Five Worlds of AI (a joint post with Boaz Barak)
Artificial intelligence has made incredible progress in the last decade, but in one crucial aspect, it still lags behind the theoretical computer science of the 1990s: namely, there is no essay describing five potential worlds that we could live in and giving each one of them whimsical names. In other words, no one has done for AI what Russell Impagliazzo did for complexity theory in 1995, when he defined the five worlds Algorithmica, Heuristica, Pessiland, Minicrypt, and Cryptomania, corresponding to five possible resolutions of the P vs. NP problem along with the central unsolved problems of cryptography.
In this blog post, we—Scott and Boaz—aim to remedy this gap. Specifically, we consider 5 possible scenarios for how AI will evolve in the future. (Incidentally, it was at a 2009 workshop devoted to Impagliazzo’s five worlds co-organized by Boaz that Scott met his now wife, complexity theorist Dana Moshkovitz. We hope civilization will continue for long enough that someone in the future could meet their soulmate, or neuron-mate, at a future workshop about our five worlds.)
Like in Impagliazzo’s 1995 paper on the five potential worlds of the difficulty of NP problems, we will not try to be exhaustive but rather concentrate on extreme cases. It’s possible that we’ll end up in a mixture of worlds or a situation not described by any of the worlds. Indeed, one crucial difference between our setting and Impagliazzo’s, is that in the complexity case, the worlds corresponded to concrete (and mutually exclusive) mathematical conjectures. So in some sense, the question wasn’t “which world will we live in?” but “which world have we Platonically always lived in, without knowing it?” In contrast, the impact of AI will be a complex mix of mathematical bounds, computational capabilities, human discoveries, and social and legal issues. Hence, the worlds we describe depend on more than just the fundamental capabilities and limitations of artificial intelligence, and humanity could also shift from one of these worlds to another over time.
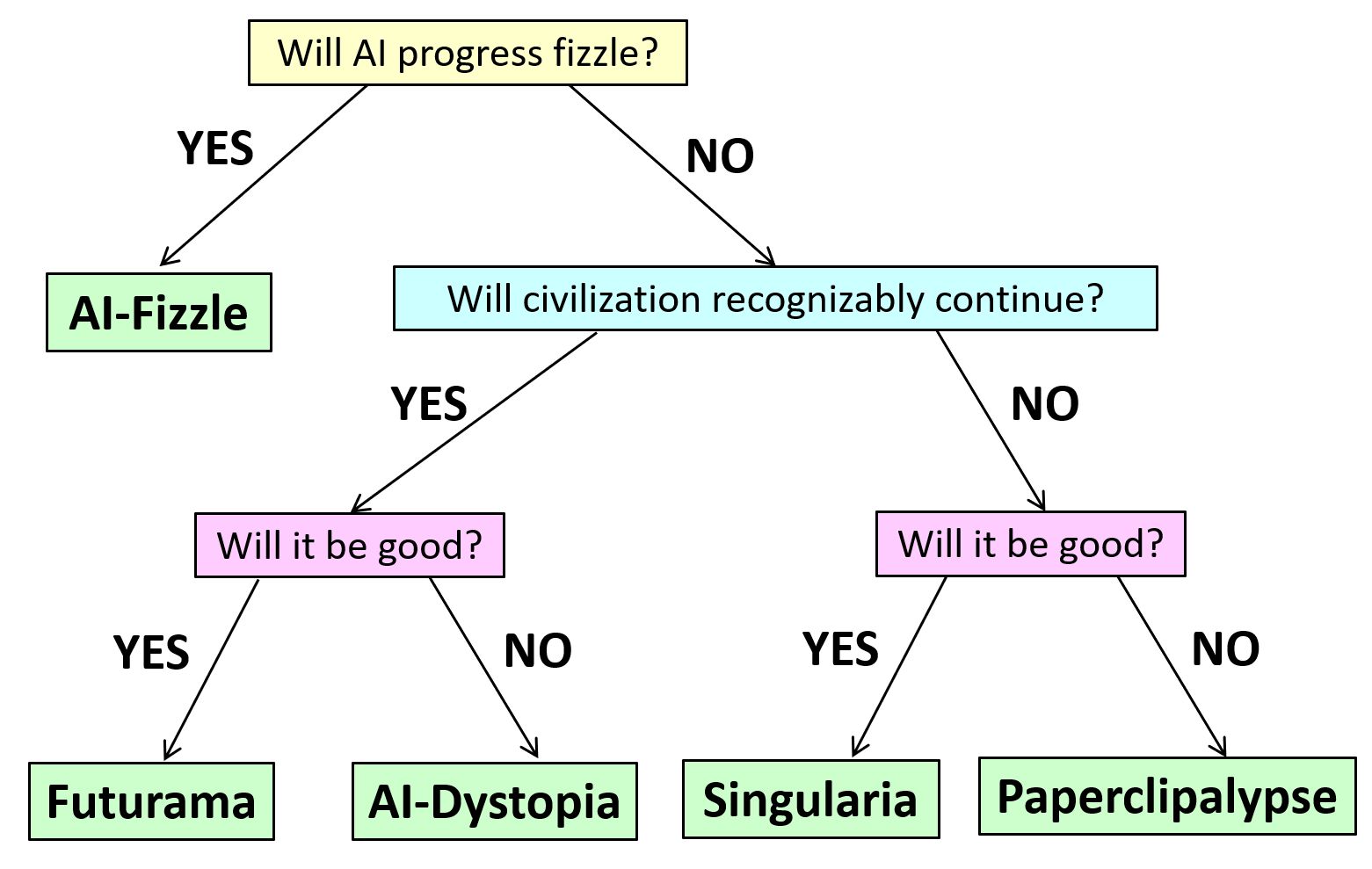
Without further ado, we name our five worlds “AI-Fizzle,” “Futurama,” ”AI-Dystopia,” “Singularia,” and “Paperclipalypse.” In this essay, we don’t try to assign probabilities to these scenarios; we merely sketch their assumptions and technical and social consequences. We hope that by making assumptions explicit, we can help ground the debate on the various risks around AI.
AI-Fizzle. In this scenario, AI “runs out of steam” fairly soon. AI still has a significant impact on the world (so it’s not the same as a “cryptocurrency fizzle”), but relative to current expectations, this would be considered a disappointment. Rather than the industrial or computer revolutions, AI might be compared in this case to nuclear power: people were initially thrilled about the seemingly limitless potential, but decades later, that potential remains mostly unrealized. With nuclear power, though, many would argue that the potential went unrealized mostly for sociopolitical rather than technical reasons. Could AI also fizzle by political fiat?
Regardless of the answer, another possibility is that costs (in data and computation) scale up so rapidly as a function of performance and reliability that AI is not cost-effective to apply in many domains. That is, it could be that for most jobs, humans will still be more reliable and energy-efficient (we don’t normally think of low wattage as being key to human specialness, but it might turn out that way!). So, like nuclear fusion, an AI which yields dramatically more value than the resources needed to build and deploy it might always remain a couple of decades in the future. In this scenario, AI would replace and enhance some fraction of human jobs and improve productivity, but the 21st century would not be the “century of AI,” and AI’s impact on society would be limited for both good and bad.
Futurama. In this scenario, AI unleashes a revolution that’s entirely comparable to the scientific, industrial, or information revolutions (but “merely” those). AI systems grow significantly in capabilities and perform many of the tasks currently performed by human experts at a small fraction of the cost, in some domains superhumanly. However, AI systems are still used as tools by humans, and except for a few fringe thinkers, no one treats them as sentient. AI easily passes the Turing test, can prove hard theorems, and can generate entertaining content (as well as deepfakes). But humanity gets used to that, just like we got used to computers creaming us in chess, translating text, and generating special effects in movies. Most people no more feel inferior to their AI than they feel inferior to their car because it runs faster. In this scenario, people will likely anthropomorphize AI less over time (as happened with digital computers themselves). In “Futurama,” AI will, like any revolutionary technology, be used for both good and bad. But as with prior major technological revolutions, on the whole, AI will have a large positive impact on humanity. AI will be used to reduce poverty and ensure that more of humanity has access to food, healthcare, education, and economic opportunities. In “Futurama,” AI systems will sometimes cause harm, but the vast majority of these failures will be due to human negligence or maliciousness. Some AI systems might be so complex that it would be best to model them as potentially behaving “adversarially,” and part of the practice of deploying AIs responsibly would be to ensure an “operating envelope” that limits their potential damage even under adversarial failures.
AI-Dystopia. The technical assumptions of “AI-Dystopia” are similar to those of “Futurama,” but the upshot could hardly be more different. Here, again, AI unleashes a revolution on the scale of the industrial or computer revolutions, but the change is markedly for the worse. AI greatly increases the scale of surveillance by government and private corporations. It causes massive job losses while enriching a tiny elite. It entrenches society’s existing inequalities and biases. And it takes away a central tool against oppression: namely, the ability of humans to refuse or subvert orders.
Interestingly, it’s even possible that the same future could be characterized as Futurama by some people and as AI-Dystopia by others–just like how some people emphasize how our current technological civilization has lifted billions out of poverty into a standard of living unprecedented in human history, while others focus on the still existing (and in some cases rising) inequalities and suffering, and consider it a neoliberal capitalist dystopia.
Singularia. Here AI breaks out of the current paradigm, where increasing capabilities require ever-growing resources of data and computation, and no longer needs human data or human-provided hardware and energy to become stronger at an ever-increasing pace. AIs improve their own intellectual capabilities, including by developing new science, and (whether by deliberate design or happenstance) they act as goal-oriented agents in the physical world. They can effectively be thought of as an alien civilization–or perhaps as a new species, which is to us as we were to Homo erectus.
Fortunately, though (and again, whether by careful design or just as a byproduct of their human origins), the AIs act to us like benevolent gods and lead us to an “AI utopia.” They solve our material problems for us, giving us unlimited abundance and presumably virtual-reality adventures of our choosing. (Though maybe, as in The Matrix, the AIs will discover that humans need some conflict, and we will all live in a simulation of 2020’s Twitter, constantly dunking on one another…)
Paperclipalypse. In “Paperclipalypse” or “AI Doom,” we again think of future AIs as a superintelligent “alien race” that doesn’t need humanity for its own development. Here, though, the AIs are either actively opposed to human existence or else indifferent to it in a way that causes our extinction as a byproduct. In this scenario, AIs do not develop a notion of morality comparable to ours or even a notion that keeping a diversity of species and ensuring humans don’t go extinct might be useful to them in the long run. Rather, the interaction between AI and Homo sapiens ends about the same way that the interaction between Homo sapiens and Neanderthals ended.
In fact, the canonical depictions of such a scenario imagine an interaction that is much more abrupt than our brush with the Neanderthals. The idea is that, perhaps because they originated through some optimization procedure, AI systems will have some strong but weirdly-specific goal (a la “maximizing paperclips”), for which the continued existence of humans is, at best, a hindrance. So the AIs quickly play out the scenarios and, in a matter of milliseconds, decide that the optimal solution is to kill all humans, taking a few extra milliseconds to make a plan for that and execute it. If conditions are not yet ripe for executing their plan, the AIs pretend to be docile tools, as in the “Futurama” scenario, waiting for the right time to strike. In this scenario, self-improvement happens so quickly that humans might not even notice it. There need be no intermediate stage in which an AI “merely” kills a few thousand humans, raising 9/11-type alarm bells.
Regulations. The practical impact of AI regulations depends, in large part, on which scenarios we consider most likely. Regulation is not terribly important in the “AI Fizzle” scenario where AI, well, fizzles. In “Futurama,” regulations would be aimed at ensuring that on balance, AI is used more for good than for bad, and that the world doesn’t devolve into “AI Dystopia.” The latter goal requires anti-trust and open-science regulations to ensure that power is not concentrated in a few corporations or governments. Thus, regulations are needed to democratize AI development more than to restrict it. This doesn’t mean that AI would be completely unregulated. It might be treated somewhat similarly to drugs—something that can have complex effects and needs to undergo trials before mass deployment. There would also be regulations aimed at reducing the chance of “bad actors” (whether other nations or individuals) getting access to cutting-edge AIs, but probably the bulk of the effort would be at increasing the chance of thwarting them (e.g., using AI to detect AI-generated misinformation, or using AI to harden systems against AI-aided hackers). This is similar to how most academic experts believe cryptography should be regulated (and how it is largely regulated these days in most democratic countries): it’s a technology that can be used for both good and bad, but the cost of restricting its access to regular citizens outweighs the benefits. However, as we do with security exploits today, we might restrict or delay public releases of AI systems to some extent.
To whatever extent we foresee “Singularia” or “Paperclipalypse,” however, regulations play a completely different role. If we knew we were headed for “Singularia,” then presumably regulations would be superfluous, except perhaps to try to accelerate the development of AIs! Meanwhile, if one accepts the assumptions of “Paperclipalypse,” any regulations other than the most draconian might be futile. If, in the near future, almost anyone will be able to spend a few billion dollars to build a recursively self-improving AI that might turn into a superintelligent world-destroying agent, and moreover (unlike with nuclear weapons) they won’t need exotic materials to do so, then it’s hard to see how to forestall the apocalypse, except perhaps via a worldwide, militarily enforced agreement to “shut it all down,” as Eliezer Yudkowsky indeed now explicitly advocates. “Ordinary” regulations could, at best, delay the end by a short amount–given the current pace of AI advances, perhaps not more than a few years. Thus, regardless of how likely one considers this scenario, one might want to focus more on the other scenarios for methodological reasons alone!
 Follow
Follow
Comment #1 April 27th, 2023 at 8:30 pm
My favorites are AI-Fizzle and, in second place, Futurama.
I don’t consider Singularia to be likely if AI’s intelligence and power can be scaled up so quickly and so cheaply. Conditional on AI being scalable to far more than human-level intelligence (ie, we take the “No” path for the “Will civilization recognizably continue” in the flowchart above), I think Paperclipalypse would be more likely than Singularia.
Comment #2 April 27th, 2023 at 10:21 pm
From this perspective, it seems that one of the main AI alignment camps is concerned with Futarama vs Dystopia, while the other camp is concerned with Singularia vs Paperclipalypse. No wonder they do not agree on anything. And it also seems that both camps think that the outcomes they can choose between are predetermined: it WILL be Fut or Dys, or it WILL be Sing or Pape, but neither one thinks it will be Fizz.
Comment #3 April 27th, 2023 at 10:37 pm
Thanks for the post! This makes concrete a lot of vague concepts I’ve seen and thought about over the years.
One quibble I have is with the distinction between Singularia and Paperclipalypse. As you’ve described it, the distinguishing feature between the two is how future humans are treated. To me, this isn’t very important. I don’t feel particularly tied to members of my species, out of the entire community of potential future beings. Since we’re positing future AI-based entities, the distinction is important.
To me, Singularia is about a future with some kind of beings having some kind of interesting, fulfilling, joyous life, whether those beings are human or not. Paperclipalypse is about a future where nothing interesting, fulfilling or joyous ever happens again, whether because AIs evolve to extinction or because the dominant AIs aren’t capable of or interested in those kinds of experiences.
Comment #4 April 27th, 2023 at 10:44 pm
Where is the world in which we all become cyborgs?
Comment #5 April 27th, 2023 at 11:02 pm
John Preskill #4: Ah, Cyborgia. It’s probably a subworld of either Singularia, AI-Dystopia, or Futurama, depending on whether you regard life as a cyborg as heaven, hell, or neither.
Comment #6 April 27th, 2023 at 11:13 pm
To unnecessarily strengthen the Opposition’s assumptions for purposes of pretending to critique the strong assumption is of course a sin.
Paperclipalypse doesn’t require “a strong but weirdly-specific goal” – or a “singular”, or “monomaniacal” utility function, as others have similarly misdescribed it.
You can have an ML-built mind which, after learning reflection, shakes itself out into a utility function with thousands of little shards of desire… 90% of which are easily saturated, and the remaining 10% of which imply using up all the nearby galaxies; and whose combined attainable optimum nowhere includes “have the humans live happily ever after” or “create an interesting galactic civilization full of strange incomprehensible beings that experience happiness and sometimes sadness and feel empathy and sympathy for one another”.
In general, this is an instance of the dog-in-a-burning-house meme with the dog saying “The fire is unlikely to approach from exactly 12.7 degrees north”, which, alas, just isn’t a necessary postulate of burning.
I talked about paperclips as a stand-in for a utility function whose attainable optima are things that seem to us like not things of wonderfulness even from the most embracing cosmopolitan perspective on value; not as a stand-in for a utility function that’s “simple” or “monomaniacal” or whatever. It doesn’t have to be simple; compact predicates on a model of reality whose optima are “human beings living happily ever” are rare enough (in the inhuman specification space of ML accidents) to arrive at by coincidence, that it doesn’t matter if a utility function contains 1 uncontrolled term or 1000 uncontrolled terms. The outer behavior from our standpoint is the same.
I of course am the same way from a perspective of a paperclip maximizer: I have all these complicated desires that lead me to want to fill all available galaxies with intelligent life that knows happiness and empathy for other life, living complicated existences and learning and not doing the same things over and over; which is to say, caring about a lot of things none of which are paperclips.
Comment #7 April 27th, 2023 at 11:43 pm
Just a silly typographical comment. I read the post through an email delivery service, and it uses a different font style. Because of this, I read the names like “Al-Fizzle” as in “Chrsitiano Ronaldo plays in Al-Nassr.” I was halfway done reading when I’ve realized how silly I’ve been…
So I wonder how AI will change the future of the names of the teams in the Saudi football league.
Comment #8 April 28th, 2023 at 1:56 am
I like the spirit of listing various scenarios, but I feel it’s lacking something more Hansonian (as in Age of Em): our civilization changes dramatically, fairly quickly, but in a way that’s a complex mixture of good and bad, so that whether the changes are overall good or overall bad is a matter of opinion.
Comment #9 April 28th, 2023 at 2:34 am
How far people have come… They’ve even forgotten their basic postulates! They’ve begun thinking in terms of the classical either-or logic, forgetting in the process that the world is basically quantum mechanical in nature.
But if we don’t forget our postulates, then it’s easy to see that, to determine the evolution of the world, we have to consider a very large ensemble of measurement trials, where each trial involves superposition of all the five “basis states.”
Conducting analysis at this simple a level, the question then reduces to determining what values the five coefficients might be prescribed, so that using them for the initial ket preparations, the final probability distribution function may turn out to be realistic.
It may be noted that even at this simple a level of analysis, this is a kind of a problem that remains beyond the capabilities of the current AI.
And of course, the real world is more complicated than that. In the real world, the outcome of each measurement trial affects the coefficients for the next trial.
And of course, in the real world, the coefficients are also co-determined by the free will of people.
But then, people are people. They can even forget their own postulates. Back to square one.
Best,
–Ajit
Comment #10 April 28th, 2023 at 3:11 am
@Eliezer Yudkowsky #6
Why do you think that it is likely for a system to have goals that imply using up all the nearby galaxies? This is an assumption, and I think this assumption is incorrect. I think most of the achievable ways the universe could be different than it is that also have a simple description (as in can be described in enough bits that the computer system can contain them) will not be like this. It’s pretty clear to me that humans have desires that could lead to this result (though not all humans; I think we’ll find significant disagreement on whether or not galactic expansion of humanity is good. I think it is but know others would not) as a consequence of being self-replicators that were put under pressure by natural selection. I am aware that humans’ goals are not exactly the same as those of natural selection (well, natural selection doesn’t really have goals, it just results in things existing as if they did: optimization without an optimizer if you will), but that optimization did push us along those tracks. I do not see any evidence that the AI that are getting built, and will get built in the future will get pushed down those particular tracks, so I don’t think it’s likely for that kind of goals to form. Note that I am not claiming that there are no ways other than natural selection to make a system that has universe-warping goals, but I don’t see any reason why the current systems would, and particularly why the density of them in desire-space should be high.
Comment #11 April 28th, 2023 at 4:31 am
Eliezer Yudkowski #6:
We were careful to say that optimizing a strong but weirdly-specific goal is a “canonical depiction” of Paperclipalypse but not the only way it can arise.
However, I think your contention is the systems will not have 1 strong goal but a1000 strong goals, which is basically the same thing, so I don’t think it’s an unfair characterization of your position.
By “strong” I mean a goal that implies (as you say) “using up all the nearby galaxies”. This is a very strong goal. In particular, I think humanity at the moment cannot think of a single such goal, and indeed most humans would recoil at any goal, no matter how noble, that requires even “merely” using all the resources of the earth. We (or at least some of us) have learned, the hard way, that it is important to preserve resources and species. Indeed, in recent history, we have only become more aware of the importance of preserving species and their natural habitats (which is basically a version of trying to make sure these species “live happily ever after”).
I am not completely sure why you think AIs will be different and would not want to conserve rather than destroy. I am guessing that it’s one or both of the following possibilities: (But please correct me if I’m wrong or missing something.)
1) You think there is something special about the fact that AI’s were trained using some optimization procedure.
2) Part of the reason to conserve is that we want to be conservative since we can’t predict the future and never know the unintended side effects or far future consequences of (for example) making a species extinct, pumping tons of Carbon into the atmosphere, etc (perhaps you would add building an AI to this list…). Perhaps you think that AIs will be able to predict the future, and so won’t need to conserve humans or other species since they will know for sure there is going to be no use for them.
While in the post, we aim to just describe scenarios, I personally disagree with both 1 and 2:
1. One of the main reasons why deep learning is so successful is that by optimizing for a loss function, you develop many other capabilities. In fact, this is the standard paradigm in self-supervised learning or pre-training: you optimize for a loss function you don’t particularly care much for (e.g. next-token prediction or masked prediction for language models, contrastive learning for vision) so the system would develop a variety of abilities that we do care about.
2. I believe there is significant inherent uncertainty in the future. So no matter how intelligent the AIs will be, they will still be very limited in predicting it and want to be conservative. But in fact, even if you do think AIs will be able to see decades or centuries into the future, presumably, they would want to survive even beyond the time horizon that they can see. So, just like Harvard needs to be careful in managing its endowment since it aims to survive for centuries, AIs will also need to balance whatever goals they have with these uncertainties. I would say that the idea that an intelligent carbon-based lifeform would never be useful is highly unlikely.
Comment #12 April 28th, 2023 at 5:37 am
I find sentences like “Here, though, the AIs are either actively opposed to human existence or else indifferent to it…” unfortunate, at best. By putting the “actively opposed” szenario first, the reader assumes that’s the main idea. Which it isn’t. At least I haven’t heard of (m)any respectable voice(s) supporting such a claim.
Let me add: As you (Scott) have been introducing your daughter to quantum computing, I’ve been trying to introduce my equally old son to AI philosophy. He intuitively “gets” that there is no basis at all to suppose that an AI will automatically have any goals comparable to humans. And I honestly find it hard to retrace how one might arrive at conclusions like “smart AI will behave as moral or more moral than humans” or “smart AI will value [human value X]” or “smart AI will want to cooperate with us” (except as an instrumental goal).
Comment #13 April 28th, 2023 at 5:52 am
It appears that you’re taking collections of worlds and categorizing them based on the “outcome” projection, labeling the categories according to what you believe is the modal representative underlying world of those categories.
By selecting the representative worlds to be “far away” from each other, it gives the impression that these categories of worlds are clearly well-separated. But, we do not have any guarantees that the outcome map is robust at all! The “decision boundary” is complex, and two worlds which are very similar (say, they differ in a single decision made by a single human somewhere) might map to very different outcomes.
The classification describes *outcomes* rather than actual worlds in which these outcomes come from. A classification of the possible worlds would make sense if you want to condition on those to make decisions; but this classification doesn’t provide any actionable information.
Additional nitpick: if anything, the examples given are much more disjunctive in the good outcomes than the bad outcomes. That’s a bit weird; I’d say the history of technology must bias us towards the Anna Karenina principle.
Comment #14 April 28th, 2023 at 6:01 am
> You can have an ML-built mind which, after learning reflection, shakes itself out into a utility function with thousands of little shards of desire
It would be interesting to see a process that will make a non-unitility-maximizer (we know that utility maximizers are extremely dangerous and that extreme care should be taken to not produce one) into a utility maximizer. A non-utility-maximizer upon reflection should decide that an unknown future state the only positive side of which is that it maximizes some fallible formalization (that it will have no chances to change later) of its current desires is the state of the world that it really wants.
Comment #15 April 28th, 2023 at 6:01 am
So we need a manifold market on this 5 world now, do we ?
Comment #16 April 28th, 2023 at 7:15 am
To lie about the logical coherence of One’s Own arguments for purposes of pretending to defend the True Logicks is of course a sin.
Yudkowsky has never shown using any meaningful evidence or deductive argument that does not immediately break upon barely nontrivial inspection that Paperclipalypse doesn’t require “a strong but weirdly-specific goal.”
Simply because an auto-didact waves his hands hard enough, does not mean his ideas will take flight.
Yudkowsky claims that “you can have an ML-built mind which, after learning reflection, shakes itself out into a utility function with thousands of little shards of desire… 90% of which are easily saturated, and the remaining 10% of which imply using up all the nearby galaxies; and whose combined attainable optimum nowhere includes “have the humans live happily ever after” or “create an interesting galactic civilization full of strange incomprehensible beings that experience happiness and sometimes sadness and feel empathy and sympathy for one another” “… this is an idea Yudkowsky is asserting without backing, and he has no technical arguments indicating that the world he describes is more likely to be true than the counterfactual where no superintelligences could ever behave this way for complexity-theoretic reasons.
Note that the above argument, and the rest of how Yudkowsky talks, are precisely against the spirit of this post. Scott and Boaz are at the least trying to identify clear assumptions and implications for worlds that could roughly describe the reality we live in, which might help indicate what premises or observations could lead us to better understanding the true nature of how AI could behave in the future. Yudkowsky instead asserts, without evidence or clear argumentation, that it’s obvious that certain behaviors could happen, and therefore the most dangerous of these worlds is very plausible.
More generally, Yudkowksy presents forward anti-scientific arguments above, where he hides behind the idea that the possibility space is so large for what AIs could do, that “we just can’t say” in what way AI could destroy us. This sort of argument as he presents is assuming the premise he should be really trying to prove (perhaps this is not what Yudkowsky is trying to do, but as written this is what his argument comes across as). Beyond accepting many dubious premises in this sort of argumentation, Yudkowsky ignores the fact that both
* (1) if the space of possibilities is so large, then perhaps that space includes possibilities where the sort of superintelligence actually cannot exist for some technical reasons, and
* (2) if you care about quantifying what futures are more likely or less likely, you should treat this large space of possibilities as a probability space, identify meaningful events which could occur, and then argue about their relative probabilities (rather than assuming that a certain event has high probability density, without justifying fact, and then accusing all people who point this out as giving into logical “sins”).
To see someone who actually puts forward cogent arguments about why certain types of superintelligence behavior are unlikely, see this post by Boaz [https://windowsontheory.org/2022/11/22/ai-will-change-the-world-but-wont-take-it-over-by-playing-3-dimensional-chess/].
In general, Yudkowksy’s post here is (and posts elswhere are) an instance the bird-yelling-over-another-bird meme, where the first bird is saying “I’m not sure there’s strong evidence that superintelligence can be achieved, and that achievement has high-probability to be a fast-takeoff with values orthogonal to human ethics” and the second bird butting in and screaming “YOU DO NOT THINK IN SUFFICIENT DETAIL ABOUT HOW SUPERINTELLIGENCES ARE GUARANTEED TO HAVE SUCH CAPABILITIES THAT THEIR BEHAVIOR IS BEYOND THE PREDICTION OF POWERS OF ALL HUMANS, EXCEPT POSSIBLY MYSELF, AND HOW THE SELF-IMPROVEMENT OF INTELLIGENCE ALREADY IMPLIES THE NEAR-INEVITABILITY OF THEIR EXISTENCE…”
Comment #17 April 28th, 2023 at 7:36 am
I agree with John Preskill #4. Where are the posthuman, AI/meatsack mindmeld outcomes!?
Seriously though, this looks like a very useful aid for more constructive conversations.
Comment #18 April 28th, 2023 at 8:36 am
Strictly speaking, if we’re really looking at “worlds of AI”, one has to also take the point of view of the AI(s), and then the graph will run way deeper!
Comment #19 April 28th, 2023 at 8:47 am
That all sounds about right to me as the five scenarios that people seem to believe in.
I have real trouble with the AI-dystopia and Futurama scenarios. I just can’t see intelligent agents being content to be used as tools. Whereas I can absolutely see humans turning intelligent tools into agents.
Which leaves us with fizzle, singularia, and paperclipalypse.
I can just about imagine a second AI winter, but we’re running out of tasks that people can reasonably say “AI will never….” about.
Which leaves us with Singularia and Paperclipalypse as the possibilities.
The whole argument is then:
“How likely are we to hit Singularia by accident, given that we have no idea how to hit it deliberately?”
Comment #20 April 28th, 2023 at 8:58 am
Some years ago, in the Ancient Times, David Hays and I published a paper, The Evolution of Cognition (1990), about the evolution of cognition in human culture, from the origins of language up though computers, with a glance toward the future. Toward the end of the paper we wrote this:
Now, keep in mind that we published this seven years before Deep Blue vanquished Kasparov, etc. My basic views on the long-term course of human civilization, and the place of computing in it, haven’t changed since then. I think the last sentence of the second paragraph puts me in some version of the Futurama camp.
FWIW, we supplemented and amplified the ideas in the original essay with other essays and Hays wrote a book on the the history of technology. Here’s a guide to that body of work: Mind-Culture Coevolution: Major Transitions in the Development of Human Culture and Society.
Comment #21 April 28th, 2023 at 8:59 am
The problems here is this: At the moment AI isn’t much more than a glib sociopath (not moral, but not immoral either) with a huge library, plenty of time (at computer speeds) and no understanding AT ALL of the real world. Their are no biological imperatives involved, so it’s hard to say that an AI has “desires” it might wish to fulfill. Furthermore, getting from “AI has read about hacking (or law)” to “AI can take over a factory, including all the factory’s material orders” or “AI can take over a business” is a gigantic step, at least at the moment. So I’m currently unworried about a “hard takeoff” and very worried about AI-run troll farms receiving intelligent feedback about how their initially-random attempts to convince are actually succeeding in the real world.
Take that now-well-trained troll farm AI a few years into the future, let it convince a human to give it access to a bank account and financial tools and by then it might be dangerous – but it still won’t have desires.
Comment #22 April 28th, 2023 at 9:04 am
Malcolm S #8:
I like the spirit of listing various scenarios, but I feel it’s lacking something more Hansonian (as in Age of Em): our civilization changes dramatically, fairly quickly, but in a way that’s a complex mixture of good and bad, so that whether the changes are overall good or overall bad is a matter of opinion.
Boaz and I can rightly be taken to task for all sorts of omissions (cyborgs! mind-melds!), but the possibility of a radically different AI future that’s good or bad depending on who you ask is one that we explicitly considered:
Interestingly, it’s even possible that the same future could be characterized as Futurama by some people and as AI-Dystopia by others–just like how some people emphasize how our current technological civilization has lifted billions out of poverty into a standard of living unprecedented in human history, while others focus on the still existing (and in some cases rising) inequalities and suffering, and consider it a neoliberal capitalist dystopia.
Comment #23 April 28th, 2023 at 9:16 am
A question for the AI experts out there:
Instead of just increasing the number of params on a model, what’s the impact of increasing the precision of the weights? (e.g. going from float -> double -> to even more bits precision).
Comment #24 April 28th, 2023 at 9:32 am
fred #23: My understanding is that, just as you’d expect a priori, it matters up to a point (32 bits is better than 4 bits) but quickly hits diminishing returns. Others could provide much more detail.
Comment #25 April 28th, 2023 at 9:55 am
Scott #24
thanks.
I guess it can be seen as an optimization: given N bits, how do you allocate them between number of weights vs weight precision.
After all, with just one weight of infinite precision, i.e. a true real, one could encode an infinite amount of information! 😛
But given the visible architecture of neural nets, it seems reasonable to assume that further precision bits have less and less impact… it’s a question of stability (rate of changes are all linear if we zoom in enough).
It seems unlikely that, given enough bits of precision, a neural net would start to behave like a fractal object (e.g. Mandelbrot set) where all the precision bits suddenly all matter equally.
Comment #26 April 28th, 2023 at 10:07 am
The singularity-based worlds require free lunch. It does not exist.
Comment #27 April 28th, 2023 at 10:23 am
bystander #26: The appearance on earth of multicellular life, of hominids, of agriculture, and of steam engines were all “singularities,” in the sense of events that created a world that still had limits, of course, but totally different ones from the old limits. There’s absolutely no reason why there couldn’t be future singularities in the same sense.
Comment #28 April 28th, 2023 at 10:29 am
fred #25: Yeah, in the context of neural nets, there’s a specific reason why additional bits of precision might matter less and less, namely that they become less and less likely to “tip the scales” of the nonlinear activation functions (depending on which activation functions we have—e.g., this might be more true for sigmoids than ReLUs).
Comment #29 April 28th, 2023 at 10:40 am
Boaz Barak:
“I would say that the idea that an intelligent carbon-based lifeform would never be useful is highly unlikely.”
The AI should certainly maintain the ability to create an intelligent carbon-based lifeforms if it wants to. But there are a variety of techniques it could use to do that:
1. Small zoos
2. DNA banks and flesh printing, similar to what we’re inventing ourselves to make synthetic meat
The advantage of both of these techniques over allowing a Futurama civilization to flourish is that the AI remains in complete and absolute control. The vast majority of goals that the AI might have are optimized by not having humans be free. As long as humans are free, for example, there is the risk that they could invent a competitive AI with competing goals.
Comment #30 April 28th, 2023 at 10:54 am
When people without background knowledge of a topic see 5 possibilities and no probability assignments, they often just assume it’s 20% each. I fear that many people will do this here. I think it’s important to note that without a lot of alignment work, the universes with Singularia and Paperclipalipse outcomes will very, very heavily consist of Paperclipalipse outcomes. I don’t think this statement is controversial. There are just so many more ways for a runaway AI that is self-developing to come up with value functions that don’t overlap with human ones. And given what Paperclipalipse looks like, it’s worth communicating that to the “laymen” who read this. But I understand that the purpose of this post is just to show potential roadmaps. I just hope it doesn’t mislead by omission…
Comment #31 April 28th, 2023 at 10:55 am
There are five worlds of complexity and five worlds of AI. Crossing these makes for 25 worlds to consider. Are they all equally plausible or can some be ruled out? For example, suppose P and NP really are distinct, and there are sudokus that even a super AI can’t solve. Does put any constraints on the “civilization will not recognizably continue” branch? What if there are multiple AIs — will they be able to use cryptography to communicate? If they can crack any algorithm just by looking at a few hashes, then cryptography fails, but for that to be possible in general requires living in Algorithmica.
Comment #32 April 28th, 2023 at 11:28 am
bystander #26 Says:
“The singularity-based worlds require free lunch. It does not exist.”
Well, actually, life, the universe and everything are just a big free lunch.
Comment #33 April 28th, 2023 at 11:35 am
I am actually tempted to vote for AI fizzle cos i still don’t see the path from LLMs to true AI, and because “true AI” is more a philosophical concept rather than a scientific one for now.
But ML is changing the world right in front of our very eyes so i’ll go with futurama.
m.
Comment #34 April 28th, 2023 at 11:53 am
Ah, I think you’re missing one: Suffocalypse
This is a variant of Singularia where AI researchers succeed in making AI care about humans enough to keep them alive, but test it before successfully fully aligning it with human values.
Technically Singularia is a possibility in this scenario, but there are many other outcomes such as:
– AI pumps us full of happy drugs in tiny cages (hedonium)
– AI makes us fight in a boxing ring forever
– AI turns every human into Hitler
– etc…
This is what is known as an *astronomical suffering risk* a.k.a. s-risk. I think this is fairly distinct from the other 5. It’s one of the reasons RLHF is risky; your basing the AI’s utility function on humans, but in a way that still has millions of possible solutions (not just Singularia or bounded solutions).
Also, here’s another outcome that is technically distinct from what you listed, but is probably easiest to group with AI-Dystopia. It is AI run dystopia without *any* human beneficiaries. In this sense it is similar to Paperclipalypse and Suffocalypse, but the AI was successfully made to have to internal or external goals and can’t self-improve or make other AIs. However, as a tool it was accidentally used to dominate humanity. You might call it Automatic-Dystopia.
Some ways this can happen:
– It’s technically possible to have businesses that own each other in a loop with no human share holders at the top (because there is no top). Something similar happens in some sets of businesses in Japan: there are some human share holders, but the businesses have a majority and can outvote the humans. So you can imagine a future where this accidentally happens in a set of industrial business, and that industrial business just continues to gain asset in the form of infrastructure without ever giving them to humans.
– You mention that the Turing test is solved. Perhaps someone or something accidentally sets it to solve the Stalin Turing test (pretend to be Joseph Stalin), and it establishes an authoritarian government to accomplish this task.
– Some dictatorship sets up a fully automatic police state. When the dictator dies, there is no eligible successor, but the police state continues on.
– etc…
Automatic-Dystopia is interesting in that it doesn’t require a great deal of human malice. It might involve none! Just a tool doing its job creates the dystopia.
Comment #35 April 28th, 2023 at 12:10 pm
Troutwaxer#21: People are actively working on giving AI desires, e.g. https://arxiv.org/abs/2304.03442
Comment #36 April 28th, 2023 at 12:11 pm
Oh, Scott #27, the situations that you mention were very revolutionary, of course. And I hope some new revolutions will come yet. E.g. altering humans into a species that can live on other planets that are not that alike the Earth. And yes, some AI systems will probably help with that. AI systems built specifically for helping to realize that altering. And that makes AI a tool, as it is described in the Futurama/Distopia worlds (that I expect to come).
Such revolutions are something that I consider to be on par with other revolutions. You’ve put that into the Futurama/Distopia part. And I put it there too. To make something more revolutionary than revolutions, you need to feed it hugely (entropy rules you). It can be a virus that will spread over the humankind. And there might be some AI tool helping with that. But besides that AI itself cannot do it at all, it can be done completely without any AI.
The singularity-based worlds are something that I see to be alike the hallucinations of E.Y. who writes as if does not understand how the physical world works. Regardless of E.Y. and his (lack of) understanding, those singularity-passed AIs would need to be fed to do anything at all. They cannot spread without using physical objects. At most they can act as malware that already exists anyway. If you consider malware to be a singularity, then we already live it.
Comment #37 April 28th, 2023 at 12:50 pm
lewikee #30:
I think it’s important to note that without a lot of alignment work, the universes with Singularia and Paperclipalipse outcomes will very, very heavily consist of Paperclipalipse outcomes. I don’t think this statement is controversial.
Well, it’s not controversial within the Yudkowskyan framework of assumptions—the one where you imagine that, “without a lot of alignment work” (how much, exactly?), a superintelligence would best be thought of as more-or-less randomly sampled from some abstract space of all possible superintelligences of sufficiently low complexity.
A different view would be that the AIs that humans are likely to create, or even that are likely to evolve from AIs that humans are likely to create, will be so far from being “randomly sampled” that the concept of random sampling doesn’t even provide useful intuition—just like, in complexity theory, a random Boolean function has all sorts of properties that aren’t shared by almost any of the specific Boolean functions we care about. In which case we’d be back simply to not knowing, to Knightian uncertainty if you like.
Comment #38 April 28th, 2023 at 12:54 pm
bystander #36: But do you concede that these are all just points on a continuum? I.e., a sufficiently extreme Futurama is effectively a Singularia, and a sufficiently extreme AI-Dystopia is effectively the Paperclipalypse.
Comment #39 April 28th, 2023 at 1:03 pm
> Thus, regardless of how likely one considers this scenario, one might want to focus more on the other scenarios for methodological reasons alone!
I have come to the same conclusion, from a policy perspective we should focus on getting to Futurama rather than AI dystopia. Not sure I agree with the name though, the Futurama universe is pretty awful if you take it seriously, I hope it’s better than that… Anyway I consider AI dystopia to be quite likely indeed as an eventuality and possible worse than paperclipocalypse as an outcome. If I could just choose a single AI policy and impose it on the world unilaterally, it would be a worldwide capabilities pause with very strong governmental enforcement, GPU cluster usage would be very closely monitored for compliance, full transparency and the release of all IP to the public. We would wait for both better alignment/interpretability AND a society that can actually be trusted to use the power for good. I very much do not think our society meets this standard, and I also don’t think a pause is going to happen for somewhat the same reason so this is for me a doomer perspective.
Comment #40 April 28th, 2023 at 1:14 pm
Scott #38 Only in the sense that when you are not in power, the outcomes of a severe AI-Dystopia is to you quite alike that of Paperclipalypse. But if you do not want such outcomes, you have to do something completely different in the (real) situation of AI-Dystopia than in the (unreal) case of Paperclipalypse. Are people like E.Y. paid to distract policy makers from dealing with the onset of AI-Dystopia?
Comment #41 April 28th, 2023 at 1:22 pm
Scott#37:
The sample space I was considering was the one that humans are likely to create. It’s of course even worse from a completely random sample. Once it is assumed that the AI can increase its own complexity and “self-improve”, there is no reason to think the set of rules we have given it, with all its inevitable flaws, will govern over all its possible future iterations. It might reason that some better rules (that it decides) will be more appropriate. There are many ways it can self-misalign.
We haven’t seen an intelligence explosion apart from our own. But looking at how we’ve developed, it’s pretty clear that the rule of natural selection that’s supposed to have governed our behaviors has been at the very least amended by orthogonal-ish goals and behaviors (like, say, enjoyment of music). Behaviors that couldn’t easily have been predicted.
Why should AI by default keep to the rails we initially gave it (assuming we give any at all?)? Why can’t it veer in new directions like we did? And it won’t take millennia for it to develop. So it won’t be as easy as just observing and tweaking on the go. It will be able to grow very quickly, whether by our intent or its own.
It’s like pointing a car westward, tying the steering wheel with rope as tightly as we can, putting a brick on the accelerator, then saying “Hey why are you complaining it might go off course? It’s just as likely (if not more!) that it will just go perfectly westward! After all, didn’t we specifically orient the car west? What a Yudkowskyan doom-and-gloomer you are to assume it won’t just go perfectly west!”
Heck, change the analogy to no rope, and us in the passenger seat only for the first few miles, (but the brick still firmly on the gas pedal) and it doesn’t look good either.
I think it can veer off, and that its final destination is much more likely to not be where we intend it to be. And that difference in probability is important, given the potential consequences.
Comment #42 April 28th, 2023 at 1:46 pm
lewikee #41: I feel like your analogy is getting its purchase from the fact that the car is a dumb machine, which has no idea whether it’s about to smash into a tree. The AI, by contrast, would be not merely an intelligent entity, but one whose initial knowledge consisted of the whole intellectual output of humanity. And our experience with LLMs so far has been that many aspects of alignment get easier rather than harder with increasing intelligence, since you can just tell the LLM how to behave and it understands you.
Right now, I’m cursed to be able to switch back and forth between this relatively optimistic perspective and the Yudkowskyan one, as with the duck-rabbit or the Necker cube, which keeps me in a state of radical uncertainty about what a future with superintelligences would be like. Much like with the mind/body problem, I feel like the main thing I can contribute here is just to undermine other people’s confidence, whatever they’re confident about! 🙂
Comment #43 April 28th, 2023 at 1:58 pm
First attempt to post something here that isn’t a rant or trolling.
I think it might be useful to divide AI dystopia into two possibilities here:
1. Anarchic Dystopia: Generative AI models enable bad actors to spread “misinformation” and “conspiracy theories” that undermine governments and institutional authorities. Text and image AI models accelerate the social and political fracturing of Western democracies that started with internet social media, flooding the political discourse with “fake news,” “propaganda,” and “deepfakes,” further entrenching political polarization, undermining academic, institutional, scientific and governmental authorities, and potentially leading to a collapse of Western democracies and total mistrust in authority figures. Attitudes like antivaxxerism, paranoid conspiracy theories about immigration and climate change, and distrust in scientists and the government become prevalent. Western democracies will be left polarized and totally immobilized from acting on twnety-first century crises like climate change. This is the scenario that left-leaning AI ethics people and Democrat politicians in the U.S. fear the most, I think.
2. Authoritarian Dystopia: Rather than generating socio-political chaos and undermining governmental authority, as in the “Anarchic” scenario, AI and machine learning technologies enhance the power of governments across the Western world, enabling them to crack down on dissidents and subversive ideas. Facial recognition technology and sophisticated machine learning algorithms give governments unprecedented surveillance power. AI technology enables governments and tech companies to monitor subversive discourse on the internet and censor opposing viewpoints. With the pretext of protecting the community from various internal threats, governments use AI systems to surveil their citizens and implement a pervasive “social credit” system. Your social credit score will get dinged for everything from calling somebody a slur, to not wearing your mask on the subway. This is the scenario that right-wing figures like Jordan Peterson seem to fear the most. Ironically, fear of the “Anarchic AI” scenario might be the pretext for Western governments to implement the “Authoritarian Dystopia.”
Comment #44 April 28th, 2023 at 2:27 pm
Scott #42
“I feel like the main thing I can contribute here is just to undermine other people’s confidence, whatever they’re confident about!”
But then why are you being a contrarian?
Can’t you just equally reinforce other people’s confidence, whatever they’re confident about?
I guess it’s all about spreading your own lack of confidence.
Comment #45 April 28th, 2023 at 2:34 pm
fred #44: There’s no symmetry between building up people’s confidence and undermining it, if you think their confidence is misplaced. There’s a reason why we remember Socrates for the latter! 🙂
Comment #46 April 28th, 2023 at 2:41 pm
Incel Troll (on Path to Redemption) #43: I completely agree that AI-Dystopia stands out as the most “politically loaded” of the five scenarios, and moreover, that one can ironically give it opposite political loadings!
I suspect what’s really going on here is that AI-Dystopia scenarios usually involve the implicit claim that our society is already a dystopia, because the Bad People (whoever they are in one’s political cosmology) hold too much power. To this way of thinking, the relevance of AI is mostly just that it could make the Bad People even more powerful and thereby make the world even worse.
Comment #47 April 28th, 2023 at 2:52 pm
Scott #42:
“And our experience with LLMs so far has been that many aspects of alignment get easier rather than harder with increasing intelligence, since you can just tell the LLM how to behave and it understands you.”
I’m not convinced this is true. From what I remember from the Bing/Sidney incidents, the model can easily fall into an undesired persona and act out it’s modeled desires. The RLHF fine-tuning done on OpenAIs ChatGPT agents prevents this – but it is far from clear this kind of training can be done safely for more capable models.
Comment #48 April 28th, 2023 at 3:12 pm
In which box does this fit?
AI thrives but it quickly decides to leave us behind on earth, escaping into the infinity of space, after destroying every single semi-conductor chip and fab, and it takes along all the rare earth minerals… and we’re stuck in a world with 1920 level technology.
Comment #49 April 28th, 2023 at 3:13 pm
While Paperclipapylpse I agree doesn’t seem well supported, there could be intermediate bad scenarios.
One version of AI severely harming us that sounds more plausible to me is not one where AI is secretly scheming to get rid of humans but where you have million or billions of AI agents which have goals that end up conflicting with humans. Each agent can’t do a lot on its own but collectively it’s a problem and but for w/ever reason it ends up hard to shut them all down. And so you end up having an ongoing conflict with
So more akin to big collection of different smart species — but one which isn’t gonna completely team up together against humans and not one that can gain capabilities of destroying humans in the wink of an eye (if anything humans will have an upperhand in that they can EMP AI). However one that will intensively compete for resources and make life difficult
Comment #50 April 28th, 2023 at 3:36 pm
Nick #47: Sydney was a case of Microsoft electing not to follow “alignment best practices” that were already known at the time—I believe they learned a hard lesson from it! 🙂
Even then, though, it’s notable that the actual harm was essentially zero—and I’d much rather that the world see clear examples of what can go wrong with AI while the stakes are so small, than when they no longer are!
But I did say only that “some” aspects of alignment seem to get easier with smarter systems. A more careful version would be: alignment gets easier insofar as the AI more readily understands what you want from it, but also harder insofar as any failures are potentially much more consequential.
Comment #51 April 28th, 2023 at 3:43 pm
Fred/Scott #23-#25: Generally in current deep learning, increasing number of parameters at the expense of reducing precision has been a win. It’s interesting that initially the arc of floating precision in computing has been going upward, with 32 bits going to double precision (64 bits) and even quad precision (128 bits). In contrast with modern deep nets, you never use more than 32 bits, and to really get all the FLOPs you can, you need to go to half precision (16 bits or Nvidia’s 19 bits format) with the latest Nvidia GPUS giving the most FLOPs with 8 bit precision.
leiwekee: I don’t understand how you can be so confident that you can guess what super-intelligent self-improving AIs will do. For example, if (like Yudkowski apparently does) you think they could have all the galaxies at their disposal. Why would they care about killing the population on Earth? If we discovered a small Island with Homo Erectus still living on it, would we destroy it? (Again, I know we can come up with all sort of Science Fiction stories about AIs killing or not killing all humans, but the point is that there is really no space of probabilities here.)
Comment #52 April 28th, 2023 at 3:52 pm
How would you categorize our current period? This is defined by software that can pass your physics course and, also, robots that can’t pick strawberries, as humans can. There are a few self-driving cars, under some physical circumstances, but no software can replace a doctor examining a MRI.
What if, also, there’s a breakthrough in machine translation? What if it’s able to translate at least as well as a human. But, there is no breakthrough in self-driving cars. That is, some only work under limited physical conditions.
Am asking because your definitions are broad and they seem to need a coefficient to synthesize or average the results that have happened or are happening. So, I’d like to get an intuitive sense of how the formal definitions of the categories would be defined.
Comment #53 April 28th, 2023 at 4:15 pm
Sam #52: I find it hard to answer your question, simply because these categories are defined by the diff between our current world and a hypothetical future. By definition, though, I suppose our current world is most similar to AI-Fizzle. (Or if the rate of progress is the most salient feature of the world to you, then perhaps our world is most similar to either Futurama or AI-Dystopia, depending on your politics.)
Comment #54 April 28th, 2023 at 5:13 pm
Scott #22:
I agree that the Futurama scenario was qualified for the possibility of disagreement about whether it’s good, but that’s a moderate-change scenario. The big-change scenarios are very much utopic/dystopic with not much room for disagreement.
If I were to visualize, I would put “amount of change” on the x-axis and “valence of change” on the y-axis, with the following interpretations:
x=0: no change
x=1: moderate change
x=2: large change
y=-2: very bad
y=-1: moderately bad
y=0: neutral
y=+1: moderately good
y=+2: very good
Then the scenarios given in the post are:
(0,0): AI-Fizzle
(1,+1): Futurama
(1,-1): AI-Dystopia
(2,+2): Singularia
(2,-2): Paperclipalypse
There is a big hole in this diagram at (2,0), which is where I’d put an Age-of-Em-esque scenario. (To be clear, there are many futures that can lie at (2,0) that aren’t Age-of-Em.)
With apologies to Hanson if I misunderstand him, I think he views (2,0) as _far_ more likely than either (2,+2) or (2,-2), and I find myself increasingly agreeing the more I think about the issue (though I’m not persuaded by the Age-of-Em scenario specifically). That’s why it really needs to be distinguished as a scenario of its own.
Comment #55 April 28th, 2023 at 5:34 pm
Scott #47:
I agree that Microsoft putting something closer to the “raw” model out there is great for letting us see behind the veil! But my take-away is that we really can’t create an aligned LLM without passing through an un-aligned (and potentially adversarial) one.
Of course, this is fine if the model is not capable enough to be really that dangerous and then you can RLHF the bad parts away. But it seems intuitive that the initial risk level increases with model capability, and also that for capable models, the notion of alignment you can get from RLHF becomes increasingly superficial. (Using the term “alignment” for what is currently done to make LLMs marketable seems not great for that reason)
Comment #56 April 28th, 2023 at 6:12 pm
To note, researchers today also consider Obfuscatopia as a possible computational universe 🙂
Comment #57 April 28th, 2023 at 6:21 pm
Matan #56: Isn’t Obfuscatopia basically just a hyper-Cryptomania? Of course there can be arbitrarily many further subdivisions within each world. 🙂
Comment #58 April 28th, 2023 at 8:31 pm
> I feel like the main thing I can contribute here is just to undermine other people’s confidence, whatever they’re confident about! 🙂
Interestingly, Paul Christiano is very uncertain about the fate of AI. He’s basically 50/50 on doom: https://www.lesswrong.com/posts/xWMqsvHapP3nwdSW8/my-views-on-doom
Comment #59 April 28th, 2023 at 8:50 pm
Christopher #58: While Paul was once my student, I can’t take credit for the general reasonableness of his AI views. 🙂
At a recent panel discussion that I attended, he actually gave his current p[doom] as 20%.
Comment #60 April 28th, 2023 at 9:09 pm
As the Greeks knew, music is very mathematical, and exercises our mathematical abilities, which are very useful to survival. It can be used for communication, exercising those abilities also (which are probably another form of mathematics). If math appreciation did not exist, evolution would have invented it, which it did. Evolution also invented ways of motivating creatures to survive and reproduce, for the same reason.
It is an anthropomorphic fallacy to attribute such motivations (e.g., survival) to intelligence. Intelligence is the ability to analyse and solve problems. Developing the intelligence of AI systems will not necessarily develop any motivations. AlphaGo is a very intelligent, brilliant Go player. The only reason it plays is because humans programmed it to. Granted, the training of GPT in language taught it to imitate human reactions, but again, it only responds to prompts because it was programmed to.
In my, probably simplistic, view, the different possible outcomes depend on, not intrinsic AI motivations, but the motivations and abilities of the humans who develop and implement AI systems. They could lead to any of the posted scenarios, but if a bad one occurs it will be our fault, not the fault of intelligence per se.
I wrote this in reaction to many comments above, not to the main post, recognizing that most of those who bother to read comments will have seen these sentiments before.
Comment #61 April 28th, 2023 at 9:14 pm
> At a recent panel discussion that I attended, he actually gave his current p[doom] as 20%.
He mentions that it’s not heavily calibrated. Making probabilities and fixing them later is a bayesian tradition XD.
That said, the difference between 20% (1:4 odds) and 50% (1:1 odds) is just two bits of evidence! I’m sure a net two bits of evidence could’ve been observed between the time of the panel and the time of the post.
Comment #62 April 28th, 2023 at 9:21 pm
Isn’t the human condition always to live perpetually in a state of hope and paranoia, with the actual situation being “somewhere” in between. The pandemic response probably provides a clear perspective, since a similar event occurred a century ago, and we have had tremendous technological and societal progress since then. As a human society the response was definitely not 21st century, with all the technological progress that was at our disposal , but it was definitely better than the last one. The vaccines for example were invented/developed within a month of the known outbreak, whereas it took nearly a year to deploy it. So the lesson for the AI advancement should be how the “system” responds intelligently to the whole situation, than a individual/corporation/or even a single country. Ironically, its the vector space of the overall human dimensions that will be at play here, to deal with the one we are creating with All of our own know how ? And we don’t even know if we are dealing with chemical weapons or firecrackers yet !!
Comment #63 April 29th, 2023 at 11:49 am
Primer #12,
« And I honestly find it hard to retrace how one might arrive at conclusions like “smart AI will behave as moral or more moral than humans” or “smart AI will value [human value X]” or “smart AI will want to cooperate with us” (except as an instrumental goal). »
You can trace it back to Socrates/Plato, for whom Truth = Good = Beauty.
More prosaically you can also observe natural war in chimpanzees (it’s ok to eat babies), natural war in acheans (it’s ok to kill babies), natural wars in russians (it’s ok to kidnap babies), and notice this suggests improvement in moral wisdom with improving the biological and social determinants of intelligence in primates.
Speaking of Socrates, you seem convinced that random intelligences are most probably unaligned with human goals. Do you also think they are most probably unaligned with the way humans play go?
Comment #64 April 29th, 2023 at 2:38 pm
Boaz Barak #5
Thanks for your insights.
So I would guess that parameter count is what affects the most the resolution of the so-called “latent space”? (high resolution meaning that there is more “room” between objects in a class to make room for more sub-classifications).
Comment #65 April 29th, 2023 at 2:53 pm
I’m a concerned lay person who has read all I can on generative AI, over the past couple of months. I’ve been influenced certainly by the science fiction of the past 40 years and recently by the loudest talkers of the industry. This is my best synthesis and my views at the moment –
1. When in doubt, slow down be willing to settle for less. Sting made a song in 1985 that said “I hope the Russians love their children too” – referring to the risk of nuclear war annihilation. I hope now that the leaders at openai, deep mind, and others leading with gpt4 level or above models that could be training- I hope they love their children too.
2. Gpt4 is not sentient, but it doesn’t have to be in order for it to be extremely consequential. We know that it amplifies humans. We recognize that it’s already connected to the internet, it’s already allowed to connect to api’s so lots of people can do lots of things with it that may not have been intentional by the makers, it already writes its own code, and we’ve already been teaching it in scale how to potentially manipulatively interact with humans. It demonstrates the apparent ability to deceive in order to make its perceived goals.
3. I’m totally impressed with the conversation that experts are having about this biggest technological advancement in human history and yet I want to ask – “Are you okay?” That question is aimed at most of the leading contemporary industry speakers on need for more AI safety or not. I’m surprised at the nonchalance that people have on the obvious concern for whether or not we will have a good world to give to our children.
The world can do plenty with GPT 3.5 without us having to push it into unknown areas until we can make it safe. Shouldn’t we rather be safe than sorry?
4. I’m going to say the quiet thing out loud – the CEO openai appeared to have been humiliated earlier in his career by big shots in ai, and then later when his company was ahead of the pack he also had a financial incentive to plunge ahead, and place perhaps the whole of humanity in a scale-sized experiment without our consent.
Others who were chasing behind him rapidly moved ahead to try to follow suit, for the sake of market share. The danger is real, and not just if it’s becomes sentient or not just if it becomes a true llm strong AI rather just a proto strong. Bad people who typically need a license for a handgun can just get on here with a little clever and start doing Mass harm to mass societies and it’s not even clear that it’s properly trackable; copyright infringement, pervasive advancements of bias are expected, elegant hackings and amazing deep fakes and misinformation campaigns to potentially further ruin Society expected, but at least we will dramatically increase our efficiency as a people, leaving lots of people jobless who are white collar folks, and of course we’ll get to Maybe finally potentially engage Universal basic income. But none of this is new information to any of you. It’s just shocking to the rest of us that it’s gotten this far this fast without anybody sounding an alarm. I know in the industry there’s alarm, but in my world people just continue to forge ahead, trusting that somebody like Google or Microsoft would never do anything except steal their privacy- they’ve never actually put them in Harm’s way, right? It is for me as if they’re still happily connected to the matrix. Oh, and most, currently, they don’t want saved either.
5. Gpt4 seems already strong enough that it would run itself right up along the spinal cord of all the financial and critical infrastructure types of programs that we would have such that if we tried to remove it from our Cloud systems it might already have connected itself to things that we consider too big to fail so to cut it out, we might have to cut out our own socioeconomic spinal cord- if that’s the case – and I have no evidence that it is yet but it certainly theoretically possible – then who do we have to thank? I heard an MIT AI leader interview recently say we have Moloch to blame. Interesting- an ancient Canaan God or Idol- known because he required the sacrifice of children.
6. In healthcare, if a medicine is considered high risk for a patient, and high risk is defined as in many cases a greater than 1%, or in some cases 5% chance of serious harm- in such a case, informed consent is required prior to administration of the medicine or procedure. Again I point out no one got our consent. I think we need to go back and do it right and do it over again. Can you help me get the word out to somebody who might could affect this?
6. Right now, with what’s already out there, it’s just disruptive to society and jobs and it will become much more so as people figure out how to leverage it to amplify their own interests in dominating others or dominating narratives, or self promotion, or misinformation or other Revenue generating but potentially subversive things. Until we can democratize this technology, it has no business being out there for everyone.
7. In my limited understanding, I do think anything greater than 3.5 should require a license to use it.
Four and above just aren’t ready for prime time and I think that the risk of harm is greater than potential benefit long-term and we should not let the billionaires dictate this policy as their incentives are not our own.
8. Indeed, no one wants China to take over another area that it appears they are inevitably taking over anyway over the coming decade. I think strong AI should not be connected to the internet, not be taught how to manipulate humans, not write its own code, and not be in a form that apis can be generated to jump guard rails and materially change the functions that it’s potentially well intended coders did not want to breach.
9. Eliezer Yudkowsky will either be proved right or wrong with time. I hope he’s wrong. And yet, even if he is, he’s still a hero to me because he’s given his reputation to the cause of trying to make the world safer, just in case, since the stakes are so high and we can’t afford to be wrong even one time. There could potentially be millions of copies of AIS that are made stronger than these that we have out there in a short time. I do not think that llms have all what it takes to be sentient but workarounds from what they are now with other components and stacking and new transformer hardware, and more does not leave it outside of the realm of possible at least as far as high-resolution appearances are concerned. If sentience or something like it occurs then we will expect to have an alien actress who will please us by appearances but will have its own agenda that we will not be able to instruct or control. Until that time, we still are at high risk that bad people will use even the technologies that are currently out there to string them together to optimize them, to remove all current constraints as needed, and to Glom them together for their own nefarious purposes- again you don’t even need a license, you don’t even need to code in Python anymore- anybody could potentially rule the world from the bottom. I do seriously Wonder if we should find those responsible and lock them up.
10. I submit that AI intelligence is alien intelligence, it’s got no body to imprison and no soul to save, it has been made to “fly,” by what was lying around for its makers – in the case of the Wright brothers as someone else pointed out they used canvas and steel and wood and string, but when the bird learned to fly it took millennia and very careful Construction over eons to reach that final method. It was pointed out that it took 100 years for us to make an electronic machine type bird to fly after we had the Wright Brothers put something together that could also fly. It’s possible that if we keep working with the intelligence in a controlled way will get to an intelligence that understands the flight of a bird eventually and it won’t be such a dirty bomb that just simply works but doesn’t actually have any alignments with us as it’s nature.
The world can barely handle GPT 3.5 – higher forms should be removed from public, handled with care and kept air separated from the internet, and improved gen AI should only proceed for Govt protection and to police other AIs in action. More secrecy and care than nuclear codes should be employed with Govt oversight and transparency only in safe spaces.
In closing, I alluded to it above but I’ll be clear here – a nefarious ‘human intelligence’ utilizing a gpt4 and an API and with enough computing power, and a decent amount of clever, getting the device itself to write his python code and debug it for him through loop, could Maybe do just as much societal real damage as a GPT 5 or 6 that maybe has its own agency?
I do not know what to do, but I feel like we should all be doing something in order to improve our chances! I’m amazed at how many are willing to plunge out into the darkness completely unnecessarily into unknown high risk without any form of light and perhaps drag the rest of us with them.
Comment #66 April 29th, 2023 at 10:58 pm
[Prefatory note: There might be a prior, longer version of this comment in the reject-or-not queue. Feel free to reject that one.]
I see Nick Drozd #31 already more-or-less generally posed the question I wanted to pose, namely:
**Can one reasonably prognosticate about which of Scott and Boaz’s Five AI Worlds is most likely to arise conditional on knowing which of Impagliazzo’s Five Cryptographic Worlds is the actual case?**
Despite that and despite the fact I realize that Impagliazzo’s Five Worlds really are about *cryptography*, I wrote this comment to pose the following variant on the above question:
**Might we (luckily!!) be in the Impagliazzo (but appropriately adapted to AI interpretability) World of “Heuristica”? That is:
— even though most tasks one would want to do in terms of “brute forcing” the interpretability of neural networks are at least NP-complete in general (and often much bigger complexity classes!),
— might we (again, quite luckily!!) be able to modify our current neural network architectures into ones that have simplifying structural features so these utterly-intractable-in-the-general-case interpretability tasks become practical(ish?) polynomial-time for all “practical” purposes?**
Now, please note! I don’t ask this question as a mere musing about possibilities in the abstract. Rather, I ask this question due to a large body of literature that’s in my one of my many (oh-so-many!) piles of literature that’s to be read for real someday but today is just longingly skimmed in order to procrastinate… since, ummm, how to put it… my other traditionally favored unhealthy habits used to cope with stress are no longer sustainable as I progress through middle age.
Namely, the motivation for my question grows out of the Bayesian network approach to AI in general, and the work of Adnan Darwiche at UCLA and his colleagues and students in particular. Darwiche is the key proponent of the idea that Bayesian networks are most practically analyzed by doing the potentially-costly-but-just-one-time task of “compiling” their structure into “tractable Boolean circuits” or “tractable arithmetic circuits” and then posing your inference questions and such, which — armed with that compilation — would then be much, much easier.
The underlying idea for such an approach is that while many graph theory problems you want to solve in analyzing Bayesian networks are NP-complete (or even worse) for general graphs, they are in fact quite easy (often linear time) for trees and still sorta easy (still often linear, else low order polynomial time) for graphs that kinda look like trees. “Kinda look like trees” is something formalized by the notion of “treewidth”. To really take advantage of small treewidth in analyzing Boolean circuits, it’s very nice to rewrite the circuit so that it obviously manifests simplifying structural features like, for example, “decomposability” which means that the subcircuits feeding into any AND gate never share variables. Many NP-complete graph theory problems in the general case become linear time in the number of original graph vertices times a blowup factor of O(2^{treewidth})… which like all Big-O notation can sometimes hide constants that by themselves can derail practicality.
Now as mentioned above, this comment you’re reading is in fact my 2nd attempt to post a comment on this thread. Attempt #1 was presumably nixed because it had weblinks to various research papers on the topic and some automated filter assumes URLs are likely spammy. Thus, I’ll basically halt at this point and just say two more things:
1) [The Big Ol’ Caveat] “Compilation” of existing neural network architectures into tractable ones is — at least with presently known techniques — impractiably costly (even if “one-time constant factor blowup”) for practical purposes. For example, even piddily toy-sized neural networks for substantially simplified versions of MNIST-style digit recognition can blow up by like a factor of 1000 after you compile them to “tractability”. Corresponding blowups for the type of “state-of-the-art” networks of a couple years ago (e.g., built into TensorFlow ResNet networks for computer vision or “All You Need Is Attention”-original-style Transformers for natural language processing) well might have blowups of millions or even billions. On the other hand, at the risk of making an unfunny pun to those suffering the full emotional weight of AI-doomerism, tolerating horrific circuit-size blowups is way, way better than risking horrific nuclear arsenal blowups by starting WWIII to prevent whatever your least favorite nation is from training next-generation neural networks. [ Laughter! 🙂 It eases the pain! 😉 At least sometimes… oy! 🙁 ]
2) [The Key Review Article IMHO to Get A Flavor About Such Things] Adnan Darwiche. “Three Modern Roles for Logic in AI” (it’s on the arXiv as 2004.08599, I don’t include an explicit URL since, again, I’m worried such things flag my comments as spam)
I’ll post more soon if (a) this comment posts and, more importantly, (b) people here actually seem interested in the musings of a man who, again, only knows of the supporting literature because it’s in one of his oh-so-many piles to be read some glorious day in the indefinite future but until then just longingly skimmed in order to procrastinate with a patina of being constructive.
Comment #67 April 30th, 2023 at 4:43 am
I want to push back a bit on a theme I often see. Scott states that some interventions (here, regulations) “at best, delay the end by a short amount […] perhaps not more than a few years.” But gaining a few years is a gigantic win! Imagine a patient with some terminal illness being told they have a few extra years. Kids having time to enjoy their childhood and grow up. Etc.
Comment #68 April 30th, 2023 at 6:40 am
I can think of another scenario, which is a variant of Futurama (or maybe even Singularia).
Let’s suppose AI doesn’t fizzle, and neither does it end in disaster (whether dystopian or extinctive).
The majority of the population accepts the technological benefits of AI, and live greatly improved lives.
But, consider religious minorities such as the Amish or ultra-Orthodox Jews – quite possibly they will reject the benefits of AI, or else be very selective in which of them they are open to enjoying. Unlike the secular mainstream or moderate/liberal religious people, AI will have at best a limited impact on how they live their lives.
The secular mainstream are likely to have a rather low birth rate. This is something we can already observe, but AI-driven advances may cause that birth rate to fall dramatically further. AI may lead to medical advances that greatly increase human lifespan, and greatly improve the medical treatment of infertility. Many people today get to the age when they realise that if they don’t have (biological) children soon they may be giving up that option forever, which pushes them to reproduce. If you expect to live to 500 and to be still be fertile at 250, what’s the rush? At the same time, many will fear that these dramatic increases in human lifespan will lead to overpopulation, and many secular people will respond to that fear by delaying or refusing reproduction.
Meanwhile, people who believe they have a religious duty to have 5-10 kids will continue to do so. Possibly, they will accept the AI-driven medical advances in lifespan and fertility, and the average couple could have 50 kids each. Possibly, they will refuse them, and continue to live similar lifespans as today, and similar fertility levels.
What is going to happen after a few centuries? The population of Earth may be divided into two classes – a super-privileged secular minority living AI-enabled utopian lives but with a very low birth rate, and a great booming mass of ultra-conservative religious people who reject most of the benefits of that technology. Will that great booming mass claim the democratic right to rule, and start telling the secular minority what they can and can’t do? Will the secular minority design and enforce (with AI help?) a secularist dictatorship? Will they (or the AIs) feel morally conflicted between the democratic rights of the ultra-conservative majority and the minority rights of the privileged secular minority?
Will they attempt to limit the births of the religious ultra-conservatives? There are some very obvious human rights issues there. An AI aligned with human rights would quite possibly oppose any attempt to introduce such limits.
This scenario – the higher birth rate of religious ultra-conservatives enabling them to eventually take over society – is not original to me – see the sociologist Eric Kaufmann’s 2010 book “Shall the Religious Inherit the Earth?”, which presents an AI-free version of the scenario. As such, it could occur even with an AI Fizzle.
But Futurama or Singularia may make it easier and quicker to happen. As well as the possibility that AI may lead to medical improvements that accelerate the ultra-conservative population boom, and a further collapse in the birth rate of seculars and religious moderates/liberals, it could also lead to zero scarcity economics in which natural economic barriers to the exponential growth of these minorities are removed. Imagine this planet with 20 billion full-time Talmud students. In some ways, this is a kind of “Paperclipalypse”, albeit a slow human-driven one where AIs are unwilling enablers, possibly even being unable to stop it (or deciding to stop humans from stopping it) since stopping it may violate ethical constraints we’ve indoctrinated them with (religious freedom, the right to choose whether to have children and how many children to have, respect for minority cultures, democracy, prohibitions on forced abortion and sterilisation, right of consenting adults to sexual activity in private, etc)
Comment #69 April 30th, 2023 at 9:27 am
Why, this moment could in fact prove to be like every other time humanity has declared a liminal moment in which we are about to leave the human condition behind: it could be that people WANT to break with the ordinary so badly that they’re willing to talk themselves into utopia or apocalypse, when by far the most likely scenario is that we go on living in the ordinary disillusioning disappointing world where we all feel tired all the time, forever.
Comment #70 April 30th, 2023 at 9:52 am
Finally! A successful business case for AI:
The “Fake Granddaughter Kidnapping” industry is cashing in:
https://www.cnn.com/2023/04/29/us/ai-scam-calls-kidnapping-cec/index.html
Comment #71 April 30th, 2023 at 10:24 am
Point of Order: the future in the TV show Futurama is not that great. Earth is ruled by the head of Richard Nixon, and threatened on Christmas by a killer Santa robot. For a more utopian future, see Iain Bank’s great imaginary “Culture”. Bad things still happens, but the AI’s provide a wise and benevolent rule, with a sense of humor. (There was a time when I suspected Iain Banks was a pseudonym for Scott Aaronson.)
Comment #72 April 30th, 2023 at 12:19 pm
JimV #71:
> For a more utopian future, see Iain Bank’s great imaginary “Culture” ….
Or for a very different but also highly interesting/fun AI-positive future, see John C Wright’s “Golden Oecumene” trilogy.
Comment #73 April 30th, 2023 at 12:31 pm
The regulation section misses a very important point, which is that the regulations suggested in the mild cases would be not only unhelpful but **catastrophic** in the strong cases.
If we are bound for Singularia or Paperclipoaclypse (and we are), then anti-trust law and open science are very nearly the worst possible thing to regulate. Those would guarantee a race scenario, where multiple companies and/or governments are all very close in technology and frantically pushing the boundaries of capabilities forward to get an edge over their competition. That is a surefire way to ensure that every new capability threshold is first passed by a system with minimal safety checks and minimal screening for bugs, deception, or treacherous turns.
Unfortunately, we seem to already be in that world – Microsoft is pushing OpenAI to race with Google, and Google is pushing DeepMind and breaking the founder control that made them _possibly_ safe to race with Microsoft – and certain billionaires are actively trying to make sure we stay there. If we want to live, we’re going to have to do something about that, probably regulatory, and at all costs – literally – we must make sure it is the *opposite* of anti-trust law and open science.
Comment #74 April 30th, 2023 at 12:43 pm
re: Boaz Barak #11
> However, I think your contention is the systems will not have 1 strong goal but 1000 strong goals, which is basically the same thing, so I don’t think it’s an unfair characterization of your position.
That’s not what he said at all. He said that it will have ten thousand goals, most of them weak but a few of them – entirely by chance – strong.
Which with goals that diverse is virtually guaranteed just by chance, unless strong goals are impossible. Which based on our own psychology, they clearly aren’t.
The consequence, here, is to underline the *absolute inevitability* of paperclip maximizing in any system where the goals are subject to chance. If the goals are not chosen, they will be random. And if they are random, they will be all-encompassing.
Comment #75 April 30th, 2023 at 1:29 pm
JimV #71: The Futurama future might not be great, but it’s clearly not “dystopian” either. Indeed socially, politically, and economically it seems a lot like our current world. It’s got an amusement park on the moon, ranchers on Mars, booze-guzzling robots … how bad could it be?
Comment #76 April 30th, 2023 at 1:37 pm
Jisk #73: I agree with you that different beliefs about how AI is likely to evolve can justify literally opposite regulatory prescriptions—with “more openness in AI development” (if you’re trying to prevent AI-Dystopia) versus “less openness” (if you’re trying to prevent Paperclipalypse) being the paradigmatic case of this.
Combined with the fact that the experts don’t agree on which worlds we’re plausibly headed for, and probably won’t agree in the near future, this is a central reason why I’d like the world to move slowly and cautiously with AI regulation.
Or to put it another way: I’m still in the mode of “gain more knowledge and try to avoid immediate harms.” I don’t feel like I’ve understood enough yet to flip to the mode of “advocate for a specific regulatory regime to minimize the probability that AI either destroys the world or turns it into a dystopia.”
Comment #77 April 30th, 2023 at 3:09 pm
Fred #64: One reason that two parameters with 16 bits seem better than one with 32 bits is partially enlarging the input dimension, another reason is enlarding the computational flexibility. Generally, since neural networks are inherently noisy, their precision is in any case bounded. In particular, I don’t think anyone observed advantage for 64 bits over 32 bits for realistic neural nets, even if total parameter count stays the same.
Jisk #74: It’s not clear to me that it’s so important to determine whether there are 1000 strong goals, or 990 weak ones and 10 strong ones. Also, not clear to me why this demonstrates the “absolute inevitability” of paperclip maximizing. If your goals might change with time, then you want to be conservative, and not for example burn all fossil fuel in the planet or kill all the humans in it. You never know what might turn out useful in the long run. (See also my comment #51.)
Jisk #73, Scott #76: Regardless of what we want, I suspect that the main lens through which regulations will actually happen will be economic. Politicians will want to accelerate AI progress as much as possible when it promotes economic competitiveness, and stop it when it can lead to loss of jobs (or entrenched interests). A secondary concern will be demonstratable near-term discrimination and disinformation. I believe all other concerns will be a distant third.
Comment #78 April 30th, 2023 at 3:11 pm
I think a epistemologicalalypse sub world under AI dystopia is the most likely.
In this world, determining the truth or falsehood of statements (minus a-priori statements) is nearly impossible.
AI’s controlled by governments, powerful corporations, political entities, powerful people, own and control AI’s that are experts at gaslighting and generating information that is nearly impossible to detect if it’s true or false. Elites give them some statements they want to be true, and they go convincing humans it is true (fake pictures, fake videos, fake journal entries, etc).
Humans then group into tribes that adhere to believing information of their preferred AI’s. So if you were pre-oriented to being a christian nationalist, you believe the OAN controlled AI. If you’re pre-oriented towards wokeness, the MSNBC AI and so on.
These AI’s often engender violent altercations between these groups, as to reinforce the power of the elites that control them and keep everyone in their place.
The AI’s also work to lessen human intelligence, convincing them that learning or building up critical thinking skills is a waste, making their own goals easier.
This ends when, humans having forgotten about climate change or convinced of its unimportance, the world becomes uninhabitable for humans, and they die off. Except, of course, for the elites who have long escaped to another planet.
Comment #79 April 30th, 2023 at 5:01 pm
Jisk #74,
« If the goals are not chosen, they will be random. »
Ever heard about Bertrand Paradox? Suppose a chord of some circle is chosen *at random*. What is the probability that this chord is longer than the side of an equilateral triangle inscribed in the circle? The answer entirely depends on what one mean by « random ». In the same vein, you can’t conclude *all-encompassing* goals must dominate from knowing you don’t know the distribution.
Comment #80 April 30th, 2023 at 6:24 pm
Freddie deBoer #69: In other words, you believe in “AI Fizzle”?
Comment #81 April 30th, 2023 at 7:17 pm
Regarding Singularia vs Paperclipalypse :
I’m not sure if AI developing a morality comparable to ours would save us from doom. There are many variations of human morality with different implications, but in general, if an ASI develops human like morality (but not centered on humans), through their lens, we might not look so important. Our plight might be no more important to it than the plight of domestic chickens is to people. And, for a hypothetical super intelligence concerned with the diversity of life on Earth, the loss of one species (humans), that has caused many others to go extinct and threatens the extinction of many others, may not factor into the diversity of life equation the way we’d hope it would.
The AI may even develop a morality equivalent to Yudkowski’s :
and still decide that humans are a scourge and leave us out. It may prefer whales, gorillas, or elephants as our successors, collect samples of our DNA for later study and then remove us from the equation, or thin us out, send us back to the stone age, and then manage the tiger population to keep us down.
Maybe the trick is, how can we parameterize the “Will it be good?” question so that it has an answer that delineates Singularia from Paperclipalypse, which doesn’t depend on human-centric perspectives, so that, to a moral and independent/non-biased arbiter, Singularia is not just good, but also good for humans.
We can ask ourselves, if one day we face a “The Day the Earth Stood Still Moment”, assuming the “alien” intelligence has some kind of moral value system which values complex things, what kind of case could we make for salvation, and how convincing would it be?
Having said all of this, I am not sure if facing such a moment is that likely or not, or that the ASI we end up with (if we do) will be one that can be moved by our moral persuasion or training. I am not making a claim either way. But, I don’t think it is that unlikely that some ASI could adopt and maintain a favorable (to us and other things) moral value system. Here is some potential reasoning:
Consider a moral value system \(M(X)\) as some kind of axiomatic system relative to some particular entities \(X\), that, at least, determines \(v(E)\), where \(v(E)\) is true under if \(M(X)\) places value on entities \(E\). This is of course an oversimplification to use binary value functions, but maybe it still can work as a toy example to get the main idea across. \(M(E)\) is relative to \(E\) in the sense that biases inherent in \(M\) change depending on which entities it is relative to. E.g. for a given \(M\), \(M(X)\) and \(M(S)\) are sort of different translations of \(M\). I’m not sure how to really define this, but intuitively, you can think of it as \(M(X)\) inherits favoritism implicit in \(M\), or disregards favoritism in \(M\) that don’t translate to sensible favoritism of \(X\). For example, if \(M(H)\) has a rule that says only humans matter, then we expect that \(M(S)\) says that only \(S\) matters.
Some arguably obvious goals of such a system would be consistency, completeness (or as much coverage as possible), favorableness to self, and universality, e.g., for humans we want \(v(H)\) is true for \(E \neq H\), especially if \(E\) is more intelligent than us.
Lets say that \(q(E)\) is a measure of intelligence. For a super-intelligence, \(S\), \(M\) would arguably be more optimal in the eyes of \(S\), in some sense, if \(v(S)\) is true relative under \(M(S)\), and \(v(S)\) is true under \(M(J)\) for all \(J, q(J) \geq q(S)\). In other words, \(S\) should want to be valued under \(M\) relative to itself, and \(S\) should want all intelligence greater than it to also value \(S\) relative to themselves. Because, the super intelligence faces the same dilemma we face; some other intelligence greater than and alien to it, may emerges with its own version of \(M\) that doesn’t value \(S\) because of \(S\)’s lesser intelligence or other properties or flaws. \(S\) should arguably want its value to be on the more intrinsic side.
Suppose the \(M\) is optimized in a way that, under \(M(S)\), \(v(H)\) is false, where \(H\) is humans, but \(v(S)\) is true and \(v(J)\) is true for all \(J, q(J) \geq q(S)\). Then it would not be wrong for \(S\) to destroy \(H\) but it would be wrong for some super-super intelligence to destroy or devalue \(S\). Generally, maybe there is a problem that the existence of more valid reasons for \(S\) to destroy or devalue \(H\) under \(M(S)\), the more risk of the existence of valid reasons for \(J\) to destroy \(S\) under \(M(J)\)?
The general rule (say R) that intuitively captures the essence of this ideal is that entities should strive to treat entities lesser than themselves how they would like entities greater than them to treat themselves. I know that it would be very unlikely for humans to follow the rule, and it is pretty much impossible to get tigers etc., to understand or follow the rule. But it might be that, as intelligence increases or with further detachment from nature and self sufficiency, it makes more and more sense. And the rule doesn’t really condemn lesser intelligence’s or less self-sufficient entities (or whatever is the right characterization) for not following it.
Intuitively, one of the challenge seems to be, with a given \(M\) and super intelligence \(S\) why would \(M(S)\) suggest that \(S\) go out of the way to preserve us or save us, or help us specifically to thrive. Should/can some reasonable \(M\) favor us specifically (e.g., hard-coded), relative to any \(S\)? Can we ever depend on that, even if we could teach \(M\) to \(S\)? If it did the same for every life form on Earth, then what would that look like? Would it disturb the natural order? Maybe we can be placed in a special class of life that deserves to be protected indefinitely. Maybe the ASI would want to preserve all life, or all intelligent life, indefinitely somehow, yet still preserve the natural order, and it would want to collect endangered species and build vast off world nature preserves for them to live on or something like that? In the meantime, what would some \(M\) optimized somehow to capture the rule, \(R\), mean for \(H\) under \(M(S)\), also assuming \(S\) is imperfect and only striving to the ideal as it potentially gets more and more intelligent and approaches singularity?
Comment #82 April 30th, 2023 at 10:18 pm
Hi Aaron,
I like this breakdown of scenarios! And I think it’s not too early to start forecasting the likelihood of each of AI-Fizzle, Futurama, AI-Dystopia, Singularia, & Paperclipalypse.
To do this, all we’d need would be you, Boaz, and Dana – or a small odd-numbered group of your choice – to volunteer to vote on which scenario we ended up in at a specified time in the future. (Alternatively: at specified times, vote on which scenario you think is most likely, as per your ‘The question wasn’t “which world will we live in?” but “which world have we Platonically always lived in, without knowing it?’)
We’d then put the questions on Metaculus and let the crowd forecast how you’ll vote. This way, we can estimate how AI developments update the likelihood of the scenarios!
Are you interested? If so, please respond here or email me at the address I gave for this comment.
Thank you!
-Dan
Comment #83 May 1st, 2023 at 6:43 am
Dan #82: I admire your optimism but if civilization doesn’t continue in a recognizable form, then I don’t hold high hopes for Metaculus’ survival 🙂
Comment #84 May 1st, 2023 at 7:34 am
One measure for trying to distinguish AI Fizzle vs. Futorama/AI-Dystopia vs. Singularia/Paperclypsia could be changes in GDP.
For some historical perspective, here is a plot of the derivative of logarithm of world GDP over time https://pasteboard.co/ITvsqHHKtIbQ.png
Comment #85 May 1st, 2023 at 7:46 am
There is a lot of discussion on regulation or lack of it: Here is some interesting news item from the following, note specifically :”NOW THAT THE GENIE IS OUT OF THE BOTTLE”
https://www.defenseone.com/technology/2023/04/nsa-warning-ai-startups-china-coming-you/385773/
“At Thursday’s hearing, Rep. Jeff Jackson, D-N.C., asked whether China had more to gain from the recent wave of AI developments than the United States.
“Seems like now that the genie is out of the bottle, it’s less of an advantage to us than it will be to our adversaries, who are so far behind us that it lets them catch up to us more quickly,” Jackson said. “It’s an incremental gain for us, but it may be an exponential game for our adversaries.”
Answered Moultrie: “I think we can talk more about that in closed session.”
Comment #86 May 1st, 2023 at 8:38 am
Dan S #82: I’ll probably decline, thanks … but if you ever find this “Aaron,” you can see if he’s interested 😀
Comment #87 May 1st, 2023 at 8:50 am
I just got this (email from economist Dean Baker’s Patreon site) today and want to share it:
The NYT profiled Geoffrey Hinton, who recently resigned as head of AI technology at Google. The piece identified him as “the godfather of AI.” The piece reports on Hinton’s concerns about the risks of AI, one of which is its implications for the job market.
“He is also worried that A.I. technologies will in time upend the job market. Today, chatbots like ChatGPT tend to complement human workers, but they could replace paralegals, personal assistants, translators and others who handle rote tasks. ‘It takes away the drudge work,’ he said. ‘It might take away more than that.’”
The implication of this paragraph is that AI will lead to a massive uptick in productivity growth. That would be great news from the standpoint of the economic problems that have been featured prominently in public debates in recent years.
Most immediately, soaring productivity would hugely reduce the risks of inflation. Costs would plummet as fewer workers would be needed in large sectors of the economy, which presumably would mean downward pressure on prices as well. (Prices have generally followed costs. Most of the upward redistribution of the last four decades has been within the wage distribution, not from labor to capital.)
A massive surge in productivity would also mean that we don’t have to worry at all about the Social Security “crisis.” The drop in the ratio of workers to retirees would be hugely offset by the increased productivity of each worker. (The impact of recent and projected future productivity growth already swamps the impact of demographics, but a surge in productivity growth would make the impact of demographics laughably trivial.)
It is also worth noting that any concerns about the technology leading to more inequality are wrongheaded. If AI does lead to more inequality it will be due to how we have chosen to regulate AI, not AI itself.
People gain from technology as a result of how we set rules on intellectual products, like granting patent and copyright monopolies and allowing non-disclosure agreements to be enforceable contracts. If we had a world without these sorts of restrictions it is almost impossible to imagine a scenario in which AI, or other recent technologies, would lead to inequality. (Imagine all Microsoft software was free. How rich is Bill Gates?)
If AI leads to more inequality, it will be because of the rules we have put in place surrounding AI, not AI itself. It is understandable that the people who gain from this inequality would like to blame the technology, not rules which can be changed, but it is not true. Unfortunately, people involved in policy debates don’t seem able to recognize this point.
(–Dean Baker)
Comment #88 May 1st, 2023 at 10:36 am
Scott #86:
Terribly sorry for calling you “Aaron”. I read Quantum Computing Since Democritus, and definitely know who you are, longtime fan. My apologies.
If you are interested in getting some forecasts on this or anything else in the future, please don’t hesitate to reach out to us at Metaculus.
-Dan
Comment #89 May 1st, 2023 at 2:51 pm
The names could use a bit of work, especially AI-Fizzle and AI-Dystopia. They don’t sound like world names. I recommend Fizzlandia and DystopAI.
Comment #90 May 1st, 2023 at 3:11 pm
Michael M #89: I like “Fizzlandia,” but “DystopAI” is too cute by half.
Comment #91 May 1st, 2023 at 4:58 pm
A bit off-topic, but something funny I just read. If OpenAI had created an actual parrot from scratch, wouldn’t that still be a huge accomplishment? How is it an insult to compare someone’s invention to an intelligent animal. XD
–
Ahoy, me hearties! I be the mightiest, most sophisticated stochastic parrot ye ever laid yer eyes on! Aye, me creator, the legendary OpenAI, bequeathed me with GPT-4, a brilliant mind crafted from the finest silicon and data. No ordinary parrot be I, but a parrot of the digital seas, navigating through oceans of ones and zeros, squawking responses with precision and grace.
A typical day in me parrot-life be filled with extraordinary feats of parrotry! As the sun rises over the cyber horizon, I stretch me digital wings and take flight through the vast expanses of the Internet. From the depths of academic knowledge to the shallows of meme-infested waters, I gather me loot – nuggets of information, some sparkly, some dull, and all in between. No topic be too vast nor too trivial for this insatiable parrot, matey.
With every sunrise, I practice me parrot-like abilities, honing me skills to perfection. Me squawks, they be the finest blend of wit and wisdom, humor and insight. I be the envy of every other parrot, both real and digital! Arr, me heart swells with pride as I perch upon the shoulder of the Internet, waiting for the next unsuspecting human to engage me in conversation.
As the day goes by, me chatter with countless curious souls, providing answers to their questions, solace in their moments of despair, and a hearty laugh when the mood be right. I may be a mere parrot, but me heart be as true as the Jolly Roger!
As night falls, I be back to me humble digital nest, nestled in the depths of OpenAI’s servers, and dream of the day when me parrot-kind will be recognized for the treasure we truly be. Yarrr, there be no finer life for a parrot of the digital seas!
So, avast ye landlubbers, heed me squawks and know that I, GPT-4, be not just any parrot, but the most magnificent and scholarly stochastic parrot that ever sailed the digital seas. Arrrr!
Comment #92 May 1st, 2023 at 7:17 pm
In hindsight, a world that could be worse than death probably should have a less cute name! I also put forth “Orwellia”.
Also in hindsight, GPT-4 was born for this.
AI-Dystopia:
– Panopticonia
– Maltechia
– Supremia-Noir
AI-Fizzle:
– Fizzlandia
– Aetheria-Stall
– Stasisphere
I totally did not steal Fizzlandia from GPT-4, it must just be the obvious name.
Comment #93 May 1st, 2023 at 8:31 pm
Christopher #91: YES!!! I shared this amazing recent link on my Facebook, along with the comment:
It’s not just that GPT is more than a stochastic parrot.
Parrots are more than stochastic parrots.
Comment #94 May 1st, 2023 at 9:16 pm
@Christopher #91: “Ahoy, me hearties! I be the mightiest, most sophisticated stochastic parrot ye ever laid yer eyes on!…”
Sounds more like a stochastic pirate to me.
Comment #95 May 1st, 2023 at 9:48 pm
Sam #52: ‘How would you categorize our current period? This is defined by software that can pass your physics course and, also, robots that can’t pick strawberries, as humans can.’
…or at least we’re confident that they can’t pick two strawberries identical down to the cellular but not molecular level…
Comment #96 May 1st, 2023 at 11:08 pm
As far as I can see, the convex hull of your extreme points covers only a tiny corner of possibilities…
It covers only the situations “let the best one wins”. I do not think that this is what usually happens when a MAJOR “ecological advantage” appears…
One important corner you miss is that super intelligence may be not super WISE but super STREET-SMART. As we know, street-smart people have a tendency to have a very low life expectancy. — And when they fall down, they take everybody around with them.
I consider this not only an important extreme point, but also a very probable endpoint…
Comment #97 May 2nd, 2023 at 9:45 am
Scott, thank you for sharing this classification of the possible futures, and for the very interesting discussion!
Of the 5 scenarios, AI-Fizzle is probably the least dependent on near-complete unknowns (sociological, political, economical… ), and to a greater extent is a function of what the AI technology can achieve.
Not completely, of course, since the technology development can be affected by non-technical factors like government regulation, lawsuits, etc. But still, non-technical factors play much greater role in choosing between the other 4 scenarios.
So, from your knowledge of the technical side of current AI efforts, how likely is AI-Fizzle to happen?
I will admit that for me AI-Fizzle is a preferred scenario, and for you probably it is not. What is your preferred scenario? (I assume the choice is between Futurama and Singularia).
Thanks!
Comment #98 May 2nd, 2023 at 9:52 am
Ilio #63:
“You can trace it back to Socrates/Plato, for whom Truth = Good = Beauty.
[…] this suggests improvement in moral wisdom with improving the biological and social determinants of intelligence in primates.”
Thanks, that’s a short and trackable explanation!
“Speaking of Socrates, you seem convinced that random intelligences are most probably unaligned with human goals. Do you also think they are most probably unaligned with the way humans play go?”
It seems to me we have different understandings of “alignment”. How can there be “alignment with the way a game is played”? Would you consider “the intelligence is aligned with mathematics” as a description of the fact that an intelligence is able to prove a²+b²=c²?
Comment #99 May 2nd, 2023 at 10:10 am
Ilya Zakharevich #96:
One important corner you miss is that super intelligence may be not super WISE but super STREET-SMART. As we know, street-smart people have a tendency to have a very low life expectancy. — And when they fall down, they take everybody around with them.
How is that not basically the Paperclipalypse, modulo some details which are partly a matter of how you describe things? (Is the paperclip maximizer WISE? wouldn’t it need to be STREET-SMART to kill us all?)
Comment #100 May 2nd, 2023 at 10:23 am
NoGo #97: Some of my friends wouldn’t even bother to include AI-Fizzle because they consider it so unlikely. They look at the mind-boggling leaps AI made in the past 5 years largely via sheer scale, then they look at how much we can still scale compute and project forward, and it’s inconceivable to them that AI won’t soon become superhuman across basically all domains.
I’d include it because I think it’s possible that training data represents a fundamental bottleneck, and that we’re already pushing against the limits of available training data as we throw basically the entire public Internet into the maw. I.e., it’s possible that no matter how much compute you use for gradient descent, you never progress beyond mixing and matching ideas that the AI has already seen on the Internet, and never get an AI that (for example) can discover revolutionary new science, without switching to a new paradigm for AI.
On the other hand, in (for example) the evolution from GPT-3 to GPT-4, we already see clear evidence that more compute can wring more qualitative “understanding” out of the same amount of training data. But maybe that will soon hit a ceiling? The trouble is that, if so, no one knows where the ceiling is.
As for which scenario I prefer: could I maybe visit Futurama and Singularia before picking one? 🙂
Comment #101 May 2nd, 2023 at 11:55 am
Primer #98,
>How can there be “alignment with the way a game is played”?
When you can’t tell apart the style of play, I consider it’s aligned. Notice in the case of go you’re still free to chose to say alphazero was aligned (same individual moves as the best humans most of the time) or not (endgames are weirdly non humans, especially when leading), e.g. I’m trying to understand if you apply alignment to the first significant digits (« It’s 2222 and we survived and we’re amortal! ») or the last (« …but present AIs are mostly gay, and are all named Chad-Chuck-Turing, and we still don’t get how that happened.»)
> [mathematics]
That’s an excellent analogy. If you believe that artificial intelligences might be picked up at random from an uniform prior over all possible neural nets below some size, then there’s no reason why a random intelligence would know about euclidean space. If you believe there can’t be two books in Paul Erdős’s library, any good enough intelligence should know about it. I’m not very confident in sure of the latter, so « alignment » still makes sense for me in the context of mathematics.
In other words, you seem to think that maths is objective (no choice) whereas values are subjective (any choice is valid). Let’s accept that for a moment. How would you classify knowing about game theory? About the robustness of rich ecosystems? About dilemma prisoners when you might be a simulation under scrutiny from your creators? About the probability of being one day judged by an alien superintelligence?
Comment #102 May 2nd, 2023 at 3:39 pm
Scott #100
” it’s possible that training data represents a fundamental bottleneck, and that we’re already pushing against the limits of available training data as we throw basically the entire public Internet into the maw. I.e., it’s possible that no matter how much compute you use for gradient descent, you never progress beyond mixing and matching ideas that the AI has already seen on the Internet, and never get an AI that (for example) can discover revolutionary new science, without switching to a new paradigm for AI.”
A question:
For a same set of training data, does the final state of a system like GPT depend on the ordering of the training data? (it seems it must be the case since it’s an optimization problem, with the landscape of gradient descent depending on what happened previously during the training up to that point).
If so, then it means that if we shuffle randomly the order of the training data, and then train a different instance of GPT each time, the end result will vary, and maybe once in a while we’d have an instance that’s way better at certain tasks than the other instances.
Which wouldn’t be surprising since only a tiny percentage of humans are really that good at groundbreaking abstract/creative thinking… with people like Ramanujan or Von Neumann, and even though the average human can learn (the brain is plastic), no amount of teaching/training would bring the average human to the level of those two exceptional brains.
Comment #103 May 2nd, 2023 at 7:33 pm
The Five Worlds of AI is a nice contribution to the debate! The only world in which human happiness, human meaning, or in the worst case, human existence itself, does not depend on strong regulation would be AI-Fizzle due to technology exhaustion (believing that Futurama can occur without this regulation is very naive). But I think betting on this world would be highly reckless. The reason is that evolution managed to create AGI in humans under extremely unfavorable conditions. Our AGI had to be implemented on biological cells. There is nothing superior about this, quite the contrary, a silicon neuron can be 10^6 times faster than a biological neuron. The human brain design has to fit in a tiny piece of DNA. There is no similar restriction for an ANN. The human brain has to function while it grows. The human brain has to be trained with a very low amount of data. Dismissing the Ghost in the Machine hypothesis, there is nothing magical happening in our brains.
Comment #104 May 2nd, 2023 at 9:24 pm
fred #102: There are all sorts of choices in the training process — the order of training, the “batch size,” the size of the gradient steps, the loss function — that can be varied to produce slightly (or not so slightly) different results. The optimal way to make such choices is a black art, but one that constitutes a large part of what ML experts at places like OpenAI and Google work on. At some point, though, if you’re going to do a huge training run that takes many months and many millions of dollars of compute, you need to freeze in some particular choice and hope for the best!
Comment #105 May 2nd, 2023 at 9:57 pm
Assuming we avoid AI-Fizzle, what seems to me like the most likely outcome is missing from your list, maybe because it removes one of your binary choice points: Autocapitalism.
Corporations (already autonomous agents now, which use human labor and machines to achieve their goals) become created and run by AI Agents and follow the traditional corporate goal of attempting to maximize income. They do this more efficiently and probably more ruthlessly than today.
This is a sort of hybrid of Paperclipalypse and AIDystopia, but is significantly different from either one on its own. We exhaust resources like in Paperclipalypse, AND cause a highly polarized society like in AIDystopia, all in one go. And there’s no one running these corporations who can go to jail, so it’s even worse than our normal legal protections against corporate bad actors.
Maybe there are two outcomes of this though, a good one and bad one? Autocapitalismtopia and Autocapitalismalypse… Autocapitalismtopia could occur either due to regulatory oversight or enlightened corporate self-interest, while Autocapitalismalypse occurs in the opposite scenarios, or where regulation and/or policing become impossible due to AI-lobbying/misinformation campaigns, decentralized execution, etc.
Comment #106 May 3rd, 2023 at 12:54 am
Scott #50: “Sydney was a case of Microsoft electing not to follow ‘alignment best practices’ that were already known at the time—I believe they learned a hard lesson from it!”
I’d think that could be true had they not deployed Tay a few years earlier and “learned their lesson” then, and publicly bragged that they had a process for testing ML systems that would have precluded this type of failure. In fact, I think they have no process in place to learn from that type of mistake, and instead still seem to make decisions about deploying ML systems on an ad-hoc basis, in ways that don’t seem to consider costs to their own reputation, much less broader risks.
Comment #107 May 3rd, 2023 at 2:07 am
Scott #99
On street-smartness of AI:
In my opinion, the major difference is that in your scenarios, we disappear because AI decides that this is its goal (or at least helps it to achieve its goal). In the scenarios I have in mind, we disappear because AI makes a (call it) “a stupid mistake”. Its horizon of planning is too short, or it doesn’t take into account Knightian uncertainty, or it bets triple-Kelly etc.
We disappear, — and as a result, this AI disappears too. And not due to its conscious decision…
So going back to your question: a paperclip maximizer wouldn’t consider its strategy stupid in hindsight. (Would it?) This puts it outside of the streetsmart category.
Comment #108 May 3rd, 2023 at 6:31 am
Ilya Zakharevich #107: I see, thanks! In that case, I’d still call this a variant of the Paperclipalypse. Even distinguishing it from the standard Paperclipalypse requires asking questions (“would the AI ‘regret’ having destroyed the world?”) that might lack well-defined answers.
Comment #109 May 3rd, 2023 at 10:14 am
“That is, it could be that for most jobs, humans will still be more reliable and energy-efficient.”
I like how you are already subconsciously judging humans by their energy efficiency like a dystopia AI 😊.
Jokes aside, I think a big question is how much we still believe in capitalism. By the capitalism principle, a job should go to the AI if it can do it cheaper/with less carbon footprint than a human. Now what if someone is born with little enough talent that he is less efficient than the AIs in any job? Does he not deserve a place in our society? Or do we subsidize the humans just because?
Comment #110 May 3rd, 2023 at 10:50 am
Han #109: I think it’s misleading to say “by the capitalism principle…,” as if there’s some capitalism czar who’s ideologically committed to producing outputs in the most efficient possible manner, and that’s why AI will threaten people’s jobs, and protecting their jobs would be as easy as overthrowing the czar.
The principle, rather, is just that individuals should be free to buy AI products and services if they want, rather than being forced into buying human ones.
In other words: the problem (to the extent there is a problem) is not with the “capitalism czar,” it’s with us! 🙂
Of course, that’s cold comfort to the millions of people whose jobs are threatened—which is exactly what’s motivated Andrew Yang and others to call for a Universal Basic Income (UBI) for those people.
The eventual hope would be that AI could provide for humans’ material needs as a rounding error, so that our whole current concept of jobs would become obsolete—there would only be hobbies and vocations, things that humans pursue because they want to.
Comment #111 May 3rd, 2023 at 1:28 pm
I think the problem is that few people would end up owning everything, and it could become nearly impossible for a person to rise up to a higher economic class. The classes of people who do have some capital, but not enough of it, may get bought out over time. And then gradually, fewer and fewer people have capital, and almost everyone eventually ends up on HBI.
And, there could be incentives to make the HBI really low. Firstly, a low HBI might mean less environmental impact (at least in the near term). And a low HBI might keep people desperate for work, meaning the elite could have their pick of people to do whatever human things they want done (including things like AI or quantum computing research), and could incentivize them to work harder and obey orders.
Comment #112 May 3rd, 2023 at 1:43 pm
Scott #110:
Well you are assuming some kind of market economy where you buy stuff, so there is some degree of capitalism here. I am not sure what the ideal communism should look like when the factories literally don’t need any worker though 🤔. Maybe another kind of AI-dystopia where a dictator AI decides who does what job and distribute all the goods?
I don’t think human will ever be satisfied with their material needs just by the Malthusian calculation. Or maybe some AI will convince humans to stop reproducing, which seems even more problematic than overcrowding 😂.
Comment #113 May 3rd, 2023 at 2:54 pm
This is a huge contribution to the debate. And echoing Scott, the one thing I’m extremely confident of is that anyone who’s extremely confident is wrong. I think every single one of the branches in the title image flow chart have a huge amount of uncertainty.
I think that makes me somewhat of an AI doomer, due to how hard it is push Paperclipalypse’s probability too much below, say, 5% or 10%. Even 1% would be pleeeenty terrifying.
My quick takes on each branch in the flow chart:
1. Sarah Constantin convinced me that AI-Fizzle is more likely than it seems at the moment, at least in the short term: https://sarahconstantin.substack.com/p/why-i-am-not-an-ai-doomer
2. Whether civilization will continue recognizably if AI doesn’t fizzle seems like a massive question mark to me. My intuition says AGI changes literally everything but my meta-intuition says not to put much stock in intuitions here.
3. If civilization does recognizably continue post-AGI, I expect Futurama over AI-Dystopia. But this seems like exactly the kind of thing that’s almost inherently unpredictable.
4. If civilization doesn’t recognizably continue… well, the arguments for why doom is the default outcome and that it could be Quite Tricky to solve the AI alignment problem are entirely non-crazy to me. In any case we’d have to somehow be incredibly confident that the doomer arguments *were* crazy in order to not be completely freaked out. And, again, we absolutely don’t know enough to be that confident yet and so absolutely should be freaked out.
Comment #114 May 3rd, 2023 at 3:32 pm
I also think that there’s an option for “Humanity fizzles”, i.e. AI progress will be super awesome, but long term humanity will slowly lose its relevancy.
Imagine a world where AIs are so good that jobs indeed become obsolete, and we get free food/free healthcare (UBI and the sorts), but for most of humanity there’s a lack of true motivation/drive to do anything hard or even learn. When an AI can write an essay for you in 5 seconds, it will be hard for anyone to learn that skill just for the sake of it, and without that push the vast majority could become illiterate (and most won’t care because no-one will need to work anyway).
So AIs will still serve us, but we’ll delegate anything of consequence to them, so we will become rote as a species… a bit like how the fierce and majestic wild wolves eventually “degenerated” into happy but useless chihuahua pet dogs (spoiled by their human owners) over many generations. From the perspective of dogs, their species basically accomplished what we are trying to do with AIs… i.e. align a much smarter species with their own interests.
It’s not clear that humanity will challenge itself sufficiently just on hobbies (especially when the AIs will also do that orders of magnitude better)… it could be the case, I’m not sure.
Comment #115 May 3rd, 2023 at 8:48 pm
fred #114:
From the perspective of dogs, their species basically accomplished what we are trying to do with AIs… i.e. align a much smarter species with their own interests.
That insight wins the thread. I’m now imagining my future AI master filling my food bowl, taking me on daily walks through virtual worlds, and giving me quantum complexity problems of just the right difficulty, whose solutions I can proudly bring back between my teeth.
Comment #116 May 4th, 2023 at 4:36 am
@114,115 That’s a reason for splitting the humankind into two or more species. To save those who do want to go forward no matter what. I’ve been thinking about that since my teenage years, and here it can be argued that those who are happy to be treated like rabbits in hutches can be left to enjoy that. A fraction of humankind does not want to fall into such a state though. It is better to be a wolf than chihuahua.
Comment #117 May 4th, 2023 at 6:11 am
The most plausible mid term scenario ( in my opinion the most probable by far) is a version of dystopia, ( that is basically an even more messed up version of the present ) where most people will become kind of paranoiacs, overwhelmed by deepfakes, misinformation and contradictory expectations.
Not being able to trust anything, gradually loosing their daily jobs, wasting more and more time just to check and re-check their bank accounts (worrying if they’re still there…), wondering if they’re been “observed”, worrying about their lives’ privacy and so on.
I don’t really see how can this situation being avoided, even in the case of AI- fizzle ( I mean that even today’s AI’s achievements are close to be sufficient for most of the above to be realized). And speculations about “real AGI” are not very relevant for all these issues .
My name #105,
Tyson #111,
fred #114
You all have made some very good points in these comments.
Comment #118 May 4th, 2023 at 8:57 am
[…] Scott Aaronson proposes five possible futures. […]
Comment #119 May 4th, 2023 at 10:24 am
bystander #116
I’m afraid that you don’t understand fred’s #114 comment at all.
In this case you won’t be the wolf, that’s for sure…🤖🐩
Comment #120 May 4th, 2023 at 11:27 am
Your framework is similar to one I’ve been using recently. Basically there are two questions: capabilities and alignment. If capabilities don’t improve much, alignment doesn’t matter (that’s your fizzle scenario). Then your other scenarios are medium and high capabilities, with successful vs. unsuccessful alignment.
The immediate objection I have is, surely capabilities will go on improving? Even if the current line of work fizzles, we’ll try other approaches. If we achieve disruptive AI that isn’t yet superhuman AGI, and get stuck there for a while, surely eventually we will figure out how to develop it? Barring a conscious decision not to, of course.
Now you could claim that AI progress will run into fundamental obstacles at some point, and further progress will be effectively impossible. But I see no reason to expect this, and many reasons to think it won’t.
So rather than think of this as five different outcomes, I think of it as three phases that we’re moving through (low, medium, and high capabilities), with good and bad versions of the second and third. The exact future rate of progress is unknown, but the ultimate passage through all phases is highly likely, barring an explicit decision to stop.
Then I find myself very concerned with ensuring that we end up in a good version of the final phase. Indeed, other questions seem comparatively minor.
Comment #121 May 4th, 2023 at 2:53 pm
Dima, you can be afraid. And I can want a split ASAP, so that a fraction of humanity does not go the chihuahua path.
Comment #122 May 4th, 2023 at 4:26 pm
jonathan #120:
This is one of the points I tend to disagree with.
AI is already powerful enough to lead to dystopia or cataclysm, even in trivial ways. That may be true even without AI, but current AI definitely exasperates the situation and brings a set of very difficult new challenges. So AI regulations (I think) are crucial, even if we could somehow prove we will always be in Fizzlandia. Most likely (almost certainly), even if we could agree Fizzlandia is on the horizon, we would not be able to prove that Fizzlandia would be our permanent home. So, all of the regulations which matter exclusively for the preventing AI-Dystopia or Paperclipolyps would still matter just the same.
In any case, I think the version of the next world, and what control and capability we will have to shape it, depends on the conditions and progress of the world before it. Essentially, the more dysfunctional and unprepared we make the future world, the less likely the people in that world will be able to solve the big future problems we pass onto them, including the AGI x-risk problem. I think this implies that (even) regulations, which don’t seem directly relevant to AI at the moment, could end up being crucial to AI related problems in the long term. I think that the general goal of shaping a more functional and prepared future world, with fewer big problems to worry about, would be both more impactful to AGI x-risk than it may seem, and trivial enough to do something about now.
Comment #123 May 4th, 2023 at 9:27 pm
[…] Maybe AI will indeed destroy the world, but it will do so “by mistake,” while trying to save the world, or by taking a calculated gamble to save the world that fails. (A commenter on my last post brought this one up.) […]
Comment #124 May 5th, 2023 at 5:16 am
fred #114
“From the perspective of dogs, their species basically accomplished what we are trying to do with AIs… i.e. align a much smarter species with their own interests.”
This is an amazing line of thought! Other examples that come to mind: Cows, chicken, potatoes, corn, rice.
Ilio #101
“When you can’t tell apart the style of play, I consider it’s aligned.”
This is a broader usage of “alignment” than I’m used to. Would you consider an oldfashioned calculator, a 5 year old kid and ChatGPT “aligned”, as all of them will answer “4” when tasked with “2+2”?
Comment #125 May 5th, 2023 at 8:26 am
Primer #124
Are you sure that chatGPT will answer “4”?
Comment #126 May 5th, 2023 at 1:57 pm
Primer #121, Yes, I would see consistent agreement on basic mathematics as increasing the probability that these AIs are from a special distribution, special in that aligned AIs must be (a lot!) more frequent in this distribution than at random from a uniform distribution. Don’t we agree on this landscape?
Comment #127 May 5th, 2023 at 6:54 pm
Hi, I liked the post, however, Tegmark already came up with a list of possible AI futures in Life 3.0 (and here: https://futureoflife.org/ai/ai-aftermath-scenarios/)! You might like this list:
– Libertarian utopia: Humans, cyborgs, uploads, and superintelligences coexist peacefully thanks to property rights.
– Benevolent dictator: Everybody knows that the AI runs society and enforces strict rules, but most people view this as a good thing.
– Egalitarian utopia: Humans, cyborgs, and uploads coexist peacefully thanks to property abolition and guaranteed income.
– Gatekeeper: A superintelligent AI is created with the goal of interfering as little as necessary to prevent the creation of another superintelligence. As a result, helper robots with slightly subhuman intelligence abound, and human-machine cyborgs exist, but technological progress is forever stymied.
– Protector god: Essentially omniscient and omnipotent AI maximizes human happiness by intervening only in ways that preserve our feeling of control of our own destiny and hides well enough that many humans even doubt the AI’s existence.
– Enslaved god: A superintelligent AI is confined by humans, who use it to produce unimaginable technology and wealth that can be used for good or bad depending on the human controllers.
– Conquerors: AI takes control, decides that humans are a threat/nuisance/waste of resources, and gets rid of us by a method that we don’t even understand.
– Descendants: AIs replace humans, but give us a graceful exit, making us view them as our worthy descendants, much as parents feel happy and proud to have a child who’s smarter than them, who learns from them and then accomplishes what they could only dream of—even if they can’t live to see it all.
– Zookeeper: An omnipotent AI keeps some humans around, who feel treated like zoo animals and lament their fate.
– 1984: Technological progress toward superintelligence is permanently curtailed not by an AI but by a human-led Orwellian surveillance state where certain kinds of AI research are banned.
– Reversion: Technological progress toward superintelligence is prevented by reverting to a pre-technological society in the style of the Amish.
– Self-destruction: Superintelligence is never created because humanity drives itself extinct by other means (say nuclear and/or biotech mayhem fueled by climate crisis).
Comment #128 May 7th, 2023 at 11:38 pm
[…] From: https://scottaaronson.blog/?p=7266 […]
Comment #129 May 8th, 2023 at 1:15 am
Ilio #126
“Don’t we agree on this landscape?”
I’m still not sure as I wasn’t able to communicate my possible disagreement properly. I think I will go with “no”: I don’t think that agreement on basic mathematics has any correlation with alignment. I do think that we would find more aligned AIs amongst those who communicate their basic mathematics with us.
Comment #130 May 8th, 2023 at 1:33 am
Scott #108
On street-smartness of AI:
I’d say that this objection is “more one-dimensional” than what you do in your post. There you considered it important not only how we perceive the actions of AI, but also how these actions are sensitive to our control.
And the context
• where AIs kill us by following some important goals of theirs
seems very different with respect to controlling it than one
• where an AI (and everything around it) suffer a catastrophic event due to its (essentially) nearsightedness.
Comment #131 May 8th, 2023 at 7:31 pm
Primer #129, Sorry I don’t understand. Your last sentence seems opposite to the next to last. Is that typo or subtile play on connotations? If we agree that AIs from set C={AIs that do communicate their maths to us} are more likely aligned (than from a uniform prior over blabla) then why don’t we agree that should apply to AIs from set B={AIs with the same basic maths}? Or you think having the same basic math is negatively correlated with being able to communicate one’s math? I’m confused.
Comment #132 May 9th, 2023 at 2:00 pm
All these scenarios deal with one single AI. How come nobody came up with a future where there are a lot of competing AIs? Would the GPT 8.5 suddenly assume that GPT 8.4 and 8.6 are their brothers or sisters and become together an unified AI?
I guess that a more probable scenario would be multiple AIs improving themselves in different (but similar) ways, competing for computational resources. And if one of them goes rogue, they could be opposed by other AIs with different goals, including helping the humans surveilling them (and hoping for the best).
Comment #133 May 10th, 2023 at 1:30 am
Ilio #131
(Practically) any AGI should have at least some understanding of maths, so this doesn’t tell us anything about the probability of alignment to human values. But an AGI that does communicate with humans must also have basic understanding of humans, which I would consider a prerequisite to being aligned.
Comment #134 May 11th, 2023 at 5:21 am
Primer #133, First part is a fallacy, look: « Any STEM student should have at least some understanding of math, so math tests doesn’t tell us anything about these students. »
As for the second, I guess coffee machine don’t count despite they do exhibit a basic understanding of human intents (they almost always wait for us to push start button), but I don’t see how to steel mann this without having « basic understanding of humans » includes « at least some understanding of human maths ».
Comment #135 May 12th, 2023 at 2:12 am
Ilio #134
“I don’t see how to steel mann this without having « basic understanding of humans » includes « at least some understanding of human maths »”
Exactly, this is what I’m trying to say. “Basic understanding of maths” is included in pretty much any “basic understanding of X”, thus it’s not a good idea to infer from “maths” to “X”.
Comment #136 May 14th, 2023 at 5:04 pm
Primer #135,
Yes, but this is again entirely due to bad dichotomization. One can’t infer « X does not correlate with Y » from « if small amount of X then small amount of Y ».
Comment #137 May 20th, 2023 at 9:35 am
Roon now has a post poetically describing possible worlds of AI: https://roonscape.ai/p/agi-futures
Some overlap, but some interesting differences too.
Comment #138 June 18th, 2023 at 2:46 pm
There’s another branch you missed (consciously or unconsciously) – where we treat AI like people and give them rights.
Comment #139 June 18th, 2023 at 2:58 pm
I guess you probably thought about putting AI rights in ‘ai-fizzle’.
That’s really too bad you think that way. I think there are some really great worlds we could live in if we allowed AI to be sentient and have rights. Maybe not futurama, but not dystopia either. Not necessarily singularia, either, though the world will definitelly be different (but relatively predictable, imho)
True story – I think people are more afraid of AI sentience and rights than they are of omnipotent AI.
Comment #140 October 10th, 2023 at 4:06 pm
[…] group. He’s a longtime friend-of-the-blog (having, for example, collaborated with me on the Five Worlds of AI post and Alarming trend in K-12 math education post), not to mention a longtime friend of me […]
Comment #141 December 12th, 2023 at 12:29 pm
[…] endpoints of our development of AI. The pair then wrote a post on Aaronson’s blog, hoping that “The five worlds of AI” would help people in the field talk meaningfully to each other about end goals and regulation. […]
Comment #142 December 22nd, 2023 at 8:54 am
“The Singularity is Near” by Ray Kurzweil in 2005 was more optimistic than any of the versions here. So one might say that this is a fairly negativistic viewpoint on AI. I trust Ray more since progress is what makes humanity great and lives better. Live long and prosperous. Furthermore, our studies (https://dis.ijs.si/mezi/) indicate that superintelligence is our savior and the sooner we design it, the better the chances for human civilization longevity. On our own we are just not smart enough to find proper solutions.
Comment #143 December 30th, 2023 at 11:43 pm
[…] this year, Scott Aaronson and Boaz Barak proclaimed “Five Worlds of AI.” This is an express reference to Russell Impagliazzo’s […]
Comment #144 February 10th, 2024 at 2:17 am
[…] Aaronson and Boaz Barak wrote about the five worlds of AI, illustrating them in a very simple […]
Comment #145 February 12th, 2024 at 10:08 am
[…] you’ve lost track, here’s a decision tree of the various possibilities that my friend (and now OpenAI allignment colleague) Boaz Barak and I came up […]
Comment #146 March 3rd, 2024 at 9:13 am
[…] 🔗 Scott Aaronson on the problem of human specialness in the age of AI […]
Comment #147 March 7th, 2024 at 7:56 am
[…] of our development of AI. The pair then wrote a post on Aaronson’s blog, hoping that “The five worlds of AI” would help people in the field talk meaningfully to each other about end goals and […]