Last weekend, I gave a talk on big numbers, as well as a Q&A about quantum computing, at Festivaletteratura: one of the main European literary festivals, held every year in beautiful and historic Mantua, Italy. (For those who didn’t know, as I didn’t: this is the city where Virgil was born, and where Romeo gets banished in Romeo and Juliet. Its layout hasn’t substantially changed since the Middle Ages.)
I don’t know how much big numbers or quantum computing have to do with literature, but I relished the challenge of explaining these things to an audience that was not merely “popular” but humanisitically rather than scientifically inclined. In this case, there was not only a math barrier, but also a language barrier, as the festival was mostly in Italian and only some of the attendees knew English, to varying degrees. The quantum computing session was live-translated into Italian (the challenge faced by the translator in not mangling this material provided a lot of free humor), but the big numbers talk wasn’t. What’s more, the talk was held outdoors, on the steps of a cathedral, with tons of background noise, including a bell that loudly chimed halfway through the talk. So if my own words weren’t simple and clear, forget it.
Anyway, in the rest of this post, I’ll share a writeup of my big numbers talk. The talk has substantial overlap with my “classic” Who Can Name The Bigger Number? essay from 1999. While I don’t mean to supersede or displace that essay, the truth is that I think and write somewhat differently than I did as a teenager (whuda thunk?), and I wanted to give Scott2017 a crack at material that Scott1999 has been over already. If nothing else, the new version is more up-to-date and less self-indulgent, and it includes points (for example, the relation between ordinal generalizations of the Busy Beaver function and the axioms of set theory) that I didn’t understand back in 1999.
For regular readers of this blog, I don’t know how much will be new here. But if you’re one of those people who keeps introducing themselves at social events by saying “I really love your blog, Scott, even though I don’t understand anything that’s in it”—something that’s always a bit awkward for me, because, uh, thanks, I guess, but what am I supposed to say next?—then this lecture is for you. I hope you’ll read it and understand it.
Thanks so much to Festivaletteratura organizer Matteo Polettini for inviting me, and to Fabrizio Illuminati for moderating the Q&A. I had a wonderful time in Mantua, although I confess there’s something about being Italian that I don’t understand. Namely: how do you derive any pleasure from international travel, if anywhere you go, the pizza, pasta, bread, cheese, ice cream, coffee, architecture, scenery, historical sights, and pretty much everything else all fall short of what you’re used to?
Big Numbers
by Scott Aaronson
Sept. 9, 2017
My four-year-old daughter sometimes comes to me and says something like: “daddy, I think I finally figured out what the biggest number is! Is it a million million million million million million million million thousand thousand thousand hundred hundred hundred hundred twenty eighty ninety eighty thirty a million?”
So I reply, “I’m not even sure exactly what number you named—but whatever it is, why not that number plus one?”
“Oh yeah,” she says. “So is that the biggest number?”
Of course there’s no biggest number, but it’s natural to wonder what are the biggest numbers we can name in a reasonable amount of time. Can I have two volunteers from the audience—ideally, two kids who like math?
[Two kids eventually come up. I draw a line down the middle of the blackboard, and place one kid on each side of it, each with a piece of chalk.]
So the game is, you each have ten seconds to write down the biggest number you can. You can’t write anything like “the other person’s number plus 1,” and you also can’t write infinity—it has to be finite. But other than that, you can write basically anything you want, as long as I’m able to understand exactly what number you’ve named. [These instructions are translated into Italian for the kids.]
Are you ready? On your mark, get set, GO!
[The kid on the left writes something like: 999999999
While the kid on the right writes something like: 11111111111111111
Looking at these, I comment:]
9 is bigger than 1, but 1 is a bit faster to write, and as you can see that makes the difference here! OK, let’s give our volunteers a round of applause.
[I didn’t plant the kids, but if I had, I couldn’t have designed a better jumping-off point.]
I’ve been fascinated by how to name huge numbers since I was a kid myself. When I was a teenager, I even wrote an essay on the subject, called Who Can Name the Bigger Number? That essay might still get more views than any of the research I’ve done in all the years since! I don’t know whether to be happy or sad about that.
I think the reason the essay remains so popular, is that it shows up on Google whenever someone types something like “what is the biggest number?” Some of you might know that Google itself was named after the huge number called a googol: 10100, or 1 followed by a hundred zeroes.
Of course, a googol isn’t even close to the biggest number we can name. For starters, there’s a googolplex, which is 1 followed by a googol zeroes. Then there’s a googolplexplex, which is 1 followed by a googolplex zeroes, and a googolplexplexplex, and so on. But one of the most basic lessons you’ll learn in this talk is that, when it comes to naming big numbers, whenever you find yourself just repeating the same operation over and over and over, it’s time to step back, and look for something new to do that transcends everything you were doing previously. (Applications to everyday life left as exercises for the listener.)
One of the first people to think about systems for naming huge numbers was Archimedes, who was Greek but lived in what’s now Italy (specifically Syracuse, Sicily) in the 200s BC. Archimedes wrote a sort of pop-science article—possibly history’s first pop-science article—called The Sand-Reckoner. In this remarkable piece, which was addressed to the King of Syracuse, Archimedes sets out to calculate an upper bound on the number of grains of sand needed to fill the entire universe, or at least the universe as known in antiquity. He thereby seeks to refute people who use “the number of sand grains” as a shorthand for uncountability and unknowability.
Of course, Archimedes was just guessing about the size of the universe, though he did use the best astronomy available in his time—namely, the work of Aristarchus, who anticipated Copernicus. Besides estimates for the size of the universe and of a sand grain, the other thing Archimedes needed was a way to name arbitrarily large numbers. Since he didn’t have Arabic numerals or scientific notation, his system was basically just to compose the word “myriad” (which means 10,000) into bigger and bigger chunks: a “myriad myriad” gets its own name, a “myriad myriad myriad” gets another, and so on. Using this system, Archimedes estimated that ~1063 sand grains would suffice to fill the universe. Ancient Hindu mathematicians were able to name similarly large numbers using similar notations. In some sense, the next really fundamental advances in naming big numbers wouldn’t occur until the 20th century.
We’ll come to those advances, but before we do, I’d like to discuss another question that motivated Archimedes’ essay: namely, what are the biggest numbers relevant to the physical world?
For starters, how many atoms are in a human body? Anyone have a guess? About 1028. (If you remember from high-school chemistry that a “mole” is 6×1023, this is not hard to ballpark.)
How many stars are in our galaxy? Estimates vary, but let’s say a few hundred billion.
How many stars are in the entire observable universe? Something like 1023.
How many subatomic particles are in the observable universe? No one knows for sure—for one thing, because we don’t know what the dark matter is made of—but 1090 is a reasonable estimate.
Some of you might be wondering: but for all anyone knows, couldn’t the universe be infinite? Couldn’t it have infinitely many stars and particles? The answer to that is interesting: indeed, no one knows whether space goes on forever or curves back on itself, like the surface of the earth. But because of the dark energy, discovered in 1998, it seems likely that even if space is infinite, we can only ever see a finite part of it. The dark energy is a force that pushes the galaxies apart. The further away they are from us, the faster they’re receding—with galaxies far enough away from us receding faster than light.
Right now, we can see the light from galaxies that are up to about 45 billion light-years away. (Why 45 billion light-years, you ask, if the universe itself is “only” 13.6 billion years old? Well, when the galaxies emitted the light, they were a lot closer to us than they are now! The universe expanded in the meantime.) If, as seems likely, the dark energy has the form of a cosmological constant, then there’s a somewhat further horizon, such that it’s not just that the galaxies beyond that can’t be seen by us right now—it’s that they can never be seen.
In practice, many big numbers come from the phenomenon of exponential growth. Here’s a graph showing the three functions n, n2, and 2n:
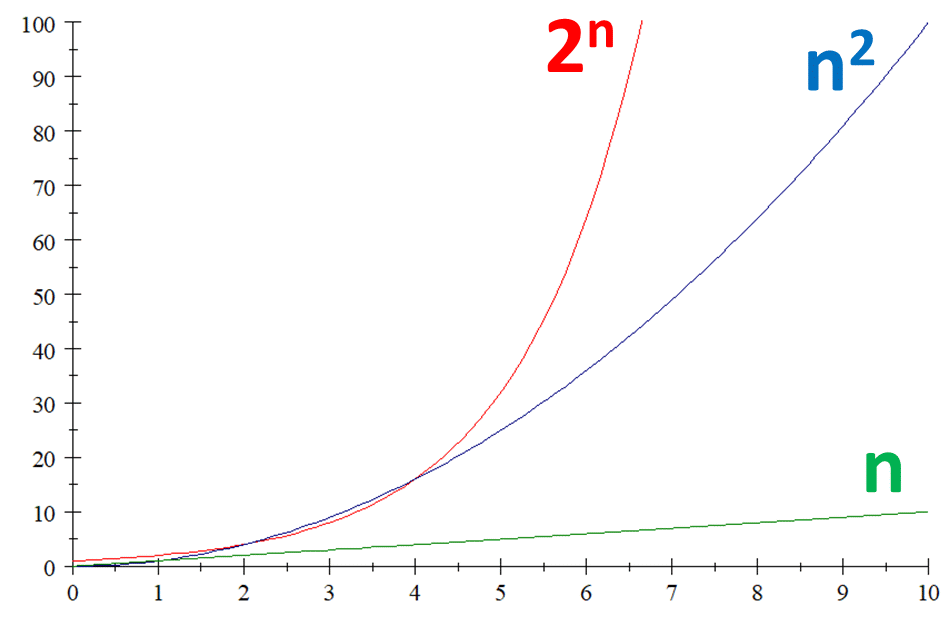
The difference is, n and even n2 grow in a more-or-less manageable way, but 2n just shoots up off the screen. The shooting-up has real-life consequences—indeed, more important consequences than just about any other mathematical fact one can think of.
The current human population is about 7.5 billion (when I was a kid, it was more like 5 billion). Right now, the population is doubling about once every 64 years. If it continues to double at that rate, and humans don’t colonize other worlds, then you can calculate that, less than 3000 years from now, the entire earth, all the way down to the core, will be made of human flesh. I hope the people use deodorant!
Nuclear chain reactions are a second example of exponential growth: one uranium or plutonium nucleus fissions and emits neutrons that cause, let’s say, two other nuclei to fission, which then cause four nuclei to fission, then 8, 16, 32, and so on, until boom, you’ve got your nuclear weapon (or your nuclear reactor, if you do something to slow the process down). A third example is compound interest, as with your bank account, or for that matter an entire country’s GDP. A fourth example is Moore’s Law, which is the thing that said that the number of components in a microprocessor doubled every 18 months (with other metrics, like memory, processing speed, etc., on similar exponential trajectories). Here at Festivaletteratura, there’s a “Hack Space,” where you can see state-of-the-art Olivetti personal computers from around 1980: huge desk-sized machines with maybe 16K of usable RAM. Moore’s Law is the thing that took us from those (and the even bigger, weaker computers before them) to the smartphone that’s in your pocket.
However, a general rule is that any time we encounter exponential growth in our observed universe, it can’t last for long. It will stop, if not before then when it runs out of whatever resource it needs to continue: for example, food or land in the case of people, fuel in the case of a nuclear reaction. OK, but what about Moore’s Law: what physical constraint will stop it?
By some definitions, Moore’s Law has already stopped: computers aren’t getting that much faster in terms of clock speed; they’re mostly just getting more and more parallel, with more and more cores on a chip. And it’s easy to see why: the speed of light is finite, which means the speed of a computer will always be limited by the size of its components. And transistors are now just 15 nanometers across; a couple orders of magnitude smaller and you’ll be dealing with individual atoms. And unless we leap really far into science fiction, it’s hard to imagine building a transistor smaller than one atom across!
OK, but what if we do leap really far into science fiction? Forget about engineering difficulties: is there any fundamental principle of physics that prevents us from making components smaller and smaller, and thereby making our computers faster and faster, without limit?
While no one has tested this directly, it appears from current physics that there is a fundamental limit to speed, and that it’s about 1043 operations per second, or one operation per Planck time. Likewise, it appears that there’s a fundamental limit to the density with which information can be stored, and that it’s about 1069 bits per square meter, or one bit per Planck area. (Surprisingly, the latter limit scales only with the surface area of a region, not with its volume.)
What would happen if you tried to build a faster computer than that, or a denser hard drive? The answer is: cycling through that many different states per second, or storing that many bits, would involve concentrating so much energy in so small a region, that the region would exceed what’s called its Schwarzschild radius. If you don’t know what that means, it’s just a fancy way of saying that your computer would collapse to a black hole. I’ve always liked that as Nature’s way of telling you not to do something!
Note that, on the modern view, a black hole itself is not only the densest possible object allowed by physics, but also the most efficient possible hard drive, storing ~1069 bits per square meter of its event horizon—though the bits are not so easy to retrieve! It’s also, in a certain sense, the fastest possible computer, since it really does cycle through 1043 states per second—though it might not be computing anything that anyone would care about.
We can also combine these fundamental limits on computer speed and storage capacity, with the limits that I mentioned earlier on the size of the observable universe, which come from the cosmological constant. If we do so, we get an upper bound of ~10122 on the number of bits that can ever be involved in any computation in our world, no matter how large: if we tried to do a bigger computation than that, the far parts of it would be receding away from us faster than the speed of light. In some sense, this 10122 is the most fundamental number that sets the scale of our universe: on the current conception of physics, everything you’ve ever seen or done, or will see or will do, can be represented by a sequence of at most 10122 ones and zeroes.
Having said that, in math, computer science, and many other fields (including physics itself), many of us meet bigger numbers than 10122 dozens of times before breakfast! How so? Mostly because we choose to ask, not about the number of things that are, but about the number of possible ways they could be—not about the size of ordinary 3-dimensional space, but the sizes of abstract spaces of possible configurations. And the latter are subject to exponential growth, continuing way beyond 10122.
As an example, let’s ask: how many different novels could possibly be written (say, at most 400 pages long, with a normal-size font, yadda yadda)? Well, we could get a lower bound on the number just by walking around here at Festivaletteratura, but the number that could be written certainly far exceeds the number that have been written or ever will be. This was the subject of Jorge Luis Borges’ famous story The Library of Babel, which imagined an immense library containing every book that could possibly be written up to a certain length. Of course, the vast majority of the books are filled with meaningless nonsense, but among their number one can find all the great works of literature, books predicting the future of humanity in perfect detail, books predicting the future except with a single error, etc. etc. etc.
To get more quantitative, let’s simply ask: how many different ways are there to fill the first page of a novel? Let’s go ahead and assume that the page is filled with intelligible (or at least grammatical) English text, rather than arbitrary sequences of symbols, at a standard font size and page size. In that case, using standard estimates for the entropy (i.e., compressibility) of English, I estimated this morning that there are maybe ~10700 possibilities. So, forget about the rest of the novel: there are astronomically more possible first pages than could fit in the observable universe!
We could likewise ask: how many chess games could be played? I’ve seen estimates from 1040 up to 10120, depending on whether we count only “sensible” games or also “absurd” ones (though in all cases, with a limit on the length of the game as might occur in a real competition). For Go, by contrast, which is played on a larger board (19×19 rather than 8×8) the estimates for the number of possible games seem to start at 10800 and only increase from there. This difference in magnitudes has something to do with why Go is a “harder” game than chess, why computers were able to beat the world chess champion already in 1997, but the world Go champion not until last year.
Or we could ask: given a thousand cities, how many routes are there for a salesman that visit each city exactly once? We write the answer as 1000!, pronounced “1000 factorial,” which just means 1000×999×998×…×2×1: there are 1000 choices for the first city, then 999 for the second city, 998 for the third, and so on. This number is about 4×102567. So again, more possible routes than atoms in the visible universe, yadda yadda.
But suppose the salesman is interested only in the shortest route that visits each city, given the distance between every city and every other. We could then ask: to find that shortest route, would a computer need to search exhaustively through all 1000! possibilities—or, maybe not all 1000!, maybe it could be a bit more clever than that, but at any rate, a number that grew exponentially with the number of cities n? Or could there be an algorithm that zeroed in on the shortest route dramatically faster: say, using a number of steps that grew only linearly or quadratically with the number of cities?
This, modulo a few details, is one of the most famous unsolved problems in all of math and science. You may have heard of it; it’s called P versus NP. P (Polynomial-Time) is the class of problems that an ordinary digital computer can solve in a “reasonable” amount of time, where we define “reasonable” to mean, growing at most like the size of the problem (for example, the number of cities) raised to some fixed power. NP (Nondeterministic Polynomial-Time) is the class for which a computer can at least recognize a solution in polynomial-time. If P=NP, it would mean that for every combinatorial problem of this sort, for which a computer could recognize a valid solution—Sudoku puzzles, scheduling airline flights, fitting boxes into the trunk of a car, etc. etc.—there would be an algorithm that cut through the combinatorial explosion of possible solutions, and zeroed in on the best one. If P≠NP, it would mean that at least some problems of this kind required astronomical time, regardless of how cleverly we programmed our computers.
Most of us believe that P≠NP—indeed, I like to say that if we were physicists, we would’ve simply declared P≠NP a “law of nature,” and given ourselves Nobel Prizes for the discovery of the law! And if it turned out that P=NP, we’d just give ourselves more Nobel Prizes for the law’s overthrow. But because we’re mathematicians and computer scientists, we call it a “conjecture.”
Another famous example of an NP problem is: I give you (say) a 2000-digit number, and I ask you to find its prime factors. Multiplying two thousand-digit numbers is easy, at least for a computer, but factoring the product back into primes seems astronomically hard—at least, with our present-day computers running any known algorithm. Why does anyone care? Well, you might know that, any time you order something online—in fact, every time you see a little padlock icon in your web browser—your personal information, like (say) your credit card number, is being protected by a cryptographic code that depends on the belief that factoring huge numbers is hard, or a few closely-related beliefs. If P=NP, then those beliefs would be false, and indeed all cryptography that depends on hard math problems would be breakable in “reasonable” amounts of time.
In the special case of factoring, though—and of the other number theory problems that underlie modern cryptography—it wouldn’t even take anything as shocking as P=NP for them to fall. Actually, that provides a good segue into another case where exponentials, and numbers vastly larger than 10122, regularly arise in the real world: quantum mechanics.
Some of you might have heard that quantum mechanics is complicated or hard. But I can let you in on a secret, which is that it’s incredibly simple once you take the physics out of it! Indeed, I think of quantum mechanics as not exactly even “physics,” but more like an operating system that the rest of physics runs on as application programs. It’s a certain generalization of the rules of probability. In one sentence, the central thing quantum mechanics says is that, to fully describe a physical system, you have to assign a number called an “amplitude” to every possible configuration that the system could be found in. These amplitudes are used to calculate the probabilities that the system will be found in one configuration or another if you look at it. But the amplitudes aren’t themselves probabilities: rather than just going from 0 to 1, they can be positive or negative or even complex numbers.
For us, the key point is that, if we have a system with (say) a thousand interacting particles, then the rules of quantum mechanics say we need at least 21000 amplitudes to describe it—which is way more than we could write down on pieces of paper filling the entire observable universe! In some sense, chemists and physicists knew about this immensity since 1926. But they knew it mainly as a practical problem: if you’re trying to simulate quantum mechanics on a conventional computer, then as far as we know, the resources needed to do so increase exponentially with the number of particles being simulated. Only in the 1980s did a few physicists, such as Richard Feynman and David Deutsch, suggest “turning the lemon into lemonade,” and building computers that themselves would exploit the exponential growth of amplitudes. Supposing we built such a computer, what would it be good for? At the time, the only obvious application was simulating quantum mechanics itself! And that’s probably still the most important application today.
In 1994, though, a guy named Peter Shor made a discovery that dramatically increased the level of interest in quantum computers. That discovery was that a quantum computer, if built, could factor an n-digit number using a number of steps that grows only like about n2, rather than exponentially with n. The upshot is that, if and when practical quantum computers are built, they’ll be able to break almost all the cryptography that’s currently used to secure the Internet.
(Right now, only small quantum computers have been built; the record for using Shor’s algorithm is still to factor 21 into 3×7 with high statistical confidence! But Google is planning within the next year or so to build a chip with 49 quantum bits, or qubits, and other groups around the world are pursuing parallel efforts. Almost certainly, 49 qubits still won’t be enough to do anything useful, including codebreaking, but it might be enough to do something classically hard, in the sense of taking at least ~249 or 563 trillion steps to simulate classically.)
I should stress, though, that for other NP problems—including breaking various other cryptographic codes, and solving the Traveling Salesman Problem, Sudoku, and the other combinatorial problems mentioned earlier—we don’t know any quantum algorithm analogous to Shor’s factoring algorithm. For these problems, we generally think that a quantum computer could solve them in roughly the square root of the number of steps that would be needed classically, because of another famous quantum algorithm called Grover’s algorithm. But getting an exponential quantum speedup for these problems would, at the least, require an additional breakthrough. No one has proved that such a breakthrough in quantum algorithms is impossible: indeed, no one has proved that it’s impossible even for classical algorithms; that’s the P vs. NP question! But most of us regard it as unlikely.
If we’re right, then the upshot is that quantum computers are not magic bullets: they might yield dramatic speedups for certain special problems (like factoring), but they won’t tame the curse of exponentiality, cut through to the optimal solution, every time we encounter a Library-of-Babel-like profusion of possibilities. For (say) the Traveling Salesman Problem with a thousand cities, even a quantum computer—which is the most powerful kind of computer rooted in known laws of physics—might, for all we know, take longer than the age of the universe to find the shortest route.
The truth is, though, the biggest numbers that show up in math are way bigger than anything we’ve discussed until now: bigger than 10122, or even
$$ 2^{10^{122}}, $$
which is a rough estimate for the number of quantum-mechanical amplitudes needed to describe our observable universe.
For starters, there’s Skewes’ number, which the mathematician G. H. Hardy once called “the largest number which has ever served any definite purpose in mathematics.” Let π(x) be the number of prime numbers up to x: for example, π(10)=4, since we have 2, 3, 5, and 7. Then there’s a certain estimate for π(x) called li(x). It’s known that li(x) overestimates π(x) for an enormous range of x’s (up to trillions and beyond)—but then at some point, it crosses over and starts underestimating π(x) (then overestimates again, then underestimates, and so on). Skewes’ number is an upper bound on the location of the first such crossover point. In 1955, Skewes proved that the first crossover must happen before
$$ x = 10^{10^{10^{964}}}. $$
Note that this bound has since been substantially improved, to 1.4×10316. But no matter: there are numbers vastly bigger even than Skewes’ original estimate, which have since shown up in Ramsey theory and other parts of logic and combinatorics to take Skewes’ number’s place.
Alas, I won’t have time here to delve into specific (beautiful) examples of such numbers, such as Graham’s number. So in lieu of that, let me just tell you about the sorts of processes, going far beyond exponentiation, that tend to yield such numbers.
The starting point is to remember a sequence of operations we all learn about in elementary school, and then ask why the sequence suddenly and inexplicably stops.
As long as we’re only talking about positive integers, “multiplication” just means “repeated addition.” For example, 5×3 means 5 added to itself 3 times, or 5+5+5.
Likewise, “exponentiation” just means “repeated multiplication.” For example, 53 means 5×5×5.
But what’s repeated exponentiation? For that we introduce a new operation, which we call tetration, and write like so: 35 means 5 raised to itself 3 times, or
$$ ^{3} 5 = 5^{5^5} = 5^{3125} \approx 1.9 \times 10^{2184}. $$
But we can keep going. Let x pentated to the y, or xPy, mean x tetrated to itself y times. Let x sextated to the y, or xSy, mean x pentated to itself y times, and so on.
Then we can define the Ackermann function, invented by the mathematician Wilhelm Ackermann in 1928, which cuts across all these operations to get more rapid growth than we could with any one of them alone. In terms of the operations above, we can give a slightly nonstandard, but perfectly serviceable, definition of the Ackermann function as follows:
A(1) is 1+1=2.
A(2) is 2×2=4.
A(3) is 3 to the 3rd power, or 33=27.
Not very impressive so far! But wait…
A(4) is 4 tetrated to the 4, or
$$ ^{4}4 = 4^{4^{4^4}} = 4^{4^{256}} = BIG $$
A(5) is 5 pentated to the 5, which I won’t even try to simplify. A(6) is 6 sextated to the 6. And so on.
More than just a curiosity, the Ackermann function actually shows up sometimes in math and theoretical computer science. For example, the inverse Ackermann function—a function α such that α(A(n))=n, which therefore grows as slowly as the Ackermann function grows quickly, and which is at most 4 for any n that would ever arise in the physical universe—sometimes appears in the running times of real-world algorithms.
In the meantime, though, the Ackermann function also has a more immediate application. Next time you find yourself in a biggest-number contest, like the one with which we opened this talk, you can just write A(1000), or even A(A(1000)) (after specifying that A means the Ackermann function above). You’ll win—period—unless your opponent has also heard of something Ackermann-like or beyond.
OK, but Ackermann is very far from the end of the story. If we want to go incomprehensibly beyond it, the starting point is the so-called “Berry Paradox”, which was first described by Bertrand Russell, though he said he learned it from a librarian named Berry. The Berry Paradox asks us to imagine leaping past exponentials, the Ackermann function, and every other particular system for naming huge numbers. Instead, why not just go straight for a single gambit that seems to beat everything else:
The biggest number that can be specified using a hundred English words or fewer
Why is this called a paradox? Well, do any of you see the problem here?
Right: if the above made sense, then we could just as well have written
Twice the biggest number that can be specified using a hundred English words or fewer
But we just specified that number—one that, by definition, takes more than a hundred words to specify—using far fewer than a hundred words! Whoa. What gives?
Most logicians would say the resolution of this paradox is simply that the concept of “specifying a number with English words” isn’t precisely defined, so phrases like the ones above don’t actually name definite numbers. And how do we know that the concept isn’t precisely defined? Why, because if it was, then it would lead to paradoxes like the Berry Paradox!
So if we want to escape the jaws of logical contradiction, then in this gambit, we ought to replace English by a clear, logical language: one that can be used to specify numbers in a completely unambiguous way. Like … oh, I know! Why not write:
The biggest number that can be specified using a computer program that’s at most 1000 bytes long
To make this work, there are just two issues we need to get out of the way. First, what does it mean to “specify” a number using a computer program? There are different things it could mean, but for concreteness, let’s say a computer program specifies a number N if, when you run it (with no input), the program runs for exactly N steps and then stops. A program that runs forever doesn’t specify any number.
The second issue is, which programming language do we have in mind: BASIC? C? Python? The answer is that it won’t much matter! The Church-Turing Thesis, one of the foundational ideas of computer science, implies that every “reasonable” programming language can emulate every other one. So the story here can be repeated with just about any programming language of your choice. For concreteness, though, we’ll pick one of the first and simplest programming languages, namely “Turing machine”—the language invented by Alan Turing all the way back in 1936!
In the Turing machine language, we imagine a one-dimensional tape divided into squares, extending infinitely in both directions, and with all squares initially containing a “0.” There’s also a tape head with n “internal states,” moving back and forth on the tape. Each internal state contains an instruction, and the only allowed instructions are: write a “0” in the current square, write a “1” in the current square, move one square left on the tape, move one square right on the tape, jump to a different internal state, halt, and do any of the previous conditional on whether the current square contains a “0” or a “1.”
Using Turing machines, in 1962 the mathematician Tibor Radó invented the so-called Busy Beaver function, or BB(n), which allowed naming by far the largest numbers anyone had yet named. BB(n) is defined as follows: consider all Turing machines with n internal states. Some of those machines run forever, when started on an all-0 input tape. Discard them. Among the ones that eventually halt, there must be some machine that runs for a maximum number of steps before halting. However many steps that is, that’s what we call BB(n), the nth Busy Beaver number.
The first few values of the Busy Beaver function have actually been calculated, so let’s see them.
BB(1) is 1. For a 1-state Turing machine on an all-0 tape, the choices are limited: either you halt in the very first step, or else you run forever.
BB(2) is 6, as isn’t too hard to verify by trying things out with pen and paper.
BB(3) is 21: that determination was already a research paper.
BB(4) is 107 (another research paper).
Much like with the Ackermann function, not very impressive yet! But wait:
BB(5) is not yet known, but it’s known to be at least 47,176,870.
BB(6) is at least 7.4×1036,534.
BB(7) is at least
$$ 10^{10^{10^{10^{18,000,000}}}}. $$
Clearly we’re dealing with a monster here, but can we understand just how terrifying of a monster? Well, call a sequence f(1), f(2), … computable, if there’s some computer program that takes n as input, runs for a finite time, then halts with f(n) as its output. To illustrate, f(n)=n2, f(n)=2n, and even the Ackermann function that we saw before are all computable.
But I claim that the Busy Beaver function grows faster than any computable function. Since this talk should have at least some math in it, let’s see a proof of that claim.
Maybe the nicest way to see it is this: suppose, to the contrary, that there were a computable function f that grew at least as fast as the Busy Beaver function. Then by using that f, we could take the Berry Paradox from before, and turn it into an actual contradiction in mathematics! So for example, suppose the program to compute f were a thousand bytes long. Then we could write another program, not much longer than a thousand bytes, to run for (say) 2×f(1000000) steps: that program would just need to include a subroutine for f, plus a little extra code to feed that subroutine the input 1000000, and then to run for 2×f(1000000) steps. But by assumption, f(1000000) is at least the maximum number of steps that any program up to a million bytes long can run for—even though we just wrote a program, less than a million bytes long, that ran for more steps! This gives us our contradiction. The only possible conclusion is that the function f, and the program to compute it, couldn’t have existed in the first place.
(As an alternative, rather than arguing by contradiction, one could simply start with any computable function f, and then build programs that compute f(n) for various “hardwired” values of n, in order to show that BB(n) must grow at least as rapidly as f(n). Or, for yet a third proof, one can argue that, if any upper bound on the BB function were computable, then one could use that to solve the halting problem, which Turing famously showed to be uncomputable in 1936.)
In some sense, it’s not so surprising that the BB function should grow uncomputably quickly—because if it were computable, then huge swathes of mathematical truth would be laid bare to us. For example, suppose we wanted to know the truth or falsehood of the Goldbach Conjecture, which says that every even number 4 or greater can be written as a sum of two prime numbers. Then we’d just need to write a program that checked each even number one by one, and halted if and only if it found one that wasn’t a sum of two primes. Suppose that program corresponded to a Turing machine with N states. Then by definition, if it halted at all, it would have to halt after at most BB(N) steps. But that means that, if we knew BB(N)—or even any upper bound on BB(N)—then we could find out whether our program halts, by simply running it for the requisite number of steps and seeing. In that way we’d learn the truth or falsehood of Goldbach’s Conjecture—and similarly for the Riemann Hypothesis, and every other famous unproved mathematical conjecture (there are a lot of them) that can be phrased in terms of a computer program never halting.
(Here, admittedly, I’m using “we could find” in an extremely theoretical sense. Even if someone handed you an N-state Turing machine that ran for BB(N) steps, the number BB(N) would be so hyper-mega-astronomical that, in practice, you could probably never distinguish the machine from one that simply ran forever. So the aforementioned “strategy” for proving Goldbach’s Conjecture, or the Riemann Hypothesis would probably never yield fruit before the heat death of the universe, even though in principle it would reduce the task to a “mere finite calculation.”)
OK, you wanna know something else wild about the Busy Beaver function? In 2015, my former student Adam Yedidia and I wrote a paper where we proved that BB(8000)—i.e., the 8000th Busy Beaver number—can’t be determined using the usual axioms for mathematics, which are called Zermelo-Fraenkel (ZF) set theory. Nor can B(8001) or any larger Busy Beaver number.
To be sure, BB(8000) has some definite value: there are finitely many 8000-state Turing machines, and each one either halts or runs forever, and among the ones that halt, there’s some maximum number of steps that any of them runs for. What we showed is that math, if it limits itself to the currently-accepted axioms, can never prove the value of BB(8000), even in principle.
The way we did that was by explicitly constructing an 8000-state Turing machine, which (in effect) enumerates all the consequences of the ZF axioms one after the next, and halts if and only if it ever finds a contradiction—that is, a proof of 0=1. Presumably set theory is actually consistent, and therefore our program runs forever. But if you proved the program ran forever, you’d also be proving the consistency of set theory. And has anyone heard of any obstacle to doing that? Of course, Gödel’s Incompleteness Theorem! Because of Gödel, if set theory is consistent (well, technically, also arithmetically sound), then it can’t prove our program either halts or runs forever. But that means set theory can’t determine BB(8000) either—because if it could do that, then it could also determine the behavior of our program.
To be clear, it was long understood that there’s some computer program that halts if and only if set theory is inconsistent—and therefore, that the axioms of set theory can determine at most k values of the Busy Beaver function, for some positive integer k. “All” Adam and I did was to prove the first explicit upper bound, k≤8000, which required a lot of optimizations and software engineering to get the number of states down to something reasonable (our initial estimate was more like k≤1,000,000). More recently, Stefan O’Rear has improved our bound—most recently, he says, to k≤1000, meaning that, at least by the lights of ZF set theory, fewer than a thousand values of the BB function can ever be known.
Meanwhile, let me remind you that, at present, only four values of the function are known! Could the value of BB(100) already be independent of set theory? What about BB(10)? BB(5)? Just how early in the sequence do you leap off into Platonic hyperspace? I don’t know the answer to that question but would love to.
Ah, you ask, but is there any number sequence that grows so fast, it blows even the Busy Beavers out of the water? There is!
Imagine a magic box into which you could feed in any positive integer n, and it would instantly spit out BB(n), the nth Busy Beaver number. Computer scientists call such a box an “oracle.” Even though the BB function is uncomputable, it still makes mathematical sense to imagine a Turing machine that’s enhanced by the magical ability to access a BB oracle any time it wants: call this a “super Turing machine.” Then let SBB(n), or the nth super Busy Beaver number, be the maximum number of steps that any n-state super Turing machine makes before halting, if given no input.
By simply repeating the reasoning for the ordinary BB function, one can show that, not only does SBB(n) grow faster than any computable function, it grows faster than any function computable by super Turing machines (for example, BB(n), BB(BB(n)), etc).
Let a super duper Turing machine be a Turing machine with access to an oracle for the super Busy Beaver numbers. Then you can use super duper Turing machines to define a super duper Busy Beaver function, which you can use in turn to define super duper pooper Turing machines, and so on!
Let “level-1 BB” be the ordinary BB function, let “level-2 BB” be the super BB function, let “level 3 BB” be the super duper BB function, and so on. Then clearly we can go to “level-k BB,” for any positive integer k.
But we need not stop even there! We can then go to level-ω BB. What’s ω? Mathematicians would say it’s the “first infinite ordinal”—the ordinals being a system where you can pass from any set of numbers you can possibly name (even an infinite set), to the next number larger than all of them. More concretely, the level-ω Busy Beaver function is simply the Busy Beaver function for Turing machines that are able, whenever they want, to call an oracle to compute the level-k Busy Beaver function, for any positive integer k of their choice.
But why stop there? We can then go to level-(ω+1) BB, which is just the Busy Beaver function for Turing machines that are able to call the level-ω Busy Beaver function as an oracle. And thence to level-(ω+2) BB, level-(ω+3) BB, etc., defined analogously. But then we can transcend that entire sequence and go to level-2ω BB, which involves Turing machines that can call level-(ω+k) BB as an oracle for any positive integer k. In the same way, we can pass to level-3ω BB, level-4ω BB, etc., until we transcend that entire sequence and pass to level-ω2 BB, which can call any of the previous ones as oracles. Then we have level-ω3 BB, level-ω4 BB, etc., until we transcend that whole sequence with level-ωω BB. But we’re still not done! For why not pass to level
$$ \omega^{\omega^{\omega}} $$,
level
$$ \omega^{\omega^{\omega^{\omega}}} $$,
etc., until we reach level
$$ \left. \omega^{\omega^{\omega^{.^{.^{.}}}}}\right\} _{\omega\text{ times}} $$?
(This last ordinal is also called ε0.) And mathematicians know how to keep going even to way, way bigger ordinals than ε0, which give rise to ever more rapidly-growing Busy Beaver sequences. Ordinals achieve something that on its face seems paradoxical, which is to systematize the concept of transcendence.
So then just how far can you push this? Alas, ultimately the answer depends on which axioms you assume for mathematics. The issue is this: once you get to sufficiently enormous ordinals, you need some systematic way to specify them, say by using computer programs. But then the question becomes which ordinals you can “prove to exist,” by giving a computer program together with a proof that the program does what it’s supposed to do. The more powerful the axiom system, the bigger the ordinals you can prove to exist in this way—but every axiom system will run out of gas at some point, only to be transcended, in Gödelian fashion, by a yet more powerful system that can name yet larger ordinals.
So for example, if we use Peano arithmetic—invented by the Italian mathematician Giuseppe Peano—then Gentzen proved in the 1930s that we can name any ordinals below ε0, but not ε0 itself or anything beyond it. If we use ZF set theory, then we can name vastly bigger ordinals, but once again we’ll eventually run out of steam.
(Technical remark: some people have claimed that we can transcend this entire process by passing from first-order to second-order logic. But I fundamentally disagree, because with second-order logic, which number you’ve named could depend on the model of set theory, and therefore be impossible to pin down. With the ordinal Busy Beaver numbers, by contrast, the number you’ve named might be breathtakingly hopeless ever to compute—but provided the notations have been fixed, and the ordinals you refer to actually exist, at least we know there is a unique positive integer that you’re talking about.)
Anyway, the upshot of all of this is that, if you try to hold a name-the-biggest-number contest between two actual professionals who are trying to win, it will (alas) degenerate into an argument about the axioms of set theory. For the stronger the set theory you’re allowed to assume consistent, the bigger the ordinals you can name, therefore the faster-growing the BB functions you can define, therefore the bigger the actual numbers.
So, yes, in the end the biggest-number contest just becomes another Gödelian morass, but one can get surprisingly far before that happens.
In the meantime, our universe seems to limit us to at most 10122 choices that could ever be made, or experiences that could ever be had, by any one observer. Or fewer, if you believe that you won’t live until the heat death of the universe in some post-Singularity computer cloud, but for at most about 102 years. In the meantime, the survival of the human race might hinge on people’s ability to understand much smaller numbers than 10122: for example, a billion, a trillion, and other numbers that characterize the exponential growth of our civilization and the limits that we’re now running up against.
On a happier note, though, if our goal is to make math engaging to young people, or to build bridges between the quantitative and literary worlds, the way this festival is doing, it seems to me that it wouldn’t hurt to let people know about the vastness that’s out there. Thanks for your attention.

 Follow
Follow
