The mathematicians discovered the central mystery of computability, the conjecture represented by the statement P is not equal to NP. The conjecture asserts that there exist mathematical problems which can be quickly solved in individual cases but cannot be solved by a quick algorithm applicable to all cases. The most famous example of such a problem is the traveling salesman problem, which is to find the shortest route for a salesman visiting a set of cities, knowing the distance between each pair. All the experts believe that the conjecture is true, and that the traveling salesman problem is an example of a problem that is P but not NP. But nobody has even a glimmer of an idea how to prove it. This is a mystery that could not even have been formulated within the nineteenth-century mathematical universe of Hermann Weyl.
At a literal level, the above passage contains several howlers (I’ll leave it to commenters to point them out), but at a “deeper” “poetic” level, Dyson happens to be absolutely right: P versus NP is the example par excellence of a mathematical mystery that human beings lacked the language even to express until very recently in our history.
Speaking of P versus NP, I’m currently visiting Sasha Razborov at his new home, the University of Chicago. (Yesterday we had lunch at “Barack’s favorite pizza place”, and walked past “Barack’s favorite bookstore.” Were they really his favorites? At a deeper poetic level, sure.)
One of the highlights of my trip was meeting Ketan Mulmuley for the first time, and talking with him about his geometric approach to the P vs. NP problem. Ketan comes across in person as an almost mythological figure, like a man who flew too close to the sun and was driven nearly to ecstatic obsession by what he saw. This is someone who’ll explain to anyone in earshot, for as long as he or she cares to listen, that he’s glimpsed the outlines of a solution of the P vs. NP problem in the far frontiers of mathematics, and it is beautiful, and it is elegant—someone who leaps from Ramanujan graphs to quantum groups to the Riemann Hypothesis over finite fields to circuit lower bounds in the space of a single sentence, as his hapless listener struggles to hold on by a fingernail—someone whose ideas seem to remain obstinately in limbo between incoherence and profundity, making just enough sense that you keep listening to them.
Now, I get emails every few months from people claiming to have proved P≠NP (not even counting the P=NP claimants). Without exception, they turn out to be hunting polar bears in the Sahara: they don’t even grapple with natural proofs, or relativization, or algebrization, or the lower bounds/derandomization connection, or any the other stuff we know already about why the problem is hard. Ketan, by contrast, might be searching for polar bears with a kaleidoscope and trying to hunt them with a feather, but he’s in the Arctic all right. I have no idea whether his program will succeed within my lifetime at uncovering any of the truth about the P vs. NP problem, but it at least clears the lower hurdle of reflecting some of the higher truth.
1. The CRA’s Computing Community Consortium, chaired by national treasure Ed Lasowska of the University of Washington, recently put up a website with fifteen brief essays about “Computing Research Initiatives for the 21st Century.” These essays will apparently be reviewed by the science policy staff at the Obama transition office. Dave Bacon and I wrote the essay on quantum computing—or rather, Dave wrote it with his inimitable enthusiasm, and then I tried in vain to moderate it slightly. (When Dave told me that President-elect Obama needed my help with quantum computing policy, what was I going to say? “Sorry, I’m doing my laundry this weekend”?)
2. Lee Gomes of Forbes magazine wrote a fun article about the Worldview Manager project that I blogged about a while ago. (For some reason, Lee wasn’t deterred by my pointing out to him that the project hasn’t even started yet.)
I arrived in Tempe, Arizona yesterday for a workshop on “The Nature of the Laws of Physics,” kindly hosted by Paul Davies’ Beyond Center. I’m treating this as a much-needed end-of-semester vacation—with warm desert air, eccentric personalities, talks without theorems, and the sort of meandering philosophical debate I get inexplicably cranky if I haven’t had for a month. Just one problem: I was hoping Cosmic Variance‘s Sean Carroll would arrive to provide much-needed positivist reinforcement against the gangs of metaphysical ruffians, but the California Clarifier backed out—leaving the remaining skeptics to dodge relentless volleys of ill-posed questions only three hours’ drive from the O.K. Corral.
My graduate course 6.896 Quantum Complexity Theory ended last week, with ten amazing student project presentations. Thanks so much to the students, and to my TA Yinmeng Zhang, for making this a great course (at least for me). Almost all of the scribe notes are now available on the course website. But be warned: not only did I not write these notes, not only did I not edit them, for the most part I haven’t read them yet. Use entirely at your own risk.
Want to do graduate study in quantum information at MIT? Yes? Then my colleague Jeff Shapiro asks me to point you to the new website of iQUiSE, our Interdisciplinary Quantum Information Science & Engineering program (motto: “Further Depleting the Supply of Quantum Funding-Related Acronyms Containing the Letters Q and I”). If you’re interested, you apply to a traditional department (such as physics, math, EECS, or mechanical engineering), but specify in your application that you’re interested in iQUiSE. The application deadline is today—but if for some strange reason 17 hours isn’t enough to write your application, there’s always another year.
Dmitry Gavinsky asks me to throw the following piece of meat to the comment-wolves: What exactly should count as a “new” quantum algorithm?
Over at Cosmic Variance, I learned that FQXi (the organization that paid for me to go to Iceland) sponsored an essay contest on “The Nature of Time”, and the submission deadline was last week. Because of deep and fundamental properties of time (at least as perceived by human observers), this means that I will not be able to enter the contest. However, by exploiting the timeless nature of the blogosphere, I can now tell you what I would have written about if I had entered.(Warning: I can’t write this post without actually explaining some standard CS and physics in a semi-coherent fashion. I promise to return soon to your regularly-scheduled programming of inside jokes and unexplained references.)
I’ve often heard it said—including by physicists who presumably know better—that “time is just a fourth dimension,” that it’s no different from the usual three dimensions of space, and indeed that this is a central fact that Einstein proved (or exploited? or clarified?) with relativity. Usually, this assertion comes packaged with the distinct but related assertion that the “passage of time” has been revealed as a psychological illusion: for if it makes no sense to talk about the “flow” of x, y, or z, why talk about the flow of t? Why not just look down (if that’s the right word) on the entire universe as a fixed 4-dimensional crystalline structure?
In this post, I’ll try to tell you why not. My starting point is that, even if we leave out all the woolly metaphysics about our subjective experience of time, and look strictly at the formalism of special and general relativity, we still find that time behaves extremely differently from space. In special relativity, the invariant distance between two points p and q—meaning the real physical distance, the distance measure that doesn’t depend on which coordinate system we happen to be using—is called the interval. If the point p has coordinates (x,y,z,t) (in any observer’s coordinate system), and the point q has coordinates (x’,y’,z’,t’), then the interval between p and q equals
(x-x’)2+(y-y’)2+(z-z’)2-(t-t’)2
where as usual, 1 second of time equals 3×108 meters of space. (Indeed, it’s possible to derive special relativity by starting with this fact as an axiom.)
Now, notice the minus sign in front of (t-t’)2? That minus sign is physics’ way of telling us thattime is different from space—or in Sesame Street terms, “one of these four dimensions is not like the others.” It’s true that special relativity lets you mix together the x,y,z,t coordinates in a way not possible in Newtonian physics, and that this mixing allows for the famous time dilation effect, whereby someone traveling close to the speed of light relative to you is perceived by you as almost frozen in time. But no matter how you choose the t coordinate, there’s still going to be a t coordinate, which will stubbornly behave differently from the other three spacetime coordinates. It’s similar to how my “up” points in nearly the opposite direction from an Australian’s “up”, and yet we both have an “up” that we’d never confuse with the two spatial directions perpendicular to it.
(By contrast, the two directions perpendicular to “up” can and do get confused with each other, and indeed it’s not even obvious which directions we’re talking about: north and west? forward and right? If you were floating in interstellar space, you’d have three perpendicular directions to choose arbitrarily, and only the choice of the fourth time direction would be an “obvious” one for you.)
In general relativity, spacetime is a curved manifold, and thus the interval gets replaced by an integral over a worldline. But the local neighborhood around each point still looks like the (3+1)-dimensional spacetime of special relativity, and therefore has a time dimension which behaves differently from the three space dimensions. Mathematically, this corresponds to the fact that the metric at each point has (-1,+1,+1,+1) signature—in other words, it’s a 4×4 matrix with 3 positive eigenvalues and 1 negative eigenvalue. If space and time were interchangeable, then all four eigenvalues would have the same sign.
But how does that minus sign actually do the work of making time behave differently from space? Well, because of the minus sign, the interval between two points can be either positive or negative (unlike Euclidean distance, which is always nonnegative). If the interval between two points p and q is positive, then p and q are spacelike separated, meaning that there’s no way for a signal emitted at p to reach q or vice versa. If the interval is negative, then p and q are timelike separated, meaning that either a signal from p can reach q, or a signal from q can reach p. If the interval is zero, then p and q are lightlike separated, meaning a signal can get from one point to the other, but only by traveling at the speed of light.
In other words, that minus sign is what ensures spacetime has a causal structure: two events can stand to each other in the relations “before,” “after,” or “neither before nor after” (what in pre-relativistic terms would be called “simultaneous”). We know from general relativity that the causal structure is a complicated dynamical object, itself subject to the laws of physics: it can bend and sag in the presence of matter, and even contract to a point at black hole singularities. But the causal structure still exists—and because of it, one dimension simply cannot be treated on the same footing as the other three.
Put another way, the minus sign in front of the t coordinate reflects what a sufficiently-articulate child might tell you is the main difference between space and time: you can go backward in space, but you can’t go backward in time. Or: you can revisit the city of your birth, but you can’t (literally) revisit the decade of your birth. Or: the Parthenon could be used later to store gunpowder, and the Tower of London can be used today as a tourist attraction, but the years 1700-1750 can’t be similarly repurposed for a new application: they’re over.
Notice that we’re now treating space and time pragmatically, as resources—asking what they’re good for, and whether a given amount of one is more useful than a given amount of the other. In other words, we’re now talking about time and space like theoretical computer scientists. If the difference between time and space shows up in physics through the (-1,+1,+1,+1) signature, the difference shows up in computer science through the famous
P ≠ PSPACE
conjecture. Here P is the class of problems that are solvable by a conventional computer using a “reasonable” amount of time, meaning, a number of steps that increases at most polynomially with the problem size. PSPACE is the class of problems solvable by a conventional computer using a “reasonable” amount of space, meaning a number of memory bits that increases at most polynomially with the problem size. It’s evident that P ⊆ PSPACE—in other words, any problem solvable in polynomial time is also solvable in polynomial space. For it takes at least one time step to access a given memory location—so in polynomial time, you can’t exploit more than polynomial space anyway. It’s also clear that PSPACE ⊆ EXP—that is, any problem solvable in polynomial space is also solvable in exponential time. The reason is that a computer with K bits of memory can only be 2K different configurations before the same configuration recurs, in which case the machine will loop forever. But computer scientists conjecture that PSPACE ⊄ P—that is, polynomial space is more powerful than polynomial time—and have been trying to prove it for about 40 years.
(You might wonder how P vs. PSPACE relates to the even better-known P vs. NP problem. NP, which consists of all problems for which a solution can be verified in polynomial time, sits somewhere between P and PSPACE. So if P≠NP, then certainly P≠PSPACE as well. The converse is not known—but a proof of P≠PSPACE would certainly be seen as a giant step toward proving P≠NP.)
So from my perspective, it’s not surprising that time and space are treated differently in relativity. Whatever else the laws of physics do, presumably they have to differentiate time from space somehow—since otherwise, how could polynomial time be weaker than polynomial space?
But you might wonder: is reusability really the key property of space that isn’t shared by time—or is it merely one of several differences, or a byproduct of some other, more fundamental difference? Can we adduce evidence for the computer scientist’s view of the space/time distinction—the view that sees reusability as central? What could such evidence even consist of? Isn’t it all just a question of definition at best, or metaphysics at worst?
On the contrary, I’ll argue that the computer scientist’s view of the space/time distinction actually leads to something like a prediction, and that this prediction can be checked, not by experiment but mathematically. If reusability really is the key difference, then if we change the laws of physics so as to make time reusable—keeping everything else the same insofar as we can—polynomial time ought to collapse with polynomial space. In other words, the set of computational problems that are efficiently solvable ought to become PSPACE. By contrast, if reusability is not the key difference, then changing the laws of physics in this way might well give some complexity class other than PSPACE.
But what do we even mean by changing the laws of physics so as to “make time reusable”? The first answer that suggests itself is simply to define a “time-traveling Turing machine,” which can move not only left and right on its work tape, but also backwards and forwards in time. If we do this, then we’ve made time into another space dimension by definition, so it’s not at all surprising if we end up being able to solve exactly the PSPACE problems.
But wait: if time is reusable, then “when” does it get reused? Should we think of some “secondary” time parameter that inexorably marches forward, even as the Turing machine scuttles back and forth in the “original” time? But if so, then why can’t the Turing machine also go backwards in the secondary time? Then we could introduce a tertiary time parameter to count out the Turing machine’s movements in the secondary time, and so on forever.
But this is stupid. What the endless proliferation of times is telling us is that we haven’t really made time reusable. Instead, we’ve simply redefined the time dimension to be yet another space dimension, and then snuck in a new time dimension that behaves in the same boring, conventional way as the old time dimension. We then perform the sleight-of-hand of letting an exponential amount of the secondary time elapse, even as we restrict the “original” time to be polynomially bounded. The trivial, uninformative result is then that we can solve PSPACE problems in “polynomial time.”
So is there a better way to treat time as a reusable resource? I believe that there is. We can have a parameter that behaves like time in that it “never changes direction”, but behaves unlike time in that it loops around in a cycle. In other words, we can have a closed timelike curve, or CTC. CTCs give us a dimension that (1) is reusable, but (2) is also recognizably “time” rather than “space.”
Of course, no sooner do we define CTCs than we confront the well-known problem of dead grandfathers. How can we ensure that the events around the CTC are causally consistent, that they don’t result in contradictions? For my money, the best answer to this question was provided by David Deutsch, in his paper “Quantum Mechanics near Closed Time-like Lines” (unfortunately not online). Deutsch observed that, if we allow the state of the universe to be probabilistic or quantum, then we can always tell a consistent story about the events inside a CTC. So for example, the resolution of the grandfather paradox is simply that you’re born with 1/2 probability, and if you’re born you go back in time and kill your grandfather, therefore you’re born with 1/2 probability, etc. Everything’s consistent; there’s no paradox!
More generally, any stochastic matrix S has at least one stationary distribution—that is, a distribution D such that S(D)=D. Likewise, any quantum-mechanical operation Q has at least one stationary state—that is, a mixed state ρ such that Q(ρ)=ρ. So we can consider a model of closed timelike curve computation where we (the users) specify a polynomial-time operation, and then Nature has to find some probabilistic or quantum state ρ which is left invariant by that operation. (There might be more than one such ρ—in which case, being pessimists, we can stipulate that Nature chooses among them adversarially.) We then get to observe ρ, and output an answer based on it.
So what can be done in this computational model? Long story short: in a recent paper with Watrous, we proved that
PCTC = BQPCTC = PSPACE.
Or in English, the set of problems solvable by a polynomial-time CTC computer is exactly PSPACE—and this holds whether the CTC computer is classical or quantum. In other words, CTCs make polynomial time equal to polynomial space as a computational resource. Unlike in the case of “secondary time,” this is not obvious from the definitions, but has to be proved. (Note that to prove PSPACE ⊆ PCTC ⊆ BQPCTC ⊆ EXP is relatively straightforward; the harder part is to show BQPCTC ⊆ PSPACE.)
The bottom line is that, at least in the computational world, making time reusable (even while preserving its “directionality”) really does make it behave like space. To me, that lends some support to the contention that, in our world, the fact that space is reusable and time is not is at the core of what makes them different from each other.
I don’t think I’ve done enough to whip up controversy yet, so let me try harder in the last few paragraphs. A prominent school of thought in quantum gravity regards time as an “emergent phenomenon”: something that should not appear in the fundamental equations of the universe, just like hot and cold, purple and orange, maple and oak don’t appear in the fundamental equations, but only at higher levels of organization. Personally, I’ve long had trouble making sense of this view. One way to explain my difficulty is using computational complexity. If time is “merely” an emergent phenomenon, then is the presumed intractability of PSPACE-complete problems also an emergent phenomenon? Could a quantum theory of gravity—a theory that excluded time as “not fundamental enough”—therefore be exploited to solve PSPACE-complete problems efficiently (whatever “efficiently” would even mean in such a theory)? Or maybe computation is also just an emergent phenomenon, so the question doesn’t even make sense? Then what isn’t an emergent phenomenon?
I don’t have a knockdown argument, but the distinction between space and time has the feel to me of something that needs to be built into the laws of physics at the machine-code level. I’ll even venture a falsifiable prediction: that if and when we find a quantum theory of gravity, that theory will include a fundamental (not emergent) distinction between space and time. In other words, no matter what spacetime turns out to look like at the Planck scale, the notion of causal ordering and the relationships “before” and “after” will be there at the lowest level. And it will be this causal ordering, built into the laws of physics, that finally lets us understand why closed timelike curves don’t exist and PSPACE-complete problems are intractable.
I’ll end with a quote from a June 2008 Scientific American article by Jerzy Jurkiewicz, Renate Loll and Jan Ambjorn, about the “causal dynamical triangulations approach” to quantum gravity.
What could the trouble be? In our search for loopholes and loose ends in the Euclidean approach [to quantum gravity], we finally hit on the crucial idea, the one ingredient absolutely necessary to make the stir fry come out right: the universe must encode what physicists call causality. Causality means that empty spacetime has a structure that allows us to distinguish unambiguously between cause and effect. It is an integral part of the classical theories of special and general relativity.
Euclidean quantum gravity does not build in a notion of causality. The term “Euclidean” indicates that space and time are treated equally. The universes that enter the Euclidean superposition have four spatial directions instead of the usual one of time and three of space. Because Euclidean universes have no distinct notion of time, they have no structure to put events into a specific order; people living in these universes would not have the words “cause” or “effect” in their vocabulary. Hawking and others taking this approach have said that “time is imaginary,” in both a mathematical sense and a colloquial one. Their hope was that causality would emerge as a large-scale property from microscopic quantum fluctuations that individually carry no imprint of a causal structure. But the computer simulations dashed that hope.
Instead of disregarding causality when assembling individual universes and hoping for it to reappear through the collective wisdom of the superposition, we decided to incorporate the causal structure at a much earlier stage. The technical term for our method is causal dynamical triangulations. In it, we first assign each simplex an arrow of time pointing from the past to the future. Then we enforce causal gluing rules: two simplices must be glued together to keep their arrows pointing in the same direction. The simplices must share a notion of time, which unfolds steadily in the direction of these arrows and never stands still or runs backward.
By building in a time dimension that behaves differently from the space dimensions, the authors claim to have solved a problem that’s notoriously plagued computer simulations of quantum gravity models: namely, that of recovering a spacetime that “behave[s] on large distances like a four-dimensional, extended object and not like a crumpled ball or polymer”. Are their results another indication that time might not be an illusion after all? Time (hopefully a polynomial amount of it) will tell.
At least three people have now asked my opinion of the paper Mathematical Undecidability and Quantum Randomness by Paterek et al., which claims to link quantum mechanics with Gödelian incompleteness. Abstract follows:
We propose a new link between mathematical undecidability and quantum physics. We demonstrate that the states of elementary quantum systems are capable of encoding mathematical axioms and show that quantum measurements are capable of revealing whether a given proposition is decidable or not within the axiomatic system. Whenever a mathematical proposition is undecidable within the axioms encoded in the state, the measurement associated with the proposition gives random outcomes. Our results support the view that quantum randomness is irreducible and a manifestation of mathematical undecidability.
Needless to say, the paper has already been Slashdotted. I was hoping to avoid blogging about it, because I doubt I can do so without jeopardizing my quest for Obamalike equanimity and composure. But similar to what’s happened severaltimesbefore, I see colleagues who I respect and admire enormously—in this case, several who have done pioneering experiments that tested quantum mechanics in whole new regimes—making statements that can be so easily misinterpreted by a public and a science press hungry to misinterpret, that I find my fingers rushing to type even as my brain struggles in vain to stop them.
Briefly, what is the connection the authors seek to make between mathematical undecidability and quantum randomness? Quantum states are identified with the “axioms” of a formal system, while measurements (technically, projective measurements in the Pauli group) are identified with “propositions.” A proposition is “decidable” from a given set of axioms, if and only if the requisite measurement produces a determinate outcome when applied to the state (in other words, if the state is an eigenstate of the measurement). From the simple fact that no one-qubit state can be an eigenstate of the σx and σz measurements simultaneously (in other words, the Uncertainty Principle), it follows immediately that “no axiom system can decide every proposition.” The authors do some experiments to illustrate these ideas, which (not surprisingly) produce the outcomes predicted by quantum mechanics.
But does this have anything to do with “undecidability” in the mathematical sense, and specifically with Gödel’s Theorem? Well, it’s not an illustration of Gödel’s Theorem to point out that, knowing only that x=5, you can’t deduce the value of an unrelated variable y. Nor is it an illustration of Gödel’s Theorem to point out that, knowing only one bit about the pair of bits (x,y), you can’t deduce x and y simultaneously. These observations have nothing to do with Gödel’s Theorem. Gödel’s Theorem is about statements that are undecidable within some formal system, despite having definite truth-values—since the statements just assert the existence of integers with certain properties, and those properties are stated explicitly. To get this kind of undecidability, Gödel had to use axioms that were strong enough to encode the addition and multiplication of integers, as well as the powerful inference rules of first-order logic. By contrast, the logical deductions in the Paterek et al. paper consist entirely of multiplications of tensor products of Pauli matrices. And the logic of Pauli matrix multiplication (i.e., is this matrix in the subgroup generated by these other matrices or not?) is, as the authors point out, trivially decidable. (The groups in question are all finite, so one can just enumerate their elements—or use Gaussian elimination for greater efficiency.)
For this reason, I fear that Paterek et al.’s use of the phrase “mathematical undecidability” might mislead people. The paper’s central observation can be re-expressed as follows: given an N-qubit stabilizer state |ψ〉, the tensor products of Pauli matrices that stabilize |ψ〉 form a group of order 2N. On the other hand, the total number of tensor products of Pauli matrices is 4N, and hence the remaining 4N-2N tensor products correspond to “undecidable propositions” (meaning that they’re not in |ψ〉’s stabilizer group). These and other facts about stabilizer states were worked out by Gottesman, Knill, and others in the 1990s.
(Incidentally, the paper references results of Chaitin, which do interpret variants of Gödel’s Theorem in terms of axiom systems “not containing enough information” to decide Kolmogorov-random sentences. But Chaitin’s results don’t actually deal with information in the technical sense, but rather with Kolmogorov complexity. Mathematically, the statements Chaitin is talking about have zero information, since they’re all mathematical truths.)
So is there a connection between quantum mechanics and logic? There is—and it was pointed out by Birkhoff and von Neumann in 1936. Recall that Paterek et al. identify propositions with projective measurements, and axioms with states. But in logic, an axiom is just any proposition we assume; otherwise it has the same form as any other proposition. So it seems to me that we ought to identify both propositions and axioms with projective measurements. States that are eigenstates of all the axioms would then correspond to models of those axioms. Also, logical inferences should derive some propositions from other propositions, like so: “any state that is an eigenstate of both X and Y is also an eigenstate of Z.” As it turns out, this is precisely the approach that Birkhoff and von Neumann took; the field they started is called “quantum logic.”
Update (Dec. 8): I’ve posted an interesting response from Caslav Brukner, and my response to his response.
A year ago, a group of CS theorists—including Eli Ben-Sasson, Andrej Bogdanov, Anupam Gupta, Bobby Kleinberg, Rocco Servedio, and your humble blogger, and fired up by the evangelism of Sanjeev Arora, Christos Papadimitriou, and Avi Wigderson—agreed to form a committee to improve Wikipedia’s arguably-somewhat-sketchy coverage of theoretical computer science. One year later, our committee of busy academics has done, to a first approximation, nothing.
In considering this state of affairs, I’m reminded of the story of Wikipedia’s founding. Before Wikipedia there was Nupedia, where the articles had to be written by experts and peer-reviewed. After three years, Nupedia had produced a grand total of 24 articles. Then a tiny, experimental adjunct to Nupedia—a wiki-based peanut gallery where anyone could contribute—exploded into the flawed, chaotic, greatest encyclopedia in the history of the world that we all know today.
Personally, I’ve never understood academics (and there are many) who sneer at Wikipedia. I’ve been both an awestruck admirer of it and a massive waster of time on it since shortly after it came out. But I also accept the reality that Wikipedia is fundamentally an amateur achievement. It will never be an ideal venue for academics—not only because we don’t have the time, but because we’re used to (1) putting our names on our stuff, (2) editorializing pretty freely, (3) using “original research” as a compliment and not an accusation, and (4) not having our prose rewritten or deleted by people calling themselves Duduyat, Raul654, and Prokonsul Piotrus.
So this Thanksgiving weekend, at the suggestion of my student Andy Drucker, I’m going to try an experiment in the spirit of Wikipedia. I’m going to post our wish-list of theoretical computer science topics, and invite you—my interested, knowledgeable readers—to write some articles about them. (Of course you’re welcome to add your own topics, not that you’d need permission.) Don’t worry if you’re not an expert; even some stubs would be helpful. Let us know in the comments section when you’ve written something.
Thanks, and happy Thanksgiving!
Research areas not defined on Wikipedia
Property testing
Quantum computation (though Quantum computer is defined)
Algorithmic game theory
Derandomization
Sketching algorithms
Propositional proof complexity (though Proof complexity is defined)
Well-known theoretical computer scientists without Wikipedia pages
No, I’m not going to make that list … but you can.
Update (11/30): A big shout-out and thank-you to those theorists, such as David Eppstein, who’ve actually been contributing to Wikipedia and not just theorizing about it!
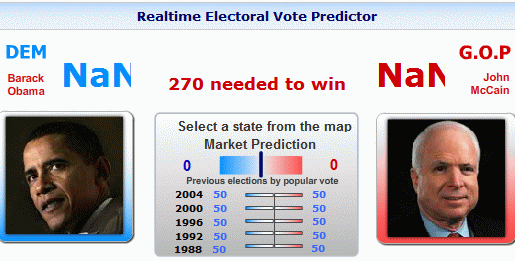
Here’s what I saw the last time I went to Intrade (yes, I’ve been checking about 200,000 times per day):
I understand that in this situation, the Constitution dictates that the selection of a President goes to the IEEE 754R Technical Committee.
Joke-Killing Explanation for Non-Nerds:NaN is “Not a Number,” an error code in floating-point arithmetic for expressions like 0/0. Evidently there’s a bug in Intrade’s script to add the expected electoral college votes.
In this post, I wish to propose for the reader’s favorable consideration a doctrine that will strike many in the nerd community as strange, bizarre, and paradoxical, but that I hope will at least be given a hearing. The doctrine in question is this: while it is possible that, a century hence, humans will have built molecular nanobots and superintelligent AIs, uploaded their brains to computers, and achieved eternal life, these possibilities are not quite so likely as commonly supposed, nor do they obviate the need to address mundane matters such as war, poverty, disease, climate change, and helping Democrats win elections.
Last week I read Ray Kurzweil’s The Singularity Is Near, which argues that by 2045, or somewhere around then, advances in AI, neuroscience, nanotechnology, and other fields will let us transcend biology, upload our brains to computers, and achieve the dreams of the ancient religions, including eternal life and whatever simulated sex partners we want. (Kurzweil, famously, takes hundreds of supplements a day to maximize his chance of staying alive till then.) Perhaps surprisingly, Kurzweil does not come across as a wild-eyed fanatic, but as a humane idealist; the text is thought-provoking and occasionally even wise. I did have quibbles with his discussions of quantum computing and the possibility of faster-than-light travel, but Kurzweil wisely chose not to base his conclusions on any speculations about these topics.
I find myself in agreement with Kurzweil on three fundamental points. Firstly, that whatever purifying or ennobling qualities suffering might have, those qualities are outweighed by suffering’s fundamental suckiness. If I could press a button to free the world from loneliness, disease, and death—the downside being that life might become banal without the grace of tragedy—I’d probably hesitate for about five seconds before lunging for it. As Tevye said about the ‘curse’ of wealth: “may the Lord strike me with that curse, and may I never recover!”
Secondly, there’s nothing bad about overcoming nature through technology. Humans have been in that business for at least 10,000 years. Now, it’s true that fanatical devotion to particular technologies—such as the internal combustion engine—might well cause the collapse of human civilization and the permanent degradation of life on Earth. But the only plausible solution is better technology, not the Kaczynski/Flintstone route.
Thirdly, were there machines that pressed for recognition of their rights with originality, humor, and wit, we’d have to give it to them. And if those machines quickly rendered humans obsolete, I for one would salute our new overlords. In that situation, the denialism of John Searle would cease to be just a philosophical dead-end, and would take on the character of xenophobia, resentment, and cruelty.
Yet while I share Kurzweil’s ethical sense, I don’t share his technological optimism. Everywhere he looks, Kurzweil sees Moore’s-Law-type exponential trajectories—not just for transistor density, but for bits of information, economic output, the resolution of brain imaging, the number of cell phones and Internet hosts, the cost of DNA sequencing … you name it, he’ll plot it on a log scale. Kurzweil acknowledges that, even over the brief periods that his exponential curves cover, they have hit occasional snags, like (say) the Great Depression or World War II. And he’s not so naïve as to extend the curves indefinitely: he knows that every exponential is just a sigmoid (or some other curve) in disguise. Nevertheless, he fully expects current technological trends to continue pretty much unabated until they hit fundamental physical limits.
I’m much less sanguine. Where Kurzweil sees a steady march of progress interrupted by occasional hiccups, I see a few fragile and improbable victories against a backdrop of malice, stupidity, and greed—the tiny amount of good humans have accomplished in constant danger of drowning in a sea of blood and tears, as happened to so many of the civilizations of antiquity. The difference is that this time, human idiocy is playing itself out on a planetary scale; this time we can finally ensure that there are no survivors left to start over.
(Also, if the Singularity ever does arrive, I expect it to be plagued by frequent outages and terrible customer service.)
Obviously, my perceptions are as colored by my emotions and life experiences as Kurzweil’s are by his. Despite two years of reading Overcoming Bias, I still don’t know how to uncompute myself, to predict the future from some standpoint of Bayesian equanimity. But just as obviously, it’s our duty to try to minimize bias, to give reasons for our beliefs that are open to refutation and revision. So in the rest of this post, I’d like to share some of the reasons why I haven’t chosen to spend my life worrying about the Singularity, instead devoting my time to boring, mundane topics like anthropic quantum computing and cosmological Turing machines.
The first, and most important, reason is also the reason why I don’t spend my life thinking about P versus NP: because there are vastly easier prerequisite questions that we already don’t know how to answer. In a field like CS theory, you very quickly get used to being able to state a problem with perfect clarity, knowing exactly what would constitute a solution, and still not having any clue how to solve it. (In other words, you get used to P not equaling NP.) And at least in my experience, being pounded with this situation again and again slowly reorients your worldview. You learn to terminate trains of thought that might otherwise run forever without halting. Faced with a question like “How can we stop death?” or “How can we build a human-level AI?” you learn to respond: “What’s another question that’s easier to answer, and that probably has to be answered anyway before we have any chance on the original one?” And if someone says, “but can’t you at least estimate how long it will take to answer the original question?” you learn to hedge and equivocate. For looking backwards, you see that sometimes the highest peaks were scaled—Fermat’s Last Theorem, the Poincaré conjecture—but that not even the greatest climbers could peer through the fog to say anything terribly useful about the distance to the top. Even Newton and Gauss could only stagger a few hundred yards up; the rest of us are lucky to push forward by an inch.
The second reason is that as a goal recedes to infinity, the probability increases that as we approach it, we’ll discover some completely unanticipated reason why it wasn’t the right goal anyway. You might ask: what is it that we could possibly learn about neuroscience, biology, or physics, that would make us slap our foreheads and realize that uploading our brains to computers was a harebrained idea from the start, reflecting little more than early-21st-century prejudice? Unlike (say) Searle or Penrose, I don’t pretend to know. But I do think that the “argument from absence of counterarguments” loses more and more force, the further into the future we’re talking about. (One can, of course, say the same about quantum computers, which is one reason why I’ve nevertaken the possibility of building them as a given.) Is there any example of a prognostication about the 21st century written before 1950, most of which doesn’t now seem quaint?
The third reason is simple comparative advantage. Given our current ignorance, there seems to me to be relatively little worth saying about the Singularity—and what is worth saying is already being said well by others. Thus, I find nothing wrong with a few people devoting their lives to Singulatarianism, just as others should arguably spend their lives worrying about asteroid collisions. But precisely because smart people do devote brain-cycles to these possibilities, the rest of us have correspondingly less need to.
The fourth reason is the Doomsday Argument. Having digested the Bayesian case for a Doomsday conclusion, and the rebuttals to that case, and the rebuttals to the rebuttals, what I find left over is just a certain check on futurian optimism. Sure, maybe we’re at the very beginning of the human story, a mere awkward adolescence before billions of glorious post-Singularity years ahead. But whatever intuitions cause us to expect that could easily be leading us astray. Suppose that all over the universe, civilizations arise and continue growing exponentially until they exhaust their planets’ resources and kill themselves out. In that case, almost every conscious being brought into existence would find itself extremely close to its civilization’s death throes. If—as many believe—we’re quickly approaching the earth’s carrying capacity, then we’d have not the slightest reason to be surprised by that apparent coincidence. To be human would, in the vast majority of cases, mean to be born into a world of air travel and Burger King and imminent global catastrophe. It would be like some horrific Twilight Zone episode, with all the joys and labors, the triumphs and setbacks of developing civilizations across the universe receding into demographic insignificance next to their final, agonizing howls of pain. I wish reading the news every morning furnished me with more reasons not to be haunted by this vision of existence.
The fifth reason is my (limited) experience of AI research. I was actually an AI person long before I became a theorist. When I was 12, I set myself the modest goal of writing a BASIC program that would pass the Turing Test by learning from experience and following Asimov’s Three Laws of Robotics. I coded up a really nice tokenizer and user interface, and only got stuck on the subroutine that was supposed to understand the user’s question and output an intelligent, Three-Laws-obeying response. Later, at Cornell, I was lucky to learn from Bart Selman, and worked as an AI programmer for Cornell’s RoboCup team—an experience that taught me little about the nature of intelligence but a great deal about how to make robots pass a ball. At Berkeley, my initial focus was on machine learning and statistical inference; had it not been for quantum computing, I’d probably still be doing AI today. For whatever it’s worth, my impression was of a field with plenty of exciting progress, but which has (to put it mildly) some ways to go before recapitulating the last billion years of evolution. The idea that a field must either be (1) failing or (2) on track to reach its ultimate goal within our lifetimes, seems utterly without support in the history of science (if understandable from the standpoint of both critics and enthusiastic supporters). If I were forced at gunpoint to guess, I’d say that human-level AI seemed to me like a slog of many more centuries or millennia (with the obvious potential for black swans along the way).
As you may have gathered, I don’t find the Singulatarian religion so silly as not to merit a response. Not only is the “Rapture of the Nerds” compatible with all known laws of physics; if humans survive long enough it might even come to pass. The one notion I have real trouble with is that the AI-beings of the future would be no more comprehensible to us than we are to dogs (or mice, or fish, or snails). After all, we might similarly expect that there should be models of computation as far beyond Turing machines as Turing machines are beyond finite automata. But in the latter case, we know the intuition is mistaken. There is a ceiling to computational expressive power. Get up to a certain threshold, and every machine can simulate every other one, albeit some slower and others faster. Now, it’s clear that a human who thought at ten thousand times our clock rate would be a pretty impressive fellow. But if that’s what we’re talking about, then we don’t mean a point beyond which history completely transcends us, but “merely” a point beyond which we could only understand history by playing it in extreme slow motion.
Yet while I believe the latter kind of singularity is possible, I’m not at all convinced of Kurzweil’s thesis that it’s “near” (where “near” means before 2045, or even 2300). I see a world that really did change dramatically over the last century, but where progress on many fronts (like transportation and energy) seems to have slowed down rather than sped up; a world quickly approaching its carrying capacity, exhausting its natural resources, ruining its oceans, and supercharging its climate; a world where technology is often powerless to solve the most basic problems, millions continue to die for trivial reasons, and democracy isn’t even clearly winning over despotism; a world that finally has a communications network with a decent search engine but that still hasn’t emerged from the tribalism and ignorance of the Pleistocene. And I can’t help thinking that, before we transcend the human condition and upload our brains to computers, a reasonable first step might be to bring the 18th-century Enlightenment to the 98% of the world that still hasn’t gotten the message.
This post will be longer and more technical than most — but what can I say? Sometimes you need to get something technical off your chest. The topic is something my student, Andy Drucker, and I (along with several interested others) have been thinking about on and off for months, and if we’re not going to get a paper out of it, at least we’ll have this blog post.
Complexity theory could be defined as the field concerned with deep, nontrivial, mathematically-sophisticated justifications for failure. For example, we can’t solve NP-complete problems in polynomial time, but maybe that’s not so bad, since we conjecture there is no solution (P≠NP). Of course, we also can’t prove P≠NP — but maybe that’s not so bad either, since we have good explanations for why the problem is so hard, like relativization, natural proofs, and algebrization.
On the other hand, consider the problem of showing that the Permanent of an nxn matrix requires arithmetic circuits of more than polynomial size. (Given a field F—which we’ll assume for this post is finite—an arithmetic circuit over F is a circuit whose only allowed operations are addition, subtraction, and multiplication over F, and that doesn’t have direct access to the bit representations of the field elements.)
The problem of circuit lower bounds for the Permanent is currently at the frontier of complexity theory. As we now know, it’s intimately related both to derandomizing polynomial identity testing and to the τ problem of Blum, Cucker, Shub, and Smale. Alas, not only can we not prove that Perm∉AlgP/poly (which is the street name for this conjecture), we don’t have any good excuse for why we can’t prove it! Relativization and algebrization don’t seem to apply here, since no one would think of using diagonalization-based techniques on such a problem in the first place. So that leaves us with natural proofs.
The theory of natural proofs, which was developed by Razborov and Rudich in 1993 and for which they recently shared the Gödel Prize, started out as an attempt to explain why it’s so hard to prove NP⊄P/poly (i.e., that SAT doesn’t have polynomial-size circuits, which is a slight strengthening of P≠NP). They said: suppose the proof were like most of the circuit lower bound proofs that we actually know (as a canonical example, the proof that Parity is not in AC0). Then as a direct byproduct, the proof would yield an efficient algorithm A that took as input the truth table of a Boolean function f, and determined that either:
f belongs to an extremely large class C of “random-looking” functions, which includes SAT but does not include any function computable by polynomial-size circuits, or
f does not belong to C.
(The requirement that A run in time polynomial in the size of the truth table, N=2n, is called constructivity. The requirement that C be a large class of functions — say, at least a 2-poly(n) fraction of functions — is called largeness.)
Razborov and Rudich then pointed out that such a polynomial-time algorithm A could be used to distinguish truly random functions from pseudorandom functions with non-negligible bias. As follows from the work of Håstad-Impagliazzo-Levin-Luby and Goldreich-Goldwasser-Micali, one could thereby break one-way functions in subexponential time, and undermine almost all of modern cryptography! In other words, if cryptography is possible, then proofs with the property above are not possible. The irony — we can’t prove lower bounds because lower bounds very much like the ones we want to prove are true — is thick enough to spread on toast.
Now suppose we tried to use the same argument to explain why we can’t prove superpolynomial arithmetic circuit lower bounds for the Permanent, over some finite field F. In that case, a little thought reveals that what we’d need is an arithmetic pseudorandom function family over F. More concretely, we’d need a family of functions gs:Fn→F, where s is a short random “seed”, such that:
Every gs is computable by a polynomial-size, constant-depth (or at most log-depth) arithmetic circuit, but
No polynomial-time algorithm, given oracle access to gs (for a randomly-chosen s), is able to distinguish gs from a random low-degree polynomial over F with non-negligible bias.
It’s important not to get so hung up on definitional details that you miss the substantive issue here. However, three comments on the definition seem in order.
Firstly, we restrict gs to be computable by constant or log-depth circuits, since that’s the regime we’re ultimately interested in (more about this later). The Permanent is a low-degree polynomial, and well-known depth reduction theorems say (roughly speaking) that any low-degree polynomial that’s computable by a small circuit, is also computable by a small circuit with very small depth.
Secondly, we say that no polynomial-time algorithm should be able to distinguish gs from a random low-degree polynomial, rather than a random function. The reason is clear: if gs is itself a low-degree polynomial, then it can always be distinguished easily from a random function, just by picking a random line and doing polynomial interpolation! On the other hand, it’s reasonable to hope that within the space of low-degree polynomials, gs looks random—and that’s all we need to draw a natural proofs conclusion. Note that the specific distribution over low-degree polynomials that we simulate doesn’t really matter: it could be (say) the uniform distribution over all degree-d polynomials for some fixed d, or the uniform distribution over polynomials in which no individual variable is raised to a higher power than d.
Thirdly, to get a close analogy with the original Razborov-Rudich theory, we stipulated that no ordinary (Boolean) polynomial-time algorithm should be able to distinguish gs from a random low-degree polynomial. However, this is not essential. If we merely knew (for example) that no polynomial-size arithmetic circuit could distinguish gs from a random low-degree polynomial, then we’d get the weaker but still interesting conclusion that any superpolynomial arithmetic circuit lower bound for the Permanent would have to be “arithmetically non-naturalizing”: that is, it would have to exploit some property of the Permanent that violates either largeness or else “arithmetic constructivity.” There’s a smooth tradeoff here, between the complexity of the distinguishing algorithm and the strength of the natural proofs conclusion that you get.
There’s no question that, if we had an arithmetic pseudorandom function family as above, it would tell us something useful about arithmetic circuit lower bounds. For we do have deep and nontrivial arithmetic circuit lower bounds — for example, those of Nisan and Wigderson (see also here), Razborov and Grigoriev, Grigoriev and Karpinski, Shpilka and Wigderson, Raz (see also here), Raz, Shpilka, and Yehudayoff, Raz and Yehudayoff, and Mignon and Ressayre. And as far as I can tell, all of these lower bounds do in fact naturalize in the sense above. (Indeed, they should even naturalize in the strong sense that there are quasipolynomial-size arithmetic circuits for the relevant properties.) Concretely, most of these techniques involve looking at the truth table (or rather, the “value table”) of the function g:Fn→F to be lower-bounded, constructing so-called partial-derivatives matrices from that truth table, and then lower-bounding the ranks of those matrices. But these operations—in particular, computing the rank—are all polynomial-time (or quasipolynomial-time for arithmetic circuits). Thus, if we could construct arithmetic pseudorandom functions, we could use them to argue that no techniques similar to the ones we know will work to prove superpolynomial arithmetic circuit lower bounds for the Permanent.
So the problem is “merely” one of constructing these goddamned arithmetic pseudorandom functions. Not surprisingly, it’s easy to construct arithmetic function families that seem pseudorandom (concrete example coming later), but the game we’re playing is that you need to be able to base the pseudorandomness of your PRF on some ‘accepted’ or ‘established’ computational intractability assumption. And here, alas, the current toolbox of complexity theory simply doesn’t seem up for the job.
To be sure, we have pseudorandom function families that are computable by constant-depth Boolean threshold circuits — most famously, those of Naor and Reingold, which are pseudorandom assuming that factoring Blum integers or the decisional Diffie-Hellman problem are hard. (Both assumptions, incidentally, are false in the quantum world, but that’s irrelevant for natural proofs purposes, since the proof techniques that we know how to think about yield polynomial-time classical algorithms.) However, the Naor-Reingold construction is based on modular exponentiation, and doing modular exponentiation in constant depth crucially requires using the bit representation of the input numbers. So this is not something that’s going to work in the arithmetic circuit world.
At the moment, it seems the closest available result to what’s needed is that of Klivans and Sherstov in computational learning theory. These authors show (among other things) that if the n1.5-approximate shortest vector problem is hard for quantum computers, then learning depth-3 arithmetic circuits from random examples is intractable for classical computers. (Here quantum computing actually is relevant—since by using techniques of Regev, it’s possible to use a quantum hardness assumption to get a classical hardness consequence!)
This result seems like exactly what we need—so then what’s the problem? Why aren’t we done? Well, it’s that business about the random examples. If the learner is allowed to make correlated or adaptive queries to the arithmetic circuit’s truth table — as we need to assume it can, in the arithmetic natural proofs setting — then we don’t currently have any hardness result. Furthermore, there seems to me to be a basic difficulty in extending Klivans-Sherstov to the case of adaptive queries (though Klivans himself seemed more optimistic). In particular, there’s a nice idea due to Angluin and Kharitonov, which yields a generic way (using digital signatures) for converting hardness-of-learning results against nonadaptive queries to hardness-of-learning results against adaptive queries. But interestingly, the Angluin-Kharitonov reduction depends essentially on our being in the Boolean world, and seems to break down completely in the arithmetic circuit world.
So, is this all Andy and I can say—that we tried to create an arithmetic natural proofs theory, but that ultimately, our attempt to find a justification of failure to find a justification of failure was itself a failure? Well, not quite. I’d like to end this post with one theorem, and one concrete conjecture.
The theorem is that, if we don’t care about the depth of the arithmetic circuits (or, more-or-less equivalently, the degree of the polynomials that they compute), then we can create arithmetic pseudorandom functions over finite fields, and hence the arithmetic natural proofs theory that we wanted. Furthermore, the only assumption we need for this is that pseudorandom functions exist in the ordinary Boolean world — about the weakest assumption one could possibly hope for!
This theorem might seem surprising, since after all, we don’t believe that there’s any general way to take a polynomial-size Boolean circuit C that operates on finite field elements x1,…,xn represented in binary, and simulate C by a polynomial-size arithmetic circuit that uses only addition, subtraction, and multiplication, and not any bit operations. (The best such simulation, due to Boneh and Lipton, is based on elliptic curves and takes moderately exponential time.) Nevertheless, Andy and I are able to show that for pseudorandomness purposes, unbounded-depth Boolean circuits and unbounded-depth arithmetic circuits are essentially equivalent.
To prove the theorem: let the input to our arithmetic circuit C be elements x1,…,xn of some finite field Fp (I’ll assume for simplicity that p is prime; you should think of p as roughly exponential in n). Then what C will do will be to first compute various affine functions of the input:
y1=a0+a1x1+…+anxn, y2=b0+b1x1+…+bnxn, etc.,
as many such functions as are needed, for coefficients ai, bi, etc. that are chosen at random and then “hardwired” into the circuit. C will then raise each yi to the (p-1)/2 power, using repeated squaring. Note that in a finite field Fp, raising y≠0 to the (p-1)/2 power yields either +1 or -1, depending on whether or not y is a quadratic residue. Let zi=(yi+1)/2. Then we now have a collection of 0/1 “bits.” Using these bits as our input, we can now compute whatever Boolean pseudorandom function we like, as follows: NOT(x) corresponds to the polynomial 1-x, AND(x,y) corresponds to xy, and OR(x,y) corresponds to 1-(1-x)(1-y). The result of this will be a collection of pseudorandom output bits, call them w1,…,wm. The final step is to convert back into a pseudorandom finite field element, which we can do as follows:
Output = w1 + 2w2 + 4w3 + 8w4 + … + 2m-1wm.
This will be pseudorandom assuming (as we can) that 2m is much larger than p.
But why does this construction work? That is, assuming the Boolean circuit was pseudorandom, why is the arithmetic circuit simulating it also pseudorandom? Well, this is a consequence of two basic facts:
Affine combinations constitute a family of pairwise-independent hash functions. That is, for every pair (x1,…,xn)≠(y1,…,yn), the probability over a0,…,an that a0+a1x1+…+anxn=a0+a1y1+…+anyn is only 1/p. Furthermore, the pairwise independence can be easily seen to be preserved under raising various affine combinations to the (p-1)/2 power.
If we draw f from a family of pseudorandom functions, and draw h from a family of pairwise-independent hash functions, then f(h(x)) will again be a pseudorandom function. Intuitively this is “obvious”: after all, the only way to distinguish f(h(x)) from random without distinguishing f from random would be to find two inputs x,y such that h(x)=h(y), but since h is pairwise-independent and since the outputs f(h(x)) aren’t going to help, finding such a collision should take exponential time. A formal security argument can be found (e.g.) in this paper by Bellare, Canetti, and Krawczyk.
Now for the conjecture. I promised earlier that I’d give you an explicit candidate for a (low-degree) arithmetic pseudorandom function, so here it is. Given inputs x1,…,xn∈Fp, let m be polynomially related to n, and let L1(x1,…,xn),…,Lm^2(x1,…,xn) be affine functions of x1,…,xn, with the coefficients chosen at random and then “hardwired” into our circuit, as before. Arrange L1(x1,…,xn),…,Lm^2(x1,…,xn) into an mxm matrix, and take the determinant of that matrix as your output. That’s it.
(The motivation for this construction is Valiant’s result from the 1970s, that determinant is universal under projections. That might suggest, though of course it doesn’t prove, that breaking this function should be as hard as breaking any other arithmetic pseudorandom function.)
Certainly the output of the above generator will be computable by an arithmetic circuit of size mO(log m)n. On the other hand, I conjecture that if you don’t know L1,…,Lm^2, and are polynomial-time bounded, then the output of the generator will be indistinguishable to you from that of a random polynomial of degree m. I’m willing to offer $50 to anyone who can prove or disprove this conjecture—or for that matter, who can prove or disprove the more basic conjecture that there exists a low-degree arithmetic pseudorandom function family! (Here, of course, “prove” means “prove modulo some accepted hardness assumption,” while “disprove” means “disprove.”)
But please be quick about it! If we don’t hurry up and find a formal barrier to proving superpolynomial lower bounds for the Permanent, someone might actually roll up their sleeves and prove one—and we certainly don’t want that!
After reading theseblogposts dealing with the possibility of the Large Hadron Collider creating a black hole of strangelet that would destroy the earth — as well as this report from the LHC Safety Assessment Group, and thesewebsites advocating legal action against the LHC — I realized that I can remain silent about this important issue no longer.
As a concerned citizen of Planet Earth, I demand that the LHC begin operations as soon as possible, at as high energies as possible, and continue operating until such time as it is proven completely safe to turn it off.
Given our present state of knowledge, we simply cannot exclude the possibility that aliens will visit the Earth next year, and, on finding that we have not yet produced a Higgs boson, find us laughably primitive and enslave us. Or that a wormhole mouth or a chunk of antimatter will be discovered on a collision course with Earth, which can only be neutralized or deflected using new knowledge gleaned from the LHC. Yes, admittedly, the probabilities of these events might be vanishingly small, but the fact remains that they have not been conclusively ruled out. And that being the case, the Precautionary Principle dictates taking the only safe course of action: namely, turning the LHC on as soon as possible.
After all, the fate of the planet might conceivably depend on it.
 Follow
Follow