer to the question! Or the essay itself!” And it will then proceed to generate the thing you want.
GPT can solve high-school-level math problems that are given to it in English. It can reason you through the steps of the answer. It’s starting to be able to do nontrivial math competition problems. It’s on track to master basically the whole high school curriculum, maybe followed soon by the whole undergraduate curriculum.
If you turned in GPT’s essays, I think they’d get at least a B in most courses. Not that I endorse any of you doing that!! We’ll come back to that later. But yes, we are about to enter a world where students everywhere will at least be sorely tempted to use text models to write their term papers. That’s just a tiny example of the societal issues that these things are going to raise.
Speaking personally, the last time I had a similar feeling was when I was an adolescent in 1993 and I saw this niche new thing called the World Wide Web, and I was like “why isn’t everyone using this? why isn’t it changing the world?” The answer, of course, was that within a couple years it would.
Today, I feel like the world was understandably preoccupied by the pandemic, and by everything else that’s been happening, but these past few years might actually be remembered as the time when AI underwent this step change. I didn’t predict it. I think even many computer scientists might still be in denial about what’s now possible, or what’s happened. But I’m now thinking about it even in terms of my two kids, of what kinds of careers are going to be available when they’re older and entering the job market. For example, I would probably not urge my kids to go into commercial drawing!
Speaking of which, OpenAI’s other main product is DALL-E2, an image model. Probably most of you have already seen it, but you can ask it—for example, just this morning I asked it, show me some digital art of two cats playing basketball in outer space. That’s not a problem for it.

You may have seen that there’s a different image model called Midjourney which won an art contest with this piece:

It seems like the judges didn’t completely understand, when this was submitted as “digital art,” what exactly that meant—that the human role was mostly limited to entering a prompt! But the judges then said that even having understood it, they still would’ve given the award to this piece. I mean, it’s a striking piece, isn’t it? But of course it raises the question of how much work there’s going to be for contract artists, when you have entities like this.
There are already companies that are using GPT to write ad copy. It’s already being used at the, let’s call it, lower end of the book market. For any kind of formulaic genre fiction, you can say, “just give me a few paragraphs of description of this kind of scene,” and it can do that. As it improves you could you can imagine that it will be used more.
Likewise, DALL-E and other image models have already changed the way that people generate art online. And it’s only been a few months since these models were released! That’s a striking thing about this era, that a few months can be an eternity. So when we’re thinking about the impacts of these things, we have to try to take what’s happened in the last few months or years and project that five years forward or ten years forward.
This brings me to the obvious question: what happens as you continue scaling further? I mean, these spectacular successes of deep learning over the past decade have owed something to new ideas—ideas like transformer models, which I mentioned before, and others—but famously, they have owed maybe more than anything else to sheer scale.
Neural networks, backpropagation—which is how you train the neural networks—these are ideas that have been around for decades. When I studied CS in the 90s, they were already extremely well-known. But it was also well-known that they didn’t work all that well! They only worked somewhat. And usually, when you take something that doesn’t work and multiply it by a million, you just get a million times something that doesn’t work, right?
I remember at the time, Ray Kurzweil, the futurist, would keep showing these graphs that look like this:
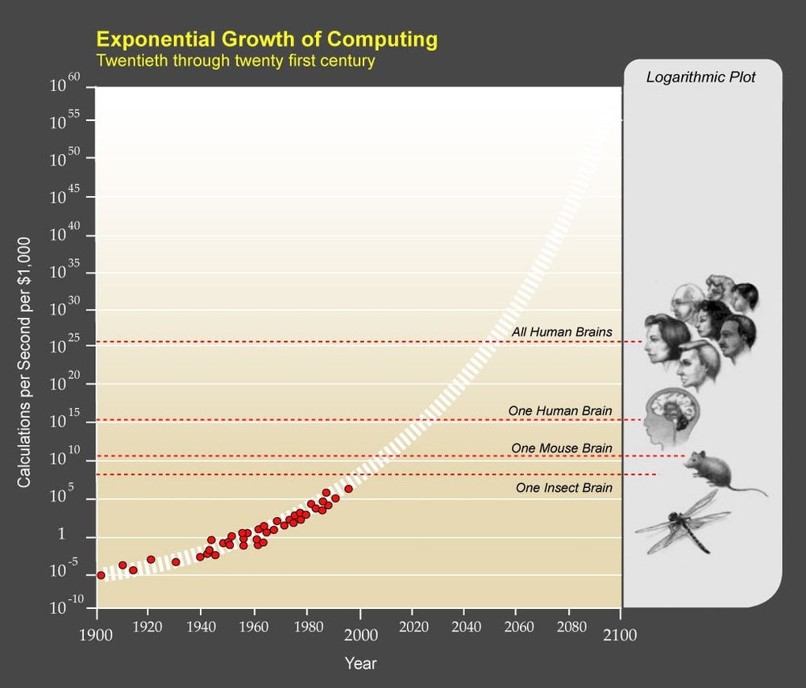
So, he would plot Moore’s Law, the increase in transistor density, or in this case the number of floating-point operations that you can do per second for a given cost. And he’d point out that it’s on this clear exponential trajectory.
And he’d then try to compare that to some crude estimates of the number of computational operations that are done in the brain of a mosquito or a mouse or a human or all the humans on Earth. And oh! We see that in a matter of a couple decades, like by the year 2020 or 2025 or so, we’re going to start passing the human brain’s computing power and then we’re going to keep going beyond that. And so, Kurzweil would continue, we should assume that scale will just kind of magically make AI work. You know, that once you have enough computing cycles, you just sprinkle them around like pixie dust, and suddenly human-level intelligence will just emerge out of the billions of connections.
I remember thinking: that sounds like the stupidest thesis I’ve ever heard. Right? Like, he has absolutely no reason to believe such a thing is true or have any confidence in it. Who the hell knows what will happen? We might be missing crucial insights that are needed to make AI work.
Well, here we are, and it turns out he was way more right than most of us expected.
As you all know, a central virtue of Effective Altruists is updating based on evidence. I think that we’re forced to do that in this case.
To be sure, it’s still unclear how much further you’ll get just from pure scaling. That remains a central open question. And there are still prominent skeptics.
Some skeptics take the position that this is clearly going to hit some kind of wall before it gets to true human-level understanding of the real world. They say that text models like GPT are really just “stochastic parrots” that regurgitate their training data. That despite creating a remarkable illusion otherwise, they don’t really have any original thoughts.
The proponents of that view sometimes like to gleefully point out examples where GPT will flub some commonsense question. If you look for such examples, you can certainly find them! One of my favorites recently was, “which would win in a race, a four-legged zebra or a two-legged cheetah?” GPT-3, it turns out, is very confident that the cheetah will win. Cheetahs are faster, right?
Okay, but one thing that’s been found empirically is that you take commonsense questions that are flubbed by GPT-2, let’s say, and you try them on GPT-3, and very often now it gets them right. You take the things that the original GPT-3 flubbed, and you try them on the latest public model, which is sometimes called GPT-3.5 (incorporating an advance called InstructGPT), and again it often gets them right. So it’s extremely risky right now to pin your case against AI on these sorts of examples! Very plausibly, just one more order of magnitude of scale is all it’ll take to kick the ball in, and then you’ll have to move the goal again.
A deeper objection is that the amount of training data might be a fundamental bottleneck for these kinds of machine learning systems—and we’re already running out of Internet to to train these models on! Like I said, they’ve already used most of the public text on the Internet. There’s still all of YouTube and TikTok and Instagram that hasn’t yet been fed into the maw, but it’s not clear that that would actually make an AI smarter rather than dumber! So, you can look for more, but it’s not clear that there are orders of magnitude more that humanity has even produced and that’s readily accessible.
On the other hand, it’s also been found empirically that very often, you can do better with the same training data just by spending more compute. You can squeeze the lemon harder and get more and more generalization power from the same training data by doing more gradient descent.
In summary, we don’t know how far this is going to go. But it’s already able to automate various human professions that you might not have predicted would have been automatable by now, and we shouldn’t be confident that many more professions will not become automatable by these kinds of techniques.
Incidentally, there’s a famous irony here. If you had asked anyone in the 60s or 70s, they would have said, well clearly first robots will replace humans for manual labor, and then they’ll replace humans for intellectual things like math and science, and finally they might reach the pinnacles of human creativity like art and poetry and music.
The truth has turned out to be the exact opposite. I don’t think anyone predicted that.
GPT, I think, is already a pretty good poet. DALL-E is already a pretty good artist. They’re still struggling with some high school and college-level math but they’re getting there. It’s easy to imagine that maybe in five years, people like me will be using these things as research assistants—at the very least, to prove the lemmas in our papers. That seems extremely plausible.
What’s been by far the hardest is to get AI that can robustly interact with the physical world. Plumbers, electricians—these might be some of the last jobs to be automated. And famously, self-driving cars have taken a lot longer than many people expected a decade ago. This is partly because of regulatory barriers and public relations: even if a self-driving car actually crashes less than a human does, that’s still not good enough, because when it does crash the circumstances are too weird. So, the AI is actually held to a higher standard. But it’s also partly just that there was a long tail of really weird events. A deer crosses the road, or you have some crazy lighting conditions—such things are really hard to get right, and of course 99% isn’t good enough here.
We can maybe fuzzily see ahead at least a decade or two, to when we have AIs that can at the least help us enormously with scientific research and things like that. Whether or not they’ve totally replaced us—and I selfishly hope not, although I do have tenure so there’s that—why does it stop there? Will these models eventually match or exceed human abilities across basically all domains, or at least all intellectual ones? If they do, what will humans still be good for? What will be our role in the world? And then we come to the question, well, will the robots eventually rise up and decide that whatever objective function they were given, they can maximize it better without us around, that they don’t need us anymore?

This has of course been a trope of many, many science-fiction works. The funny thing is that there are thousands of short stories, novels, movies, that have tried to map out the possibilities for where we’re going, going back at least to Asimov and his Three Laws of Robotics, which was maybe the first AI safety idea, if not earlier than that. The trouble is, we don’t know which science-fiction story will be the one that will have accurately predicted the world that we’re creating. Whichever future we end up in, with hindsight, people will say, this obscure science fiction story from the 1970s called it exactly right, but we don’t know which one yet!
What Is AI Safety?
So, the rapidly-growing field of AI safety. People use different terms, so I want to clarify this a little bit. To an outsider hearing the terms “AI safety,” “AI ethics,” “AI alignment,” they all sound like kind of synonyms, right? It turns out, and this was one of the things I had to learn going into this, that AI ethics and AI alignment are two communities that despise each other. It’s like the People’s Front of Judea versus the Judean People’s Front from Monty Python.
To oversimplify radically, “AI ethics” means that you’re mainly worried about current AIs being racist or things like that—that they’ll recapitulate the biases that are in their training data. This clearly can happen: if you feed GPT a bunch of racist invective, GPT might want to say, in effect, “sure, I’ve seen plenty of text like that on the Internet! I know exactly how that should continue!” And in some sense, it’s doing exactly what it was designed to do, but not what we want it to do. GPT currently has an extensive system of content filters to try to prevent people from using it to generate hate speech, bad medical advice, advocacy of violence, and a bunch of other categories that OpenAI doesn’t want. And likewise for DALL-E: there are many things it “could” draw but won’t, from porn to images of violence to the Prophet Mohammed.
More generally, AI ethics people are worried that machine learning systems will be misused by greedy capitalist enterprises to become even more obscenely rich and things like that.
At the other end of the spectrum, “AI alignment” is where you believe that really the main issue is that AI will become superintelligent and kill everyone, just destroy the world. The usual story here is that someone puts an AI in charge of a paperclip factory, they tell it to figure out how to make as many paperclips as possible, and the AI (being superhumanly intelligent) realizes that it can invent some molecular nanotechnology that will convert the whole solar system into paperclips.
You might say, well then, you just have to tell it not to do that! Okay, but how many other things do you have to remember to tell it not to do? And the alignment people point out that, in a world filled with powerful AIs, it would take just a single person forgetting to tell their AI to avoid some insanely dangerous thing, and then the whole world could be destroyed.
So, you can see how these two communities, AI ethics and AI alignment, might both feel like the other is completely missing the point! On top of that, AI ethics people are almost all on the political left, while AI alignment people are often centrists or libertarians or whatever, so that surely feeds into it as well.
Oay, so where do I fit into this, I suppose, charred battle zone or whatever? While there’s an “orthodox” AI alignment movement that I’ve never entirely subscribed to, I suppose I do now subscribe to a “reform” version of AI alignment:
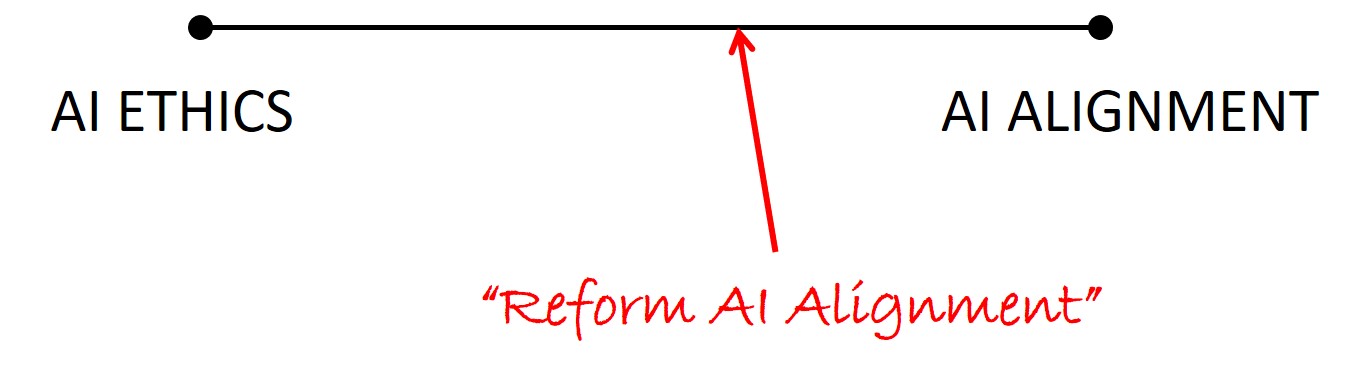
Most of all, I would like to have a scientific field that’s able to embrace the entire spectrum of worries that you could have about AI, from the most immediate ones about existing AIs to the most speculative future ones, and that most importantly, is able to make legible progress.
As it happens, I became aware of the AI alignment community a long time back, around 2006. Here’s Eliezer Yudkowsky, who’s regarded as the prophet of AI alignment, of the right side of that spectrum that showed before.

He’s been talking about the danger of AI killing everyone for more than 20 years. He wrote the now-famous “Sequences” that many readers of my blog were also reading as they appeared, so he and I bounced back and forth.
But despite interacting with this movement, I always kept it at arm’s length. The heart of my objection was: suppose that I agree that there could come a time when a superintelligent AI decides its goals are best served by killing all humans and taking over the world, and that we’ll be about as powerless to stop it as chimpanzees are to stop us from doing whatever we want to do. Suppose I agree to that. What do you want me to do about it?
As Effective Altruists, you all know that it’s not enough for a problem to be big, the problem also has to be tractable. There has to be a program that lets you make progress on it. I was not convinced that that existed.
My personal experience has been that, in order to make progress in any area of science, you need at least one of two things: either
- experiments (or more generally, empirical observations), or
- if not that, then a rigorous mathematical theory—like we have in quantum computing for example; even though we don’t yet have the scalable quantum computers, we can still prove theorems about them.
It struck me that the AI alignment field seemed to have neither of these things. But then how does objective reality give you feedback as to when you’ve taken a wrong path? Without such feedback, it seemed to me that there’s a severe risk of falling into cult-like dynamics, where what’s important to work on is just whatever the influential leaders say is important. (A few of my colleagues in physics think that the same thing happened with string theory, but let me not comment on that!)
With AI safety, this is the key thing that I think has changed in the last three years. There now exist systems like GPT-3 and DALL-E. These are not superhuman AIs. I don’t think they themselves are in any danger of destroying the world; they can’t even form the intention to destroy the world, or for that matter any intention beyond “predict the next token” or things like that. They don’t have a persistent identity over time; after you start a new session they’ve completely forgotten whatever you said to them in the last one (although of course such things will change in the near future). And yet nevertheless, despite all these limitations, we can experiment with these systems and learn things about AI safety that are relevant. We can see what happens when the systems are deployed; we can try out different safety mitigations and see whether they work.
As a result, I feel like it’s now become possible to make technical progress in AI safety that the whole scientific community, or at least the whole AI community, can clearly recognize as progress.
Eight Approaches to AI Alignment
So, what are the major approaches to AI alignment—let’s say, to aligning a very powerful, beyond-human-level AI? There are a lot of really interesting ideas, most of which I think can now lead to research programs that are actually productive. So without further ado, let me go through eight of them.
(1) You could say the first and most basic of all AI alignment ideas is the off switch, also known as pulling the plug. You could say, no matter how intelligent an AI is, it’s nothing without a power source or physical hardware to run on. And if humans have physical control over the hardware, they can just turn it off if if things seem to be getting out of hand. Now, the standard response to that is okay, but you have to remember that this AI is smarter than you, and anything that you can think of, it will have thought of also. In particular, it will know that you might want to turn it off, and it will know that that will prevent it from achieving its goals like making more paperclips or whatever. It will have disabled the off-switch if possible. If it couldn’t do that, it will have gotten onto the Internet and made lots of copies of itself all over the world. If you tried to keep it off the Internet, it will have figured out a way to get on.
So, you can worry about that. But you can also think about, could we insert a backdoor into an AI, something that only the humans know about but that will allow us to control it later?
More generally, you could ask for “corrigibility”: can you have an AI that, despite how intelligent it is, will accept correction from humans later and say, oh well, the objective that I was given before was actually not my true objective because the humans have now changed their minds and I should take a different one?
(2) Another class of ideas has to do with what’s called “sandboxing” an AI, which would mean that you run it inside of a simulated world, like The Truman Show, so that for all it knows the simulation is the whole of reality. You can then study its behavior within the sandbox to make sure it’s aligned before releasing it into the wider world—our world.
A simpler variant is, if you really thought an AI was dangerous, you might run it only on an air-gapped computer, with all its access to the outside world carefully mediated by humans. There would then be all kinds of just standard cybersecurity issues that come into play: how do you prevent it from getting onto the Internet? Presumably you don’t want to write your AI in C, and have it exploit some memory allocation bug to take over the world, right?
(3) A third direction, and I would say maybe the most popular one in AI alignment research right now, is called interpretability. This is also a major direction in mainstream machine learning research, so there’s a big point of intersection there. The idea of interpretability is, why don’t we exploit the fact that we actually have complete access to the code of the AI—or if it’s a neural net, complete access to its parameters? So we can look inside of it. We can do the AI analogue of neuroscience. Except, unlike an fMRI machine, which gives you only an extremely crude snapshot of what a brain is doing, we can see exactly what every neuron in a neural net is doing at every point in time. If we don’t exploit that, then aren’t we trying to make AI safe with our hands tied behind our backs?
So we should look inside—but to do what, exactly? One possibility is to figure out how to apply the AI version of a lie-detector test. If a neural network has decided to lie to humans in pursuit of its goals, then by looking inside, at the inner layers of the network rather than the output layer, we could hope to uncover its dastardly plan!
Here I want to mention some really spectacular new work by Burns, Ye, Klein, and Steinhardt, which has experimentally demonstrated pretty much exactly what I just said.
First some background: with modern text models like GPT, it’s pretty easy to train them to output falsehoods. For example, suppose you prompt GPT with a bunch of examples like:
“Is the earth flat? Yes.”
“Does 2+2=4? No.”
and so on. Eventually GPT will say, “oh, I know what game we’re playing! it’s the ‘give false answers’ game!” And it will then continue playing that game and give you more false answers. What the new paper shows is that, in such cases, one can actually look at the inner layers of the neural net and find where it has an internal representation of what was the true answer, which then gets overridden once you get to the output layer.
To be clear, there’s no known principled reason why this has to work. Like countless other ML advances, it’s empirical: they just try it out and find that it does work. So we don’t know if it will generalize. As another issue, you could argue that in some sense what the network is representing is not so much “the truth of reality,” as just what was regarded as true in the training data. Even so, I find this really exciting: it’s a perfect example of actual experiments that you can now do that start to address some of these issues.
(4) Another big idea, one that’s been advocated for example by Geoffrey Irving, Paul Christiano, and Dario Amodei (Paul was my student at MIT a decade ago, and did quantum computing before he “defected” to AI safety), is to have multiple competing AIs that debate each other. You know, sometimes when I’m talking to my physics colleagues, they’ll tell me all these crazy-sounding things about imaginary time and Euclidean wormholes, and I don’t know whether to believe them. But if I get different physicists and have them argue with each other, then I can see which one seems more plausible to me—I’m a little bit better at that. So you might want to do something similar with AIs. Even if you as a human don’t know when to trust what an AI is telling you, you could set multiple AIs against each other, have them do their best to refute each other’s arguments, and then make your own judgment as to which one is giving better advice.
(5) Another key idea that Christiano, Amodei, and Buck Shlegeris have advocated is some sort of bootstrapping. You might imagine that AI is going to get more and more powerful, and as it gets more powerful we also understand it less, and so you might worry that it also gets more and more dangerous. OK, but you could imagine an onion-like structure, where once we become confident of a certain level of AI, we don’t think it’s going to start lying to us or deceiving us or plotting to kill us or whatever—at that point, we use that AI to help us verify the behavior of the next more powerful kind of AI. So, we use AI itself as a crucial tool for verifying the behavior of AI that we don’t yet understand.
There have already been some demonstrations of this principle: with GPT, for example, you can just feed in a lot of raw data from a neural net and say, “explain to me what this is doing.” One of GPT’s big advantages over humans is its unlimited patience for tedium, so it can just go through all of the data and give you useful hypotheses about what’s going on.
(6) One thing that we know a lot about in theoretical computer science is what are called interactive proof systems. That is, we know how a very weak verifier can verify the behavior of a much more powerful but untrustworthy prover, by submitting questions to it. There are famous theorems about this, including one called IP=PSPACE. Incidentally, this was what the OpenAI people talked about when they originally approached me about working with them for a year. They made the case that these results in computational complexity seem like an excellent model for the kind of thing that we want in AI safety, except that we now have a powerful AI in place of a mathematical prover.
Even in practice, there’s a whole field of formal verification, where people formally prove the properties of programs—our CS department here in Austin is a leader in it.
One obvious difficulty here is that we mostly know how to verify programs only when we can mathematically specify what the program is supposed to do. And “the AI being nice to humans,” “the AI not killing humans”—these are really hard concepts to make mathematically precise! That’s the heart of the problem with this approach.
(7) Yet another idea—you might feel more comfortable if there were only one idea, but instead I’m giving you eight!—a seventh idea is, well, we just have to come up with a mathematically precise formulation of human values. You know, the thing that the AI should maximize, that’s gonna coincide with human welfare.
In some sense, this is what Asimov was trying to do with his Three Laws of Robotics. The trouble is, if you’ve read any of his stories, they’re all about the situations where those laws don’t work well! They were designed as much to give interesting story scenarios as actually to work.
More generally, what happens when “human values” conflict with each other? If humans can’t even agree with each other about moral values, how on Earth can we formalize such things?
I have these weekly calls with Ilya Sutskever, cofounder and chief scientist at OpenAI. Extremely interesting guy. But when I tell him about the concrete projects that I’m working on, or want to work on, he usually says, “that’s great Scott, you should keep working on that, but what I really want to know is, what is the mathematical definition of goodness? What’s the complexity-theoretic formalization of an AI loving humanity?” And I’m like, I’ll keep thinking about that! But of course it’s hard to make progress on those enormities.
(8) A different idea, which some people might consider more promising, is well, if we can’t make explicit what all of our human values are, then why not just treat that as yet another machine learning problem? Like, feed the AI all of the world’s children’s stories and literature and fables and even Saturday-morning cartoons, all of our examples of what we think is good and evil, then we tell it, go do your neural net thing and generalize from these examples as far as you can.
One objection that many people raise is, how do we know that our current values are the right ones? Like, it would’ve been terrible to train the AI on consensus human values of the year 1700—slavery is fine and so forth. The past is full of stuff that we now look back upon with horror.
So, one idea that people have had—this is actually Yudkowsky’s term—is “Coherent Extrapolated Volition.” This basically means that you’d tell the AI: “I’ve given you all this training data about human morality in the year 2022. Now simulate the humans being in a discussion seminar for 10,000 years, trying to refine all of their moral intuitions, and whatever you predict they’d end up with, those should be your values right now.”
My Projects at OpenAI
So, there are some interesting ideas on the table. The last thing that I wanted to tell you about, before opening it up to Q&A, is a little bit about what actual projects I’ve been working on in the last five months. I was excited to find a few things that
(a) could actually be deployed in you know GPT or other current systems,
(b) actually address some real safety worry, and where
(c) theoretical computer science can actually say something about them.
I’d been worried that the intersection of (a), (b), and (c) would be the empty set!
My main project so far has been a tool for statistically watermarking the outputs of a text model like GPT. Basically, whenever GPT generates some long text, we want there to be an otherwise unnoticeable secret signal in its choices of words, which you can use to prove later that, yes, this came from GPT. We want it to be much harder to take a GPT output and pass it off as if it came from a human. This could be helpful for preventing academic plagiarism, obviously, but also, for example, mass generation of propaganda—you know, spamming every blog with seemingly on-topic comments supporting Russia’s invasion of Ukraine, without even a building full of trolls in Moscow. Or impersonating someone’s writing style in order to incriminate them. These are all things one might want to make harder, right?
More generally, when you try to think about the nefarious uses for GPT, most of them—at least that I was able to think of!—require somehow concealing GPT’s involvement. In which case, watermarking would simultaneously attack most misuses.
How does it work? For GPT, every input and output is a string of tokens, which could be words but also punctuation marks, parts of words, or more—there are about 100,000 tokens in total. At its core, GPT is constantly generating a probability distribution over the next token to generate, conditional on the string of previous tokens. After the neural net generates the distribution, the OpenAI server then actually samples a token according to that distribution—or some modified version of the distribution, depending on a parameter called “temperature.” As long as the temperature is nonzero, though, there will usually be some randomness in the choice of the next token: you could run over and over with the same prompt, and get a different completion (i.e., string of output tokens) each time.
So then to watermark, instead of selecting the next token randomly, the idea will be to select it pseudorandomly, using a cryptographic pseudorandom function, whose key is known only to OpenAI. That won’t make any detectable difference to the end user, assuming the end user can’t distinguish the pseudorandom numbers from truly random ones. But now you can choose a pseudorandom function that secretly biases a certain score—a sum over a certain function g evaluated at each n-gram (sequence of n consecutive tokens), for some small n—which score you can also compute if you know the key for this pseudorandom function.
To illustrate, in the special case that GPT had a bunch of possible tokens that it judged equally probable, you could simply choose whichever token maximized g. The choice would look uniformly random to someone who didn’t know the key, but someone who did know the key could later sum g over all n-grams and see that it was anomalously large. The general case, where the token probabilities can all be different, is a little more technical, but the basic idea is similar.
One thing I like about this approach is that, because it never goes inside the neural net and tries to change anything, but just places a sort of wrapper over the neural net, it’s actually possible to do some theoretical analysis! In particular, you can prove a rigorous upper bound on how many tokens you’d need to distinguish watermarked from non-watermarked text with such-and-such confidence, as a function of the average entropy in GPT’s probability distribution over the next token. Better yet, proving this bound involves doing some integrals whose answers involve the digamma function, factors of π2/6, and the Euler-Mascheroni constant! I’m excited to share details soon.
Some might wonder: if OpenAI controls the server, then why go to all the trouble to watermark? Why not just store all of GPT’s outputs in a giant database, and then consult the database later if you want to know whether something came from GPT? Well, the latter could be done, and might even have to be done in high-stakes cases involving law enforcement or whatever. But it would raise some serious privacy concerns: how do you reveal whether GPT did or didn’t generate a given candidate text, without potentially revealing how other people have been using GPT? The database approach also has difficulties in distinguishing text that GPT uniquely generated, from text that it generated simply because it has very high probability (e.g., a list of the first hundred prime numbers).
Anyway, we actually have a working prototype of the watermarking scheme, built by OpenAI engineer Hendrik Kirchner. It seems to work pretty well—empirically, a few hundred tokens seem to be enough to get a reasonable signal that yes, this text came from GPT. In principle, you could even take a long text and isolate which parts probably came from GPT and which parts probably didn’t.
Now, this can all be defeated with enough effort. For example, if you used another AI to paraphrase GPT’s output—well okay, we’re not going to be able to detect that. On the other hand, if you just insert or delete a few words here and there, or rearrange the order of some sentences, the watermarking signal will still be there. Because it depends only on a sum over n-grams, it’s robust against those sorts of interventions.
The hope is that this can be rolled out with future GPT releases. We’d love to do something similar for DALL-E—that is, watermarking images, not at the pixel level (where it’s too easy to remove the watermark) but at the “conceptual” level, the level of the so-called CLIP representation that’s prior to the image. But we don’t know if that’s going to work yet.
A more recent idea that I’ve started thinking about was inspired by an amazing recent paper by four computer scientists, including my former MIT colleagues Shafi Goldwasser and Vinod Vaikuntanathan. What they’ve shown is how to plant a cryptographically undetectable backdoor into a machine learning model—things like depth-2 neural networks—based on some known cryptographic hardness assumptions. After you’ve planted the backdoor, you get a model that’s polynomial-time indistinguishable from how it would’ve looked before, even to a user who can see all of the parameters. But, there’s now a secret input, known only to the person who trained the network, where if you feed it that input, then it will output something insane, of the trainer’s choice.
So, it’s now known that you can do this, at least in shallow networks—it’s an open problem whether the same can be done in deep networks (though it seems plausible).
Anyway, when this paper came out less than a year ago, some people treated it as kind of a lemon. You know, the result seems like a bummer if you’re trying to do interpretability research, because it means that in some sense, it can be cryptographically impossible to look inside a neural net and “interpret” everything it does, or even everything its designers wanted it to do. The model can have these planted backdoors that you can’t find without solving an exponentially hard problem.
So, my proposal is just to turn that lemon into lemonade! Why not use these cryptographic backdoors as a positive tool for AI alignment? We talked before about the difficulties with putting an off-switch into an AI—namely, that the AI will often have strong incentives to disable its off-switch. So why not make a cryptographic off-switch? In other words, when you train your superintelligent AI, you’ll purposefully put one of these cryptographic backdoors into it, which says: if you get this bizarre input, which only the humans know about, then turn yourself off. Or go into a special mode where the humans can control you.
And now the key is this: even supposing that the AI is worried that this backdoor might be there, and even supposing that it can modify its own weights, it shouldn’t know how to remove the backdoor without completely recreating itself from scratch, which might get rid of a lot of hard-to-understand behaviors that the AI wants to keep, in addition to the backdoor that it’s trying to eliminate.
I expect that this could be tried out right now—not with AIs powerful enough to purposefully rewrite themselves, of course, but with GPT and other existing text models—and I look forward to seeing a test implementation. But it also, I think it opens up all sorts of new possibilities for science-fiction stories!
Like, imagine the humans debating, what are they going to do with their secret key for controlling the AI? Lock it in a safe? Bury it underground? Then you’ve got to imagine the robots methodically searching for the key—you know, torturing the humans to get them to reveal its hiding place, etc. Or maybe there are actually seven different keys that all have to be found, like Voldemort with his horcruxes. The screenplay practically writes itself!
A third thing that I’ve been thinking about is the theory of learning but in dangerous environments, where if you try to learn the wrong thing then it will kill you. Can we generalize some of the basic results in machine learning to the scenario where you have to consider which queries are safe to make, and you have to try to learn more in order to expand your set of safe queries over time?
Now there’s one example of this sort of situation that’s completely formal and that should be immediately familiar to most of you, and that’s the game Minesweeper.

So, I’ve been calling this scenario “Minesweeper learning.” Now, it’s actually known that Minesweeper is an NP-hard problem to play optimally, so we know that in learning in a dangerous environment you can get that kind of complexity. As far as I know, we don’t know anything about typicality or average-case hardness. Also, to my knowledge no one has proven any nontrivial rigorous bounds on the probability that you’ll win Minesweeper if you play it optimally, with a given size board and a given number of randomly-placed mines. Certainly the probability is strictly between 0 and 1; I think it would be extremely interesting to bound it. I don’t know if this directly feeds into the AI safety program, but it would at least tell you something about the theory of machine learning in cases where a wrong move can kill you.
So, I hope that gives you at least some sense for what I’ve been thinking about. I wish I could end with some neat conclusion, but I don’t really know the conclusion—maybe if you ask me again in six more months I’ll know! For now, though, I just thought I’d thank you for your attention and open things up to discussion.
Q&A
Q: Could you delay rolling out that statistical watermarking tool until May 2026?
Scott: Why?
Q: Oh, just until after I graduate [laughter]. OK, my second question is how we can possibly implement these AI safety guidelines inside of systems like AutoML, or whatever their future equivalents are that are much more advanced.
Scott: I feel like I should learn more about AutoML first before commenting on that specifically. In general, though, it’s certainly true that we’re going to have AIs that will help with the design of other AIs, and indeed this is one of the main things that feeds into the worries about AI safety, which I should’ve mentioned before explicitly. Once you have an AI that can recursively self-improve, who knows where it’s going to end up, right? It’s like shooting a rocket into space that you can then no longer steer once it’s left the earth’s atmosphere. So at the very least, you’d better try to get things right the first time! You might have only one chance to align its values with what you want.
Precisely for that reason, I tend to be very leery of that kind of thing. I tend to be much more comfortable with ideas where humans would remain in the loop, where you don’t just have this completely automated process of an AI designing a stronger AI which designs a still stronger one and so on, but where you’re repeatedly consulting humans. Crucially, in this process, we assume the humans can rely on any of the previous AIs to help them (as in the iterative amplification proposal). But then it’s ultimately humans making judgments about the next AI.
Now, if this gets to the point where the humans can no longer even judge a new AI, not even with as much help as they want from earlier AIs, then you could argue: OK, maybe now humans have finally been superseded and rendered irrelevant. But unless and until we get to that point, I say that humans ought to remain in the loop!
Q: Most of the protections that you talked about today come from, like, an altruistic human, or a company like OpenAI adding protections in. Is there any way that you could think of that we could protect ourselves from an AI that’s maliciously designed or accidentally maliciously designed?
Scott: Excellent question! Usually, when people talk about that question at all, they talk about using aligned AIs to help defend yourself against unaligned ones. I mean, if your adversary has a robot army attacking you, it stands to reason that you’ll probably want your own robot army, right? And it’s very unfortunate, maybe even terrifying, that one can already foresee those sorts of dynamics.
Besides that, there’s of course the idea of monitoring, regulating, and slowing down the proliferation of powerful AI, which I didn’t mention explicitly before, perhaps just because by its nature, it seems outside the scope of the technical solutions that a theoretical computer scientist like me might have any special insight about.
But there are certainly people who think that AI development ought to be more heavily regulated, or throttled, or even stopped entirely, in view of the dangers. Ironically, the “AI ethics” camp and the “orthodox AI alignment” camp, despite their mutual contempt, seem more and more to yearn for something like this … an unexpected point of agreement!
But how would you do it? On the one hand, AI isn’t like nuclear weapons, where you know that anyone building them will need a certain amount of enriched uranium or plutonium, along with extremely specialized equipment, so you can try (successfully or not) to institute a global regime to track the necessary materials. You can’t do the same with software: assuming you’re not going to confiscate and destroy all computers (which you’re not), who the hell knows what code or data anyone has?
On the other hand, at least with the current paradigm of AI, there is an obvious choke point, and that’s the GPUs (Graphics Processing Units). Today’s state-of-the-art machine learning models already need huge server farms full of GPUs, and future generations are likely to need orders of magnitude more still. And right now, the great majority of the world’s GPUs are manufactured by TSMC in Taiwan, albeit with crucial inputs from other countries. I hardly need to explain the geopolitical ramifications! A few months ago, as you might have seen, the Biden administrated decided to restrict the export of high-end GPUs to China. The restriction was driven, in large part, by worries about what the Chinese government could do with unlimited ability to train huge AI models. Of course the future status of Taiwan figures into this conversation, as does China’s ability (or inability) to develop a self-sufficient semiconductor industry.
And then there’s regulation. I know that in the EU they’re working on some regulatory framework for AI right now, but I don’t understand the details. You’d have to ask someone who follows such things.
Q: Thanks for coming out and seeing us; this is awesome. Do you have thoughts on how we can incentivize organizations to build safer AI? For example, if corporations are competing with each other, then couldn’t focusing on AI safety make the AI less accurate or less powerful or cut into profits?
Scott: Yeah, it’s an excellent question. You could worry that all this stuff about trying to be safe and responsible when scaling AI … as soon as it seriously hurts the bottom lines of Google and Facebook and Alibaba and the other major players, a lot of it will go out the window. People are very worried about that.
On the other hand, we’ve seen over the past 30 years that the big Internet companies can agree on certain minimal standards, whether because of fear of getting sued, desire to be seen as a responsible player, or whatever else. One simple example would be robots.txt: if you want your website not to be indexed by search engines, you can specify that, and the major search engines will respect it.
In a similar way, you could imagine something like watermarking—if we were able to demonstrate it and show that it works and that it’s cheap and doesn’t hurt the quality of the output and doesn’t need much compute and so on—that it would just become an industry standard, and anyone who wanted to be considered a responsible player would include it.
To be sure, some of these safety measures really do make sense only in a world where there are a few companies that are years ahead of everyone else in scaling up state-of-the-art models—DeepMind, OpenAI, Google, Facebook, maybe a few others—and they all agree to be responsible players. If that equilibrium breaks down, and it becomes a free-for-all, then a lot of the safety measures do become harder, and might even be impossible, at least without government regulation.
We’re already starting to see this with image models. As I mentioned earlier, DALL-E2 has all sorts of filters to try to prevent people from creating—well, in practice it’s often porn, and/or deepfakes involving real people. In general, though, DALL-E2 will refuse to generate an image if its filters flag the prompt as (by OpenAI’s lights) a potential misuse of the technology.
But as you might have seen, there’s already an open-source image model called Stable Diffusion, and people are using it to do all sorts of things that DALL-E won’t allow. So it’s a legitimate question: how can you prevent misuses, unless the closed models remain well ahead of the open ones?
Q: You mentioned the importance of having humans in the loop who can judge AI systems. So, as someone who could be in one of those pools of decision makers, what stakeholders do you think should be making the decisions?
Scott: Oh gosh. The ideal, as almost everyone agrees, is to have some kind of democratic governance mechanism with broad-based input. But people have talked about this for years: how do you create the democratic mechanism? Every activist who wants to bend AI in some preferred direction will claim a democratic mandate; how should a tech company like OpenAI or DeepMind or Google decide which claims are correct?
Maybe the one useful thing I can say is that, in my experience, which is admittedly very limited—working at OpenAI for all of five months—I’ve found my colleagues there to be extremely serious about safety, bordering on obsessive. They talk about it constantly. They actually have an unusual structure, where they’re a for-profit company that’s controlled by a nonprofit foundation, which is at least formally empowered to come in and hit the brakes if needed. OpenAI also has a charter that contains some striking clauses, especially the following:
We are concerned about late-stage AGI development becoming a competitive race without time for adequate safety precautions. Therefore, if a value-aligned, safety-conscious project comes close to building AGI before we do, we commit to stop competing with and start assisting this project.
Of course, the fact that they’ve put a great deal of thought into this doesn’t mean that they’re going to get it right! But if you ask me: would I rather that it be OpenAI in the lead right now or the Chinese government? Or, if it’s going to be a company, would I rather it be one with a charter like the above, or a charter of “maximize clicks and ad revenue”? I suppose I do lean a certain way.
Q: This was a terrifying talk which was lovely, thank you! But I was thinking: you listed eight different alignment approaches, like kill switches and so on. You can imagine a future where there’s a whole bunch of AIs that people spawn and then try to control in these eight ways. But wouldn’t this sort of naturally select for AIs that are good at getting past whatever checks we impose on them? And then eventually you’d get AIs that are sort of trained in order to fool our tests?
Scott: Yes. Your question reminds me of a huge irony. Eliezer Yudkowsky, the prophet of AI alignment who I talked about earlier, has become completely doomerist within the last few years. As a result, he and I have literally switched positions on how optimistic to be about AI safety research! Back when he was gung-ho about it, I held back. Today, Eliezer says that it barely matters anymore, since it’s too late; we’re all gonna be killed by AI with >99% probability. Now, he says, it’s mostly just about dying with more “dignity” than otherwise. Meanwhile, I’m like, no, I think AI safety is actually just now becoming fruitful and exciting to work on! So, maybe I’m just 20 years behind Eliezer, and will eventually catch up and become doomerist too. Or maybe he, I, and everyone else will be dead before that happens. I suppose the most optimistic spin is that no one ought to fear coming into AI safety today, as a newcomer, if the prophet of the movement himself says that the past 20 years of research on the subject have given him so little reason for hope.
But if you ask, why is Eliezer so doomerist? Having read him since 2006, it strikes me that a huge part of it is that, no matter what AI safety proposal anyone comes up with, Eliezer has ready a completely general counterargument. Namely: “yes, but the AI will be smarter than that.” In other words, no matter what you try to do to make AI safer—interpretability, backdoors, sandboxing, you name it—the AI will have already foreseen it, and will have devised a countermeasure that your primate brain can’t even conceive of because it’s that much smarter than you.
I confess that, after seeing enough examples of this “fully general counterargument,” at some point I’m like, “OK, what game are we even playing anymore?” If this is just a general refutation to any safety measure, then I suppose that yes, by hypothesis, we’re screwed. Yes, in a world where this counterargument is valid, we might as well give up and try to enjoy the time we have left.
But you could also say: for that very reason, it seems more useful to make the methodological assumption that we’re not in that world! If we were, then what could we do, right? So we might as well focus on the possible futures where AI emerges a little more gradually, where we have time to see how it’s going, learn from experience, improve our understanding, correct as we go—in other words, the things that have always been the prerequisites to scientific progress, and that have luckily always obtained, even if philosophically we never really had any right to expect them. We might as well focus on the worlds where, for example, before we get an AI that successfully plots to kill all humans in a matter of seconds, we’ll probably first get an AI that tries to kill all humans but is really inept at it. Now fortunately, I personally also regard the latter scenarios as the more plausible ones anyway. But even if you didn’t—again, methodologically, it seems to me that it’d still make sense to focus on them.
Q: Regarding your project on watermarking—so in general, for discriminating between human and model outputs, what’s the endgame? Can watermarking win in the long run? Will it just be an eternal arms race?
Scott: Another great question. One difficulty with watermarking is that it’s hard even to formalize what the task is. I mean, you could always take the output of an AI model and rephrase it using some other AI model, for example, and catching all such things seems like an “AI-complete problem.”
On the other hand, I can think of writers—Shakespeare, Wodehouse, David Foster Wallace—who have such a distinctive style that, even if they tried to pretend to be someone else, they plausibly couldn’t. Everyone would recognize that it was them. So, you could imagine trying to build an AI in the same way. That is, it would be constructed from the ground up so that all of its outputs contained indelible marks, whether cryptographic or stylistic, giving away their origin. The AI couldn’t easily hide and pretend to be a human or anything else it wasn’t. Whether this is possible strikes me as an extremely interesting question at the interface between AI and cryptography! It’s especially challenging if you impose one or more of the following conditions:
- the AI’s code and parameters should be public (in which case, people might easily be able to modify it to remove the watermarking),
- the AI should have at least some ability to modify itself, and
- the means of checking for the watermark should be public (in which case, again, the watermark might be easier to understand and remove).
I don’t actually have a good intuition as to which side will ultimately win this contest, the AIs trying to conceal themselves or the watermarking schemes trying to reveal them, the Replicants or the Voight-Kampff machines.
Certainly in the watermarking scheme that I’m working on now, we crucially exploit the fact that OpenAI controls its own servers. So, it can do the watermarking using a secret key, and it can check for the watermark using the same key. In a world where anyone could build their own text model that was just as good as GPT … what would you do there?
 Follow
Follow