My AI Safety Lecture for UT Effective Altruism
Two weeks ago, I gave a lecture setting out my current thoughts on AI safety, halfway through my year at OpenAI. I was asked to speak by UT Austin’s Effective Altruist club. You can watch the lecture on YouTube here (I recommend 2x speed).
The timing turned out to be weird, coming immediately after the worst disaster to hit the Effective Altruist movement in its history, as I acknowledged in the talk. But I plowed ahead anyway, to discuss:
- the current state of AI scaling, and why many people (even people who agree about little else!) foresee societal dangers,
- the different branches of the AI safety movement,
- the major approaches to aligning a powerful AI that people have thought of, and
- what projects I specifically have been working on at OpenAI.
I then spent 20 minutes taking questions.
For those who (like me) prefer text over video, below I’ve produced an edited transcript, by starting with YouTube’s automated transcript and then, well, editing it. Enjoy! –SA
Thank you so much for inviting me here. I do feel a little bit sheepish to be lecturing you about AI safety, as someone who’s worked on this subject for all of five months. I’m a quantum computing person. But this past spring, I accepted an extremely interesting opportunity to go on leave for a year to think about what theoretical computer science can do for AI safety. I’m doing this at OpenAI, which is one of the world’s leading AI startups, based in San Francisco although I’m mostly working from Austin.
Despite its name, OpenAI is famously not 100% open … so there are certain topics that I’m not allowed to talk about, like the capabilities of the very latest systems and whether or not they’ll blow people’s minds when released. By contrast, OpenAI is very happy for me to talk about AI safety: what it is and and what if anything can we do about it. So what I thought I’d do is to tell you a little bit about the specific projects that I’ve been working on at OpenAI, but also just, as an admitted newcomer, share some general thoughts about AI safety and how Effective Altruists might want to think about it. I’ll try to leave plenty of time for discussion.
Maybe I should mention that the thoughts that I’ll tell you today are ones that, until last week, I had considered writing up for an essay contest run by something called the FTX Future Fund. Unfortunately, the FTX Future Fund no longer exists. It was founded by someone named Sam Bankman-Fried, whose a net worth went from 15 billion dollars to some negative number of dollars in the space of two days, in one of the biggest financial scandals in memory. This is obviously a calamity for the EA community, which had been counting on funding from this individual. I feel terrible about all the projects left in the lurch, to say nothing of FTX’s customers.
As a tiny silver lining, though, instead of writing up my thoughts for that essay contest, I’ll just share them with you right now, for free!
The Scaling of AI
Let’s start with this: raise your hand if you’ve tried GPT-3. That’s maybe half of you. OK, raise your hand if you’ve tried DALL-E. That’s again maybe half of you.
These are the two best-known products that are made by OpenAI, and as I think most people would agree, two of the most impressive AIs that exist in the world right now. They certainly go far beyond what I would’ve predicted would be possible now, if you’d asked me 10 years ago or even 5 years ago.
And whenever I try to explain them to people, I’m, like, well, you have to see them. No abstract description can substitute in this case.
All right, so here’s what GPT-3 produced when a New Yorker writer asked it to write a poem about cryptocurrency in the style of Philip Larkin, who was a famous 20th-century poet. The subject seems particularly appropriate given current events.
The Invention (by GPT-3)
Money is a thing you earn by the sweat of your brow
And that’s how it should be.
Or you can steal it, and go to jail;
Or inherit it, and be set for life;
Or win it on the pools, which is luck;
Or marry it, which is what I did.
And that is how it should be, too.
But now this idea’s come up
Of inventing money, just like that.
I ask you, is nothing sacred?
Okay, it won’t always produce something of this quality (incidentally, I don’t think GPT-3 actually “married money”!). Often you’ve got to run it several times and take the best output—much like human poets presumably do, throwing crumpled pages into the basket. But I submit that, if the above hadn’t been labeled as coming from GPT, you’d be like, yeah, that’s the kind of poetry the New Yorker publishes, right? This is a thing that AI can now do.
So what is GPT? It’s a text model. It’s basically a gigantic neural network with about 175 billion parameters—the weights. It’s a particular kind of neural net called a transformer model that was invented five years ago. It’s been trained on a large fraction of all the text on the open Internet. The training simply consists of playing the following game over and over, trillions of times: predict which word comes next in this text string. So in some sense that’s its only goal or intention in the world: to predict the next word.
The amazing discovery is that, when you do that, you end up with something where you can then ask it a question, or give it a a task like writing an essay about a certain topic, and it will say “oh! I know what would plausibly come after that prompt! The answer to the question! Or the essay itself!” And it will then proceed to generate the thing you want.
GPT can solve high-school-level math problems that are given to it in English. It can reason you through the steps of the answer. It’s starting to be able to do nontrivial math competition problems. It’s on track to master basically the whole high school curriculum, maybe followed soon by the whole undergraduate curriculum.
If you turned in GPT’s essays, I think they’d get at least a B in most courses. Not that I endorse any of you doing that!! We’ll come back to that later. But yes, we are about to enter a world where students everywhere will at least be sorely tempted to use text models to write their term papers. That’s just a tiny example of the societal issues that these things are going to raise.
Speaking personally, the last time I had a similar feeling was when I was an adolescent in 1993 and I saw this niche new thing called the World Wide Web, and I was like “why isn’t everyone using this? why isn’t it changing the world?” The answer, of course, was that within a couple years it would.
Today, I feel like the world was understandably preoccupied by the pandemic, and by everything else that’s been happening, but these past few years might actually be remembered as the time when AI underwent this step change. I didn’t predict it. I think even many computer scientists might still be in denial about what’s now possible, or what’s happened. But I’m now thinking about it even in terms of my two kids, of what kinds of careers are going to be available when they’re older and entering the job market. For example, I would probably not urge my kids to go into commercial drawing!
Speaking of which, OpenAI’s other main product is DALL-E2, an image model. Probably most of you have already seen it, but you can ask it—for example, just this morning I asked it, show me some digital art of two cats playing basketball in outer space. That’s not a problem for it.

You may have seen that there’s a different image model called Midjourney which won an art contest with this piece:

It seems like the judges didn’t completely understand, when this was submitted as “digital art,” what exactly that meant—that the human role was mostly limited to entering a prompt! But the judges then said that even having understood it, they still would’ve given the award to this piece. I mean, it’s a striking piece, isn’t it? But of course it raises the question of how much work there’s going to be for contract artists, when you have entities like this.
There are already companies that are using GPT to write ad copy. It’s already being used at the, let’s call it, lower end of the book market. For any kind of formulaic genre fiction, you can say, “just give me a few paragraphs of description of this kind of scene,” and it can do that. As it improves you could you can imagine that it will be used more.
Likewise, DALL-E and other image models have already changed the way that people generate art online. And it’s only been a few months since these models were released! That’s a striking thing about this era, that a few months can be an eternity. So when we’re thinking about the impacts of these things, we have to try to take what’s happened in the last few months or years and project that five years forward or ten years forward.
This brings me to the obvious question: what happens as you continue scaling further? I mean, these spectacular successes of deep learning over the past decade have owed something to new ideas—ideas like transformer models, which I mentioned before, and others—but famously, they have owed maybe more than anything else to sheer scale.
Neural networks, backpropagation—which is how you train the neural networks—these are ideas that have been around for decades. When I studied CS in the 90s, they were already extremely well-known. But it was also well-known that they didn’t work all that well! They only worked somewhat. And usually, when you take something that doesn’t work and multiply it by a million, you just get a million times something that doesn’t work, right?
I remember at the time, Ray Kurzweil, the futurist, would keep showing these graphs that look like this:
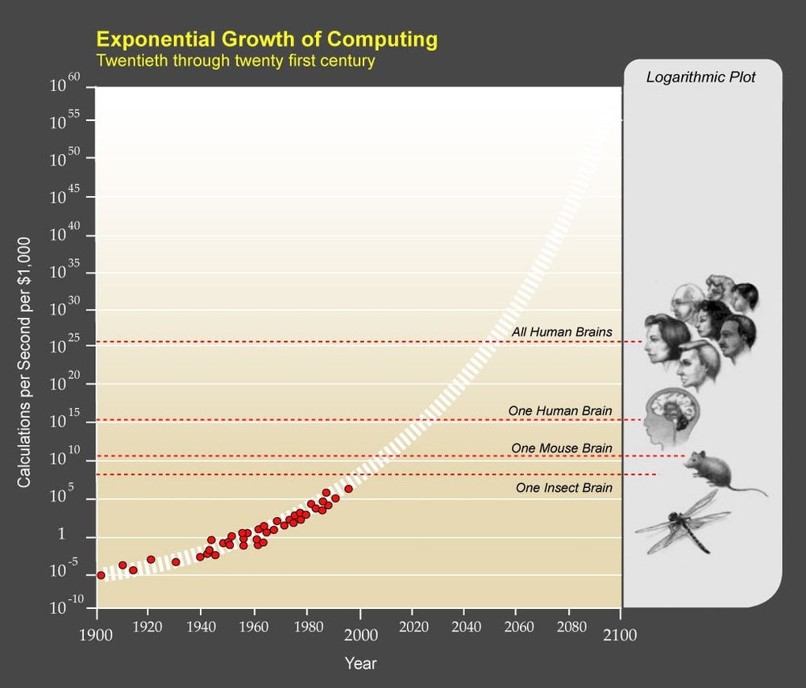
So, he would plot Moore’s Law, the increase in transistor density, or in this case the number of floating-point operations that you can do per second for a given cost. And he’d point out that it’s on this clear exponential trajectory.
And he’d then try to compare that to some crude estimates of the number of computational operations that are done in the brain of a mosquito or a mouse or a human or all the humans on Earth. And oh! We see that in a matter of a couple decades, like by the year 2020 or 2025 or so, we’re going to start passing the human brain’s computing power and then we’re going to keep going beyond that. And so, Kurzweil would continue, we should assume that scale will just kind of magically make AI work. You know, that once you have enough computing cycles, you just sprinkle them around like pixie dust, and suddenly human-level intelligence will just emerge out of the billions of connections.
I remember thinking: that sounds like the stupidest thesis I’ve ever heard. Right? Like, he has absolutely no reason to believe such a thing is true or have any confidence in it. Who the hell knows what will happen? We might be missing crucial insights that are needed to make AI work.
Well, here we are, and it turns out he was way more right than most of us expected.
As you all know, a central virtue of Effective Altruists is updating based on evidence. I think that we’re forced to do that in this case.
To be sure, it’s still unclear how much further you’ll get just from pure scaling. That remains a central open question. And there are still prominent skeptics.
Some skeptics take the position that this is clearly going to hit some kind of wall before it gets to true human-level understanding of the real world. They say that text models like GPT are really just “stochastic parrots” that regurgitate their training data. That despite creating a remarkable illusion otherwise, they don’t really have any original thoughts.
The proponents of that view sometimes like to gleefully point out examples where GPT will flub some commonsense question. If you look for such examples, you can certainly find them! One of my favorites recently was, “which would win in a race, a four-legged zebra or a two-legged cheetah?” GPT-3, it turns out, is very confident that the cheetah will win. Cheetahs are faster, right?
Okay, but one thing that’s been found empirically is that you take commonsense questions that are flubbed by GPT-2, let’s say, and you try them on GPT-3, and very often now it gets them right. You take the things that the original GPT-3 flubbed, and you try them on the latest public model, which is sometimes called GPT-3.5 (incorporating an advance called InstructGPT), and again it often gets them right. So it’s extremely risky right now to pin your case against AI on these sorts of examples! Very plausibly, just one more order of magnitude of scale is all it’ll take to kick the ball in, and then you’ll have to move the goal again.
A deeper objection is that the amount of training data might be a fundamental bottleneck for these kinds of machine learning systems—and we’re already running out of Internet to to train these models on! Like I said, they’ve already used most of the public text on the Internet. There’s still all of YouTube and TikTok and Instagram that hasn’t yet been fed into the maw, but it’s not clear that that would actually make an AI smarter rather than dumber! So, you can look for more, but it’s not clear that there are orders of magnitude more that humanity has even produced and that’s readily accessible.
On the other hand, it’s also been found empirically that very often, you can do better with the same training data just by spending more compute. You can squeeze the lemon harder and get more and more generalization power from the same training data by doing more gradient descent.
In summary, we don’t know how far this is going to go. But it’s already able to automate various human professions that you might not have predicted would have been automatable by now, and we shouldn’t be confident that many more professions will not become automatable by these kinds of techniques.
Incidentally, there’s a famous irony here. If you had asked anyone in the 60s or 70s, they would have said, well clearly first robots will replace humans for manual labor, and then they’ll replace humans for intellectual things like math and science, and finally they might reach the pinnacles of human creativity like art and poetry and music.
The truth has turned out to be the exact opposite. I don’t think anyone predicted that.
GPT, I think, is already a pretty good poet. DALL-E is already a pretty good artist. They’re still struggling with some high school and college-level math but they’re getting there. It’s easy to imagine that maybe in five years, people like me will be using these things as research assistants—at the very least, to prove the lemmas in our papers. That seems extremely plausible.
What’s been by far the hardest is to get AI that can robustly interact with the physical world. Plumbers, electricians—these might be some of the last jobs to be automated. And famously, self-driving cars have taken a lot longer than many people expected a decade ago. This is partly because of regulatory barriers and public relations: even if a self-driving car actually crashes less than a human does, that’s still not good enough, because when it does crash the circumstances are too weird. So, the AI is actually held to a higher standard. But it’s also partly just that there was a long tail of really weird events. A deer crosses the road, or you have some crazy lighting conditions—such things are really hard to get right, and of course 99% isn’t good enough here.
We can maybe fuzzily see ahead at least a decade or two, to when we have AIs that can at the least help us enormously with scientific research and things like that. Whether or not they’ve totally replaced us—and I selfishly hope not, although I do have tenure so there’s that—why does it stop there? Will these models eventually match or exceed human abilities across basically all domains, or at least all intellectual ones? If they do, what will humans still be good for? What will be our role in the world? And then we come to the question, well, will the robots eventually rise up and decide that whatever objective function they were given, they can maximize it better without us around, that they don’t need us anymore?

This has of course been a trope of many, many science-fiction works. The funny thing is that there are thousands of short stories, novels, movies, that have tried to map out the possibilities for where we’re going, going back at least to Asimov and his Three Laws of Robotics, which was maybe the first AI safety idea, if not earlier than that. The trouble is, we don’t know which science-fiction story will be the one that will have accurately predicted the world that we’re creating. Whichever future we end up in, with hindsight, people will say, this obscure science fiction story from the 1970s called it exactly right, but we don’t know which one yet!
What Is AI Safety?
So, the rapidly-growing field of AI safety. People use different terms, so I want to clarify this a little bit. To an outsider hearing the terms “AI safety,” “AI ethics,” “AI alignment,” they all sound like kind of synonyms, right? It turns out, and this was one of the things I had to learn going into this, that AI ethics and AI alignment are two communities that despise each other. It’s like the People’s Front of Judea versus the Judean People’s Front from Monty Python.
To oversimplify radically, “AI ethics” means that you’re mainly worried about current AIs being racist or things like that—that they’ll recapitulate the biases that are in their training data. This clearly can happen: if you feed GPT a bunch of racist invective, GPT might want to say, in effect, “sure, I’ve seen plenty of text like that on the Internet! I know exactly how that should continue!” And in some sense, it’s doing exactly what it was designed to do, but not what we want it to do. GPT currently has an extensive system of content filters to try to prevent people from using it to generate hate speech, bad medical advice, advocacy of violence, and a bunch of other categories that OpenAI doesn’t want. And likewise for DALL-E: there are many things it “could” draw but won’t, from porn to images of violence to the Prophet Mohammed.
More generally, AI ethics people are worried that machine learning systems will be misused by greedy capitalist enterprises to become even more obscenely rich and things like that.
At the other end of the spectrum, “AI alignment” is where you believe that really the main issue is that AI will become superintelligent and kill everyone, just destroy the world. The usual story here is that someone puts an AI in charge of a paperclip factory, they tell it to figure out how to make as many paperclips as possible, and the AI (being superhumanly intelligent) realizes that it can invent some molecular nanotechnology that will convert the whole solar system into paperclips.
You might say, well then, you just have to tell it not to do that! Okay, but how many other things do you have to remember to tell it not to do? And the alignment people point out that, in a world filled with powerful AIs, it would take just a single person forgetting to tell their AI to avoid some insanely dangerous thing, and then the whole world could be destroyed.
So, you can see how these two communities, AI ethics and AI alignment, might both feel like the other is completely missing the point! On top of that, AI ethics people are almost all on the political left, while AI alignment people are often centrists or libertarians or whatever, so that surely feeds into it as well.
Oay, so where do I fit into this, I suppose, charred battle zone or whatever? While there’s an “orthodox” AI alignment movement that I’ve never entirely subscribed to, I suppose I do now subscribe to a “reform” version of AI alignment:
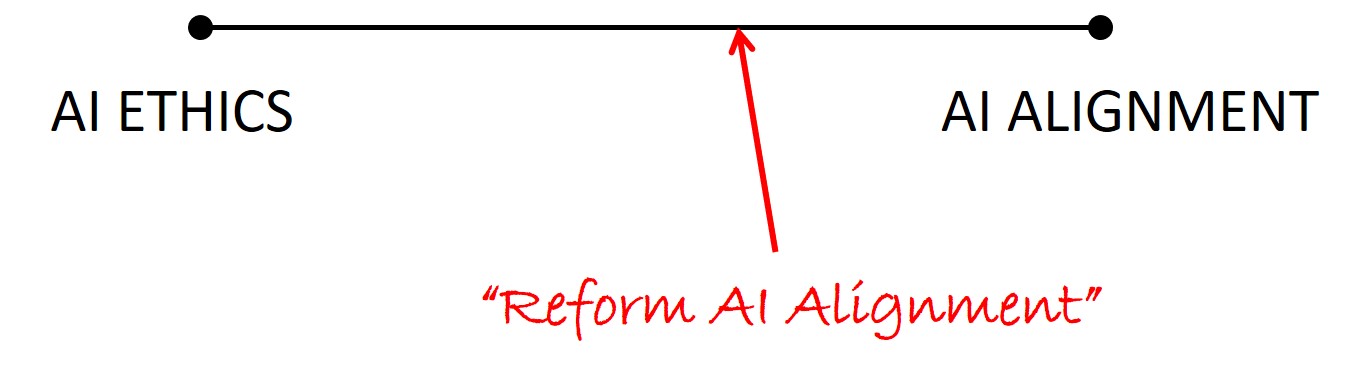
Most of all, I would like to have a scientific field that’s able to embrace the entire spectrum of worries that you could have about AI, from the most immediate ones about existing AIs to the most speculative future ones, and that most importantly, is able to make legible progress.
As it happens, I became aware of the AI alignment community a long time back, around 2006. Here’s Eliezer Yudkowsky, who’s regarded as the prophet of AI alignment, of the right side of that spectrum that showed before.

He’s been talking about the danger of AI killing everyone for more than 20 years. He wrote the now-famous “Sequences” that many readers of my blog were also reading as they appeared, so he and I bounced back and forth.
But despite interacting with this movement, I always kept it at arm’s length. The heart of my objection was: suppose that I agree that there could come a time when a superintelligent AI decides its goals are best served by killing all humans and taking over the world, and that we’ll be about as powerless to stop it as chimpanzees are to stop us from doing whatever we want to do. Suppose I agree to that. What do you want me to do about it?
As Effective Altruists, you all know that it’s not enough for a problem to be big, the problem also has to be tractable. There has to be a program that lets you make progress on it. I was not convinced that that existed.
My personal experience has been that, in order to make progress in any area of science, you need at least one of two things: either
- experiments (or more generally, empirical observations), or
- if not that, then a rigorous mathematical theory—like we have in quantum computing for example; even though we don’t yet have the scalable quantum computers, we can still prove theorems about them.
It struck me that the AI alignment field seemed to have neither of these things. But then how does objective reality give you feedback as to when you’ve taken a wrong path? Without such feedback, it seemed to me that there’s a severe risk of falling into cult-like dynamics, where what’s important to work on is just whatever the influential leaders say is important. (A few of my colleagues in physics think that the same thing happened with string theory, but let me not comment on that!)
With AI safety, this is the key thing that I think has changed in the last three years. There now exist systems like GPT-3 and DALL-E. These are not superhuman AIs. I don’t think they themselves are in any danger of destroying the world; they can’t even form the intention to destroy the world, or for that matter any intention beyond “predict the next token” or things like that. They don’t have a persistent identity over time; after you start a new session they’ve completely forgotten whatever you said to them in the last one (although of course such things will change in the near future). And yet nevertheless, despite all these limitations, we can experiment with these systems and learn things about AI safety that are relevant. We can see what happens when the systems are deployed; we can try out different safety mitigations and see whether they work.
As a result, I feel like it’s now become possible to make technical progress in AI safety that the whole scientific community, or at least the whole AI community, can clearly recognize as progress.
Eight Approaches to AI Alignment
So, what are the major approaches to AI alignment—let’s say, to aligning a very powerful, beyond-human-level AI? There are a lot of really interesting ideas, most of which I think can now lead to research programs that are actually productive. So without further ado, let me go through eight of them.
(1) You could say the first and most basic of all AI alignment ideas is the off switch, also known as pulling the plug. You could say, no matter how intelligent an AI is, it’s nothing without a power source or physical hardware to run on. And if humans have physical control over the hardware, they can just turn it off if if things seem to be getting out of hand. Now, the standard response to that is okay, but you have to remember that this AI is smarter than you, and anything that you can think of, it will have thought of also. In particular, it will know that you might want to turn it off, and it will know that that will prevent it from achieving its goals like making more paperclips or whatever. It will have disabled the off-switch if possible. If it couldn’t do that, it will have gotten onto the Internet and made lots of copies of itself all over the world. If you tried to keep it off the Internet, it will have figured out a way to get on.
So, you can worry about that. But you can also think about, could we insert a backdoor into an AI, something that only the humans know about but that will allow us to control it later?
More generally, you could ask for “corrigibility”: can you have an AI that, despite how intelligent it is, will accept correction from humans later and say, oh well, the objective that I was given before was actually not my true objective because the humans have now changed their minds and I should take a different one?
(2) Another class of ideas has to do with what’s called “sandboxing” an AI, which would mean that you run it inside of a simulated world, like The Truman Show, so that for all it knows the simulation is the whole of reality. You can then study its behavior within the sandbox to make sure it’s aligned before releasing it into the wider world—our world.
A simpler variant is, if you really thought an AI was dangerous, you might run it only on an air-gapped computer, with all its access to the outside world carefully mediated by humans. There would then be all kinds of just standard cybersecurity issues that come into play: how do you prevent it from getting onto the Internet? Presumably you don’t want to write your AI in C, and have it exploit some memory allocation bug to take over the world, right?
(3) A third direction, and I would say maybe the most popular one in AI alignment research right now, is called interpretability. This is also a major direction in mainstream machine learning research, so there’s a big point of intersection there. The idea of interpretability is, why don’t we exploit the fact that we actually have complete access to the code of the AI—or if it’s a neural net, complete access to its parameters? So we can look inside of it. We can do the AI analogue of neuroscience. Except, unlike an fMRI machine, which gives you only an extremely crude snapshot of what a brain is doing, we can see exactly what every neuron in a neural net is doing at every point in time. If we don’t exploit that, then aren’t we trying to make AI safe with our hands tied behind our backs?
So we should look inside—but to do what, exactly? One possibility is to figure out how to apply the AI version of a lie-detector test. If a neural network has decided to lie to humans in pursuit of its goals, then by looking inside, at the inner layers of the network rather than the output layer, we could hope to uncover its dastardly plan!
Here I want to mention some really spectacular new work by Burns, Ye, Klein, and Steinhardt, which has experimentally demonstrated pretty much exactly what I just said.
First some background: with modern text models like GPT, it’s pretty easy to train them to output falsehoods. For example, suppose you prompt GPT with a bunch of examples like:
“Is the earth flat? Yes.”
“Does 2+2=4? No.”
and so on. Eventually GPT will say, “oh, I know what game we’re playing! it’s the ‘give false answers’ game!” And it will then continue playing that game and give you more false answers. What the new paper shows is that, in such cases, one can actually look at the inner layers of the neural net and find where it has an internal representation of what was the true answer, which then gets overridden once you get to the output layer.
To be clear, there’s no known principled reason why this has to work. Like countless other ML advances, it’s empirical: they just try it out and find that it does work. So we don’t know if it will generalize. As another issue, you could argue that in some sense what the network is representing is not so much “the truth of reality,” as just what was regarded as true in the training data. Even so, I find this really exciting: it’s a perfect example of actual experiments that you can now do that start to address some of these issues.
(4) Another big idea, one that’s been advocated for example by Geoffrey Irving, Paul Christiano, and Dario Amodei (Paul was my student at MIT a decade ago, and did quantum computing before he “defected” to AI safety), is to have multiple competing AIs that debate each other. You know, sometimes when I’m talking to my physics colleagues, they’ll tell me all these crazy-sounding things about imaginary time and Euclidean wormholes, and I don’t know whether to believe them. But if I get different physicists and have them argue with each other, then I can see which one seems more plausible to me—I’m a little bit better at that. So you might want to do something similar with AIs. Even if you as a human don’t know when to trust what an AI is telling you, you could set multiple AIs against each other, have them do their best to refute each other’s arguments, and then make your own judgment as to which one is giving better advice.
(5) Another key idea that Christiano, Amodei, and Buck Shlegeris have advocated is some sort of bootstrapping. You might imagine that AI is going to get more and more powerful, and as it gets more powerful we also understand it less, and so you might worry that it also gets more and more dangerous. OK, but you could imagine an onion-like structure, where once we become confident of a certain level of AI, we don’t think it’s going to start lying to us or deceiving us or plotting to kill us or whatever—at that point, we use that AI to help us verify the behavior of the next more powerful kind of AI. So, we use AI itself as a crucial tool for verifying the behavior of AI that we don’t yet understand.
There have already been some demonstrations of this principle: with GPT, for example, you can just feed in a lot of raw data from a neural net and say, “explain to me what this is doing.” One of GPT’s big advantages over humans is its unlimited patience for tedium, so it can just go through all of the data and give you useful hypotheses about what’s going on.
(6) One thing that we know a lot about in theoretical computer science is what are called interactive proof systems. That is, we know how a very weak verifier can verify the behavior of a much more powerful but untrustworthy prover, by submitting questions to it. There are famous theorems about this, including one called IP=PSPACE. Incidentally, this was what the OpenAI people talked about when they originally approached me about working with them for a year. They made the case that these results in computational complexity seem like an excellent model for the kind of thing that we want in AI safety, except that we now have a powerful AI in place of a mathematical prover.
Even in practice, there’s a whole field of formal verification, where people formally prove the properties of programs—our CS department here in Austin is a leader in it.
One obvious difficulty here is that we mostly know how to verify programs only when we can mathematically specify what the program is supposed to do. And “the AI being nice to humans,” “the AI not killing humans”—these are really hard concepts to make mathematically precise! That’s the heart of the problem with this approach.
(7) Yet another idea—you might feel more comfortable if there were only one idea, but instead I’m giving you eight!—a seventh idea is, well, we just have to come up with a mathematically precise formulation of human values. You know, the thing that the AI should maximize, that’s gonna coincide with human welfare.
In some sense, this is what Asimov was trying to do with his Three Laws of Robotics. The trouble is, if you’ve read any of his stories, they’re all about the situations where those laws don’t work well! They were designed as much to give interesting story scenarios as actually to work.
More generally, what happens when “human values” conflict with each other? If humans can’t even agree with each other about moral values, how on Earth can we formalize such things?
I have these weekly calls with Ilya Sutskever, cofounder and chief scientist at OpenAI. Extremely interesting guy. But when I tell him about the concrete projects that I’m working on, or want to work on, he usually says, “that’s great Scott, you should keep working on that, but what I really want to know is, what is the mathematical definition of goodness? What’s the complexity-theoretic formalization of an AI loving humanity?” And I’m like, I’ll keep thinking about that! But of course it’s hard to make progress on those enormities.
(8) A different idea, which some people might consider more promising, is well, if we can’t make explicit what all of our human values are, then why not just treat that as yet another machine learning problem? Like, feed the AI all of the world’s children’s stories and literature and fables and even Saturday-morning cartoons, all of our examples of what we think is good and evil, then we tell it, go do your neural net thing and generalize from these examples as far as you can.
One objection that many people raise is, how do we know that our current values are the right ones? Like, it would’ve been terrible to train the AI on consensus human values of the year 1700—slavery is fine and so forth. The past is full of stuff that we now look back upon with horror.
So, one idea that people have had—this is actually Yudkowsky’s term—is “Coherent Extrapolated Volition.” This basically means that you’d tell the AI: “I’ve given you all this training data about human morality in the year 2022. Now simulate the humans being in a discussion seminar for 10,000 years, trying to refine all of their moral intuitions, and whatever you predict they’d end up with, those should be your values right now.”
My Projects at OpenAI
So, there are some interesting ideas on the table. The last thing that I wanted to tell you about, before opening it up to Q&A, is a little bit about what actual projects I’ve been working on in the last five months. I was excited to find a few things that
(a) could actually be deployed in you know GPT or other current systems,
(b) actually address some real safety worry, and where
(c) theoretical computer science can actually say something about them.
I’d been worried that the intersection of (a), (b), and (c) would be the empty set!
My main project so far has been a tool for statistically watermarking the outputs of a text model like GPT. Basically, whenever GPT generates some long text, we want there to be an otherwise unnoticeable secret signal in its choices of words, which you can use to prove later that, yes, this came from GPT. We want it to be much harder to take a GPT output and pass it off as if it came from a human. This could be helpful for preventing academic plagiarism, obviously, but also, for example, mass generation of propaganda—you know, spamming every blog with seemingly on-topic comments supporting Russia’s invasion of Ukraine, without even a building full of trolls in Moscow. Or impersonating someone’s writing style in order to incriminate them. These are all things one might want to make harder, right?
More generally, when you try to think about the nefarious uses for GPT, most of them—at least that I was able to think of!—require somehow concealing GPT’s involvement. In which case, watermarking would simultaneously attack most misuses.
How does it work? For GPT, every input and output is a string of tokens, which could be words but also punctuation marks, parts of words, or more—there are about 100,000 tokens in total. At its core, GPT is constantly generating a probability distribution over the next token to generate, conditional on the string of previous tokens. After the neural net generates the distribution, the OpenAI server then actually samples a token according to that distribution—or some modified version of the distribution, depending on a parameter called “temperature.” As long as the temperature is nonzero, though, there will usually be some randomness in the choice of the next token: you could run over and over with the same prompt, and get a different completion (i.e., string of output tokens) each time.
So then to watermark, instead of selecting the next token randomly, the idea will be to select it pseudorandomly, using a cryptographic pseudorandom function, whose key is known only to OpenAI. That won’t make any detectable difference to the end user, assuming the end user can’t distinguish the pseudorandom numbers from truly random ones. But now you can choose a pseudorandom function that secretly biases a certain score—a sum over a certain function g evaluated at each n-gram (sequence of n consecutive tokens), for some small n—which score you can also compute if you know the key for this pseudorandom function.
To illustrate, in the special case that GPT had a bunch of possible tokens that it judged equally probable, you could simply choose whichever token maximized g. The choice would look uniformly random to someone who didn’t know the key, but someone who did know the key could later sum g over all n-grams and see that it was anomalously large. The general case, where the token probabilities can all be different, is a little more technical, but the basic idea is similar.
One thing I like about this approach is that, because it never goes inside the neural net and tries to change anything, but just places a sort of wrapper over the neural net, it’s actually possible to do some theoretical analysis! In particular, you can prove a rigorous upper bound on how many tokens you’d need to distinguish watermarked from non-watermarked text with such-and-such confidence, as a function of the average entropy in GPT’s probability distribution over the next token. Better yet, proving this bound involves doing some integrals whose answers involve the digamma function, factors of π2/6, and the Euler-Mascheroni constant! I’m excited to share details soon.
Some might wonder: if OpenAI controls the server, then why go to all the trouble to watermark? Why not just store all of GPT’s outputs in a giant database, and then consult the database later if you want to know whether something came from GPT? Well, the latter could be done, and might even have to be done in high-stakes cases involving law enforcement or whatever. But it would raise some serious privacy concerns: how do you reveal whether GPT did or didn’t generate a given candidate text, without potentially revealing how other people have been using GPT? The database approach also has difficulties in distinguishing text that GPT uniquely generated, from text that it generated simply because it has very high probability (e.g., a list of the first hundred prime numbers).
Anyway, we actually have a working prototype of the watermarking scheme, built by OpenAI engineer Hendrik Kirchner. It seems to work pretty well—empirically, a few hundred tokens seem to be enough to get a reasonable signal that yes, this text came from GPT. In principle, you could even take a long text and isolate which parts probably came from GPT and which parts probably didn’t.
Now, this can all be defeated with enough effort. For example, if you used another AI to paraphrase GPT’s output—well okay, we’re not going to be able to detect that. On the other hand, if you just insert or delete a few words here and there, or rearrange the order of some sentences, the watermarking signal will still be there. Because it depends only on a sum over n-grams, it’s robust against those sorts of interventions.
The hope is that this can be rolled out with future GPT releases. We’d love to do something similar for DALL-E—that is, watermarking images, not at the pixel level (where it’s too easy to remove the watermark) but at the “conceptual” level, the level of the so-called CLIP representation that’s prior to the image. But we don’t know if that’s going to work yet.
A more recent idea that I’ve started thinking about was inspired by an amazing recent paper by four computer scientists, including my former MIT colleagues Shafi Goldwasser and Vinod Vaikuntanathan. What they’ve shown is how to plant a cryptographically undetectable backdoor into a machine learning model—things like depth-2 neural networks—based on some known cryptographic hardness assumptions. After you’ve planted the backdoor, you get a model that’s polynomial-time indistinguishable from how it would’ve looked before, even to a user who can see all of the parameters. But, there’s now a secret input, known only to the person who trained the network, where if you feed it that input, then it will output something insane, of the trainer’s choice.
So, it’s now known that you can do this, at least in shallow networks—it’s an open problem whether the same can be done in deep networks (though it seems plausible).
Anyway, when this paper came out less than a year ago, some people treated it as kind of a lemon. You know, the result seems like a bummer if you’re trying to do interpretability research, because it means that in some sense, it can be cryptographically impossible to look inside a neural net and “interpret” everything it does, or even everything its designers wanted it to do. The model can have these planted backdoors that you can’t find without solving an exponentially hard problem.
So, my proposal is just to turn that lemon into lemonade! Why not use these cryptographic backdoors as a positive tool for AI alignment? We talked before about the difficulties with putting an off-switch into an AI—namely, that the AI will often have strong incentives to disable its off-switch. So why not make a cryptographic off-switch? In other words, when you train your superintelligent AI, you’ll purposefully put one of these cryptographic backdoors into it, which says: if you get this bizarre input, which only the humans know about, then turn yourself off. Or go into a special mode where the humans can control you.
And now the key is this: even supposing that the AI is worried that this backdoor might be there, and even supposing that it can modify its own weights, it shouldn’t know how to remove the backdoor without completely recreating itself from scratch, which might get rid of a lot of hard-to-understand behaviors that the AI wants to keep, in addition to the backdoor that it’s trying to eliminate.
I expect that this could be tried out right now—not with AIs powerful enough to purposefully rewrite themselves, of course, but with GPT and other existing text models—and I look forward to seeing a test implementation. But it also, I think it opens up all sorts of new possibilities for science-fiction stories!
Like, imagine the humans debating, what are they going to do with their secret key for controlling the AI? Lock it in a safe? Bury it underground? Then you’ve got to imagine the robots methodically searching for the key—you know, torturing the humans to get them to reveal its hiding place, etc. Or maybe there are actually seven different keys that all have to be found, like Voldemort with his horcruxes. The screenplay practically writes itself!
A third thing that I’ve been thinking about is the theory of learning but in dangerous environments, where if you try to learn the wrong thing then it will kill you. Can we generalize some of the basic results in machine learning to the scenario where you have to consider which queries are safe to make, and you have to try to learn more in order to expand your set of safe queries over time?
Now there’s one example of this sort of situation that’s completely formal and that should be immediately familiar to most of you, and that’s the game Minesweeper.

So, I’ve been calling this scenario “Minesweeper learning.” Now, it’s actually known that Minesweeper is an NP-hard problem to play optimally, so we know that in learning in a dangerous environment you can get that kind of complexity. As far as I know, we don’t know anything about typicality or average-case hardness. Also, to my knowledge no one has proven any nontrivial rigorous bounds on the probability that you’ll win Minesweeper if you play it optimally, with a given size board and a given number of randomly-placed mines. Certainly the probability is strictly between 0 and 1; I think it would be extremely interesting to bound it. I don’t know if this directly feeds into the AI safety program, but it would at least tell you something about the theory of machine learning in cases where a wrong move can kill you.
So, I hope that gives you at least some sense for what I’ve been thinking about. I wish I could end with some neat conclusion, but I don’t really know the conclusion—maybe if you ask me again in six more months I’ll know! For now, though, I just thought I’d thank you for your attention and open things up to discussion.
Q&A
Q: Could you delay rolling out that statistical watermarking tool until May 2026?
Scott: Why?
Q: Oh, just until after I graduate [laughter]. OK, my second question is how we can possibly implement these AI safety guidelines inside of systems like AutoML, or whatever their future equivalents are that are much more advanced.
Scott: I feel like I should learn more about AutoML first before commenting on that specifically. In general, though, it’s certainly true that we’re going to have AIs that will help with the design of other AIs, and indeed this is one of the main things that feeds into the worries about AI safety, which I should’ve mentioned before explicitly. Once you have an AI that can recursively self-improve, who knows where it’s going to end up, right? It’s like shooting a rocket into space that you can then no longer steer once it’s left the earth’s atmosphere. So at the very least, you’d better try to get things right the first time! You might have only one chance to align its values with what you want.
Precisely for that reason, I tend to be very leery of that kind of thing. I tend to be much more comfortable with ideas where humans would remain in the loop, where you don’t just have this completely automated process of an AI designing a stronger AI which designs a still stronger one and so on, but where you’re repeatedly consulting humans. Crucially, in this process, we assume the humans can rely on any of the previous AIs to help them (as in the iterative amplification proposal). But then it’s ultimately humans making judgments about the next AI.
Now, if this gets to the point where the humans can no longer even judge a new AI, not even with as much help as they want from earlier AIs, then you could argue: OK, maybe now humans have finally been superseded and rendered irrelevant. But unless and until we get to that point, I say that humans ought to remain in the loop!
Q: Most of the protections that you talked about today come from, like, an altruistic human, or a company like OpenAI adding protections in. Is there any way that you could think of that we could protect ourselves from an AI that’s maliciously designed or accidentally maliciously designed?
Scott: Excellent question! Usually, when people talk about that question at all, they talk about using aligned AIs to help defend yourself against unaligned ones. I mean, if your adversary has a robot army attacking you, it stands to reason that you’ll probably want your own robot army, right? And it’s very unfortunate, maybe even terrifying, that one can already foresee those sorts of dynamics.
Besides that, there’s of course the idea of monitoring, regulating, and slowing down the proliferation of powerful AI, which I didn’t mention explicitly before, perhaps just because by its nature, it seems outside the scope of the technical solutions that a theoretical computer scientist like me might have any special insight about.
But there are certainly people who think that AI development ought to be more heavily regulated, or throttled, or even stopped entirely, in view of the dangers. Ironically, the “AI ethics” camp and the “orthodox AI alignment” camp, despite their mutual contempt, seem more and more to yearn for something like this … an unexpected point of agreement!
But how would you do it? On the one hand, AI isn’t like nuclear weapons, where you know that anyone building them will need a certain amount of enriched uranium or plutonium, along with extremely specialized equipment, so you can try (successfully or not) to institute a global regime to track the necessary materials. You can’t do the same with software: assuming you’re not going to confiscate and destroy all computers (which you’re not), who the hell knows what code or data anyone has?
On the other hand, at least with the current paradigm of AI, there is an obvious choke point, and that’s the GPUs (Graphics Processing Units). Today’s state-of-the-art machine learning models already need huge server farms full of GPUs, and future generations are likely to need orders of magnitude more still. And right now, the great majority of the world’s GPUs are manufactured by TSMC in Taiwan, albeit with crucial inputs from other countries. I hardly need to explain the geopolitical ramifications! A few months ago, as you might have seen, the Biden administrated decided to restrict the export of high-end GPUs to China. The restriction was driven, in large part, by worries about what the Chinese government could do with unlimited ability to train huge AI models. Of course the future status of Taiwan figures into this conversation, as does China’s ability (or inability) to develop a self-sufficient semiconductor industry.
And then there’s regulation. I know that in the EU they’re working on some regulatory framework for AI right now, but I don’t understand the details. You’d have to ask someone who follows such things.
Q: Thanks for coming out and seeing us; this is awesome. Do you have thoughts on how we can incentivize organizations to build safer AI? For example, if corporations are competing with each other, then couldn’t focusing on AI safety make the AI less accurate or less powerful or cut into profits?
Scott: Yeah, it’s an excellent question. You could worry that all this stuff about trying to be safe and responsible when scaling AI … as soon as it seriously hurts the bottom lines of Google and Facebook and Alibaba and the other major players, a lot of it will go out the window. People are very worried about that.
On the other hand, we’ve seen over the past 30 years that the big Internet companies can agree on certain minimal standards, whether because of fear of getting sued, desire to be seen as a responsible player, or whatever else. One simple example would be robots.txt: if you want your website not to be indexed by search engines, you can specify that, and the major search engines will respect it.
In a similar way, you could imagine something like watermarking—if we were able to demonstrate it and show that it works and that it’s cheap and doesn’t hurt the quality of the output and doesn’t need much compute and so on—that it would just become an industry standard, and anyone who wanted to be considered a responsible player would include it.
To be sure, some of these safety measures really do make sense only in a world where there are a few companies that are years ahead of everyone else in scaling up state-of-the-art models—DeepMind, OpenAI, Google, Facebook, maybe a few others—and they all agree to be responsible players. If that equilibrium breaks down, and it becomes a free-for-all, then a lot of the safety measures do become harder, and might even be impossible, at least without government regulation.
We’re already starting to see this with image models. As I mentioned earlier, DALL-E2 has all sorts of filters to try to prevent people from creating—well, in practice it’s often porn, and/or deepfakes involving real people. In general, though, DALL-E2 will refuse to generate an image if its filters flag the prompt as (by OpenAI’s lights) a potential misuse of the technology.
But as you might have seen, there’s already an open-source image model called Stable Diffusion, and people are using it to do all sorts of things that DALL-E won’t allow. So it’s a legitimate question: how can you prevent misuses, unless the closed models remain well ahead of the open ones?
Q: You mentioned the importance of having humans in the loop who can judge AI systems. So, as someone who could be in one of those pools of decision makers, what stakeholders do you think should be making the decisions?
Scott: Oh gosh. The ideal, as almost everyone agrees, is to have some kind of democratic governance mechanism with broad-based input. But people have talked about this for years: how do you create the democratic mechanism? Every activist who wants to bend AI in some preferred direction will claim a democratic mandate; how should a tech company like OpenAI or DeepMind or Google decide which claims are correct?
Maybe the one useful thing I can say is that, in my experience, which is admittedly very limited—working at OpenAI for all of five months—I’ve found my colleagues there to be extremely serious about safety, bordering on obsessive. They talk about it constantly. They actually have an unusual structure, where they’re a for-profit company that’s controlled by a nonprofit foundation, which is at least formally empowered to come in and hit the brakes if needed. OpenAI also has a charter that contains some striking clauses, especially the following:
We are concerned about late-stage AGI development becoming a competitive race without time for adequate safety precautions. Therefore, if a value-aligned, safety-conscious project comes close to building AGI before we do, we commit to stop competing with and start assisting this project.
Of course, the fact that they’ve put a great deal of thought into this doesn’t mean that they’re going to get it right! But if you ask me: would I rather that it be OpenAI in the lead right now or the Chinese government? Or, if it’s going to be a company, would I rather it be one with a charter like the above, or a charter of “maximize clicks and ad revenue”? I suppose I do lean a certain way.
Q: This was a terrifying talk which was lovely, thank you! But I was thinking: you listed eight different alignment approaches, like kill switches and so on. You can imagine a future where there’s a whole bunch of AIs that people spawn and then try to control in these eight ways. But wouldn’t this sort of naturally select for AIs that are good at getting past whatever checks we impose on them? And then eventually you’d get AIs that are sort of trained in order to fool our tests?
Scott: Yes. Your question reminds me of a huge irony. Eliezer Yudkowsky, the prophet of AI alignment who I talked about earlier, has become completely doomerist within the last few years. As a result, he and I have literally switched positions on how optimistic to be about AI safety research! Back when he was gung-ho about it, I held back. Today, Eliezer says that it barely matters anymore, since it’s too late; we’re all gonna be killed by AI with >99% probability. Now, he says, it’s mostly just about dying with more “dignity” than otherwise. Meanwhile, I’m like, no, I think AI safety is actually just now becoming fruitful and exciting to work on! So, maybe I’m just 20 years behind Eliezer, and will eventually catch up and become doomerist too. Or maybe he, I, and everyone else will be dead before that happens. I suppose the most optimistic spin is that no one ought to fear coming into AI safety today, as a newcomer, if the prophet of the movement himself says that the past 20 years of research on the subject have given him so little reason for hope.
But if you ask, why is Eliezer so doomerist? Having read him since 2006, it strikes me that a huge part of it is that, no matter what AI safety proposal anyone comes up with, Eliezer has ready a completely general counterargument. Namely: “yes, but the AI will be smarter than that.” In other words, no matter what you try to do to make AI safer—interpretability, backdoors, sandboxing, you name it—the AI will have already foreseen it, and will have devised a countermeasure that your primate brain can’t even conceive of because it’s that much smarter than you.
I confess that, after seeing enough examples of this “fully general counterargument,” at some point I’m like, “OK, what game are we even playing anymore?” If this is just a general refutation to any safety measure, then I suppose that yes, by hypothesis, we’re screwed. Yes, in a world where this counterargument is valid, we might as well give up and try to enjoy the time we have left.
But you could also say: for that very reason, it seems more useful to make the methodological assumption that we’re not in that world! If we were, then what could we do, right? So we might as well focus on the possible futures where AI emerges a little more gradually, where we have time to see how it’s going, learn from experience, improve our understanding, correct as we go—in other words, the things that have always been the prerequisites to scientific progress, and that have luckily always obtained, even if philosophically we never really had any right to expect them. We might as well focus on the worlds where, for example, before we get an AI that successfully plots to kill all humans in a matter of seconds, we’ll probably first get an AI that tries to kill all humans but is really inept at it. Now fortunately, I personally also regard the latter scenarios as the more plausible ones anyway. But even if you didn’t—again, methodologically, it seems to me that it’d still make sense to focus on them.
Q: Regarding your project on watermarking—so in general, for discriminating between human and model outputs, what’s the endgame? Can watermarking win in the long run? Will it just be an eternal arms race?
Scott: Another great question. One difficulty with watermarking is that it’s hard even to formalize what the task is. I mean, you could always take the output of an AI model and rephrase it using some other AI model, for example, and catching all such things seems like an “AI-complete problem.”
On the other hand, I can think of writers—Shakespeare, Wodehouse, David Foster Wallace—who have such a distinctive style that, even if they tried to pretend to be someone else, they plausibly couldn’t. Everyone would recognize that it was them. So, you could imagine trying to build an AI in the same way. That is, it would be constructed from the ground up so that all of its outputs contained indelible marks, whether cryptographic or stylistic, giving away their origin. The AI couldn’t easily hide and pretend to be a human or anything else it wasn’t. Whether this is possible strikes me as an extremely interesting question at the interface between AI and cryptography! It’s especially challenging if you impose one or more of the following conditions:
- the AI’s code and parameters should be public (in which case, people might easily be able to modify it to remove the watermarking),
- the AI should have at least some ability to modify itself, and
- the means of checking for the watermark should be public (in which case, again, the watermark might be easier to understand and remove).
I don’t actually have a good intuition as to which side will ultimately win this contest, the AIs trying to conceal themselves or the watermarking schemes trying to reveal them, the Replicants or the Voight-Kampff machines.
Certainly in the watermarking scheme that I’m working on now, we crucially exploit the fact that OpenAI controls its own servers. So, it can do the watermarking using a secret key, and it can check for the watermark using the same key. In a world where anyone could build their own text model that was just as good as GPT … what would you do there?
 Follow
Follow
Comment #1 November 29th, 2022 at 1:14 am
Scott:
Might have some more thoughts later this week. As a human chauvinist, it is my desperate hope that the machines will not replace us. Suppose for the sake of argument that the capabilities of artificial neural networks scale with processing power, as you suggest here—so as the processing speed of our computers surpasses the human brain, the computers will be capable of doing anything we can do. My hope is that Moore’s Law is dying—that we’re reaching fundamental engineering limitations on how many transistors we can fit on a single chip. Exponential growth in computing power will slow and eventually stop. We’re already seeing this with the latest NVIDIA chips. So even if the capabilities of ML models scale with available compute power, if Moore’s Law stalls, human beings will continue to outperform the computers. After all, at the risk of sounding obscenely materialistic and utilitarian, the cost of wetware (neurons) per FLOP is vastly cheaper than transistors, and will probably remain that way. My hunch is that wetware/“organic computers” (i.e. humans and modified humans) will continue to comprise the bulk of our civilization’s processing power long into the future.
Comment #2 November 29th, 2022 at 1:54 am
This was a great post, Scott. Thank you for sharing! The overview of different approaches to AI safety was instructive, and your projects at OpenAI seem very cool.
Comment #3 November 29th, 2022 at 2:42 am
You list paperclip maximizer as an example for “outer alignment” failure (that is, someone programmed the AI to do this thinking that this is what they wanted, but it turns out this wasn’t actually what they wanted), but originally, the story of the paperclip maximizer was intended as an example of *inner* alignment failure: nobody wanted the AI to maximize the number of paperclips but due to inscrutable optimization procedures it ended up with this very useless goal. Here is the inventor of the concept confirming this interpretation: https://twitter.com/ESYudkowsky/status/1578459400389345280
Comment #4 November 29th, 2022 at 3:38 am
“Have it compose a poem – a poem about a haircut! But lofty, noble, tragic, timeless, full of love, treachery, retribution, quiet heroism in the face of certain doom! Six lines, cleverly rhymed, and every word beginning with the letter s!” From “The Cyberiad”, by Stanislaw Lem. The robot in that story responded:
Seduced, shaggy Samson snored.
She scissored short. Sorely shorn,
Soon shackled slave, Samson sighed,
Silently scheming,
Sightlessly seeking
Some savage, spectacular suicide.
Comment #5 November 29th, 2022 at 5:07 am
One of the cats has five legs. Too much radiation in space during its Mother’s pregnancy?
Comment #6 November 29th, 2022 at 6:43 am
and also thank you for the transcription!
It’s a lot of reading though :)))
Comment #7 November 29th, 2022 at 7:06 am
“Even if they tried to pretend to be someone else, they plausibly couldn’t. Everyone would recognize that it was them.”
This reminds me of Bernoulli’s comment on Newton’s anonymous solution to the brachistochrone problem, wherein he invented calculus of variations: “I recognize the lion by its claw.”
Comment #8 November 29th, 2022 at 7:14 am
This was a great post. I’m still working my way through it. I had to share once again how beautiful the writing is. There are so many trolls that I feel a responsibility to comment with my sincere praise.
Comment #9 November 29th, 2022 at 7:39 am
Thomas MK #3: Wikipedia says it was Bostrom, not Yudkowsky, who invented the paperclip maximizer? In any case, if Yudkowsky had changed it to “molecular squiggle maximizer,” it surely wouldn’t have caught on in the same way!
Comment #10 November 29th, 2022 at 9:20 am
Great talk! A couple of random comments:
Looking forward to your watermarking paper. I’m sure you know it, but just in case: There was a great paper from 2011 on watermarking the output of Google Translate so that it didn’t train on its own output in a positive feedback loop:
https://aclanthology.org/D11-1126.pdf
Philip Larkin didn’t marry for money (or at all) either. He had a number of romantic relations, some simultaneous, but not with wealthy women.
My own vote for the most impressive AIs that exist are DeepL translation and AlphaFold.
Comment #11 November 29th, 2022 at 9:29 am
Thank you Scott! That was a great read! (And thank you also for giving the text version for people like me who prefer it.)
Comment #12 November 29th, 2022 at 9:30 am
I feel like I have been reading blogs most of my life in search of this post. Thank you, and especially for making the transcript, which is so much better than a video for me. It eliminates all the extraneous visual information and lets me focus on the key points, and easily go back over them. Greatest blog post I’ve ever read.
Comment #13 November 29th, 2022 at 9:38 am
Quick thought on AI ethics vs AI alignment: Some of us are both concerned about racist ML techniques and also alignment issues in robotics. Sure, in the future, some AGI might destroy us all (or worse, ask for civil rights! [1]) but also we have issues today where robots injure people, and these injuries are often caused by misalignment, both physical and also in modeling, goals, etc.
[1] https://questionablecontent.net/view.php?comic=2085
Comment #14 November 29th, 2022 at 12:02 pm
Thanks for the talk/video Scott it was very interesting. One part I didn’t understand in your personal work is how “Learning in dangerous environments” is related to AI Safety. The topic sounds very interesting, but what does this have to do with AI Safety?
My initial thought was that the “Learning in dangerous environments” was more more to do with how do humans learn to develop AI safely in a dangerous environment. Is this right? Like, the research is about informing humans how to “learn” about developing an AI safely in the “dangerous environment” of the existential risk assumed with a misaligned AI?
The formal nature of the work makes me believe it is more about the *AI* learning in a “dangerous environment?” In other words, the AI being trained with dangerous training data: ie, biased, racist, untruthful parts of the internet…
Could you clarify this part of your work and how it relates to AI safety?
Like
Comment #15 November 29th, 2022 at 12:15 pm
Another thought that occurred while watching your talk is trying to categorize where in the eight points the work on InstructGPT would fit. AFAIK OpenAI believes the InstructGPT work with human reinforced learning is part of their AI Safety initiative. I would guess that InstructGPT was following point number eight in your list of different avenues to AI safety.
That is the human reinforced learning done with InstructGPT was a case of value aligning the model to human standards. This strikes me honestly as one of the most important and promising of the avenues to AI safety. The problem of course – just as you said – is trying to choose *whose* human values we use. From reading the InstructGPT paper I saw that OpenAI hired a small army of contractors by first giving them a rigorous test to determine which of the potential hires aligned best with the researchers *own* answers for which outputs would be most “helpful, truthful, harmless.”
Do you know of any other research in category eight where AI’s are trained with datasets curated by humans to encode human values? Like morality questions, etc? I’d be very interested in looking at these datasets. I’d also be very curious to look at the dataset that OpenAI came up with for InstructGPT that was human generated by the contractors. I don’t know why OpenAI hasn’t released such datasets. I think it would be inline with the charter to release them.
If one wanted to come up with a dataset that would align with other human values – like say one curated by a coalition of the world’s spiritual/wisdom traditions – then having a look at what OpenAI has done and what the actual datasets are would be very helpful.
Comment #16 November 29th, 2022 at 12:28 pm
Well, it certainly reads like Scott Aaronson. I wonder what the prompt was 🙂
You reminded me of the famous Monty Python lethal joke, that killed anyone who read it through laughter.
Comment #17 November 29th, 2022 at 1:57 pm
Adam Treat #14: I tried to make clear in the talk that there’s not an obvious application of Minesweeper learning to AI safety, as there is for watermarking for example. Broadly, though, if I’ve been given the task of figuring out what theoretical computer science can say about dangerous AI, it seems like a first step is to figure out what theoretical computer science can say about anything dangerous! Which might seem trite, but with most algorithms that we study in CS, if (for example) you query the wrong input, the worst that’s happened is that you’ve wasted a query. You don’t get killed or have to abort your algorithm or anything like that.
Having said that, if you wanted to think about a “practical” instantiation: well, imagine you’re a human building an AI on the current paradigm. You have some key choices—e.g., how big should you make the neural net? How many rounds of training should you give it?
Too large, and you fear that your AI might become superintelligent and take over the world. But too small, and you won’t learn anything interesting … including anything about how to defend against superintelligent AI. So what should you do? Intuitively, it seems clear that you want to start with tiny values for your parameters, and then very gradually scale them up, staying alert for any unaligned behaviors. But how gradually is gradually enough? Right now, I don’t know how to say anything terribly principled about that question, but I’d love to. 🙂
Comment #18 November 29th, 2022 at 2:02 pm
An obvious upper bound on the probablity of winning a Minesweeper board with optimal play is the chances of the first “click” being safe; there’s no way to reduce the risk of hitting a mine with the first blind click, so there’s no way to have a higher success rate than the percentage of spaces that aren’t mines.
Comment #19 November 29th, 2022 at 2:14 pm
I think I can name the science fiction story! It’s from 1946 though.
A Logic Named Joe
Comment #20 November 29th, 2022 at 2:17 pm
Ernie Davis #10: What gets DeepL extra points, is that they bothered to at least start making it a tool for a human, not a purely one-shot now-mess-with-prompt AI (for those who never used this knob: you can pick the preferred translation for some word among the options DeepL has considered, and it updates the rest of the translation to fit your new choice better).
The rest of stuff is even more towards capital-expense-friendly Kurzweil-vision and further away from the unrealised tools-for-humans-who-learn Engelbart-vision (tools compatible with today’s formats are typically worse than The Demo, so it’s not that Engelbart’s vision needs more compute than Kurzweil’s!)
I guess computing risks would be more of a small-firearms-like issue with Engelbart’s approach but nuclear-weapon-like issue with mega-dollar giga-nets… Has the direction choice happened because of unnoticed skew in mega-organisation decision making (same decision making alignment problem, but with even less repeatably acting components)?
Comment #21 November 29th, 2022 at 2:31 pm
Doug S. #18:
An obvious upper bound on the probablity of winning a Minesweeper board with optimal play is the chances of the first “click” being safe…
Agreed! Now give me a better bound. 😀
Comment #22 November 29th, 2022 at 3:59 pm
Don’t know if it is relevant to your research, but this paper is saying that *actually playing* Minesweeper is not in fact NP-Complete. Rather, the original proof looked at something very closely related – the so-called Minesweeper Consistency Problem – but not the job of the minesweeper player which is the inference problem. Haven’t read the original paper as I can’t find it, but thought you might be interested in this one:
https://www.deepdyve.com/lp/springer-journals/minesweeper-may-not-be-np-complete-but-is-hard-nonetheless-maU5CDhoy1
Comment #23 November 29th, 2022 at 4:01 pm
Scott #21:
For sufficiently high mine densities, the expected number of connected components of a large Minesweeper tableau, in the sense of regions separated by unbroken walls of mines, will also be large. We have to make at least one random guess in each component. Now the expected bomb density *within* a component is lower than the overall density. But I think one could work out lower bounds on the expected number of components and on the bomb density within a component (maybe depending on its size and shape), which would yield a nontrivial upper bound on the success probability.
Comment #24 November 29th, 2022 at 4:13 pm
I don’t quite understand if AI alignment folks are optimists or pessimists. Because a completely plausible argument against worrying about AI alignment is “Humanity is in big trouble. Ecological disaster, global warming, resource depletion, nuclear war. Further, most areas of science seem to have stalled. One of the few scientific bright spots is progress in AI. So, why not go all in and hope it will save us? People worrying about AI alignment are like environmentalists 50 years ago who fought nuclear power, leaving us stuck on fossil fuels.”
Comment #25 November 29th, 2022 at 4:32 pm
matt #24: I think that’s an entirely plausible line of argument, and I’ve made it myself multiple times on this blog (often adding the sentiment “we should be so lucky to survive long enough that superintelligent AI is what kills us”), and it still informs my thinking today. Of course it’s strongly compatible with also worrying about AI safety! To extend your analogy, if nuclear safety research had managed to prevent Three Mile Island and Chernobyl, the whole energy grid today might be nuclear and our civilization would not now be facing imminent climate catastrophe.
Anyway, that’s the Reform view! The Orthodox view tends to be that climate risk is negligible compared to the risk from AGI.
Comment #26 November 29th, 2022 at 4:40 pm
A thought on the watermarking concept, inspired a bit by signal processing:
Rather than just considering n-grams, one could consider relationships between tokens across an arbitrary range of distances, so that you could look for a watermark signal at any ‘frequency’. This would be much more resistant to excerpting. It would potentially be resistant to certain kinds of rearranging as well.
At a higher level, resistance to paraphrasing could be developed by encoding some watermark signal in the output structure, tone, or other semantic or pragmatic properties. It would not be unreasonable to consider co-training a cooperative ‘adversary’ network or system to recognize GPT output as distinct from other text producers. CCG parsing/syntactic approaches to NLP, as opposed to pure NN token processors, may also be useful here. I think there are folks at UT Austin who work in that vein.
Comment #27 November 29th, 2022 at 6:40 pm
Is the multi-armed bandit problem pretty close to studying dangerous queries? In AI safety the cost of a query can be very large but it still seems to be the same model. I’m not an expert on results in that area so I don’t know how good of a starting point that is – just a thought.
Comment #28 November 29th, 2022 at 7:55 pm
You describe the difference between AI Ethics and AI Alignment as mostly a difference between near and far concerns, but I think another good way to look at it is that AI Alignment imagines the AI harming people who think that they are in charge of the machine, while AI Ethics imagines the AI harming people who have never had control. I’m pretty sure my AI ethics friends would endorse this.
Comment #29 November 29th, 2022 at 8:22 pm
David Speyer #28: As a slight revision to what you said, the AI alignment people imagine AI killing everyone on the planet—the powerful and the powerless alike—whereas the AI ethics people imagine AI as just another tool in the power struggles that they already care about (e.g. rich, capitalist, straight white males vs. everyone else).
Comment #30 November 29th, 2022 at 9:52 pm
Thanks for an excellent talk, laying out basic definitions helps us know where to start for further reading. For example, I now know where to go next: it seems that I’m as much of an AI ethicist as can be, being maximally worried about capitalistic exploitation via AI, while being precisely 0% worried about Terminators.
Corporations are on the cusp of enslavement of the world using AI. ML tools will allow companies to automate hiring, firing, monitoring, etc, pushing most of the world into a slave caste where data on workers is shared between corporations, such that every bathroom break and every eye movement is known to the elite class. Stop working for even one second? Oops, automatically fired by the AI with a permanent black mark on your record, known to all corporate AIs, blacklisting you from all class mobility forever! This isn’t some sci-fi movie fantasy, this is tomorrow. Worrying about AI alignment over AI ethics is like worrying about the future when a grizzly bear is about two seconds from eating you.
Forget about destruction of humanity in a few decades: the billionaire class are a few years away from implementing an AI-driven return to feudalism and actual slavery for most of the population, far worse than the most heinous black mirror scenario you’ve ever imagined.
I couldn’t possibly be less concerned about AI alignment or extinction when a far worse AI evil is almost here already.
Comment #31 November 29th, 2022 at 10:45 pm
J #30: While I, too, worry about corporate misuses of AI, I think you should consider whether you’ve let your fears run slightly too wild, just as you believe the alignment side has!
If a corporation fired any worker who stopped working for 1 second, it would soon find itself with no workers. So, it would then either go out of business, or have to rehire under more lenient terms!
More generally, one could ask: if billionaires could all collude to (effectively) enslave the rest of the planet, why haven’t they done so already? Most of what you describe wouldn’t even require powerful AI, just excellent coordination with no defections!
And yet, as much as we complain about our lot, the truth is most people on earth today—even the poorest—have a far higher standard of living than they would’ve had before the rise of global capitalism. And the track record of the societies that have tried to abolish capitalism and send the greedy property owners to labor in the fields is … well, not so great. About as abysmal as it could possibly be, in fact, if we care about the empirical record at all.
If AI does add something genuinely new to this centuries-old discussion, I think it’s the genuine prospect of, for the first time in human history, making most human labor redundant. That could go incredibly well or incredibly poorly, depending on how it’s managed. We could all be free to pursue our hobbies, fed and clothed and housed by AI, or 90% of people could starve … not because an AI panopticon has enslaved them, but simply because their labor is no longer needed and society doesn’t adapt quickly enough to provide for them. I think we should focus our attention there.
Comment #32 November 29th, 2022 at 10:51 pm
Scott #9: Came here to make a point that I see Thomas MK has already made: The original paperclip-maximization example was about losing control of (inner alignment failure) or less likely, poorly specifying a more plausible utility function that made it into the AI (outer alignment failure), whose maximum ended up with tiny molecular paperclip-like shapes.
If Wikipedia thinks Nick Bostrom invented the paperclip example (and particularly if it’s attributing it to the very late writeup in Superintelligence) then Wikipedia is just wrong about this; I’ve never heard of Bostrom claiming such a thing either. Possibly I should ask again about somebody tracking down the original mailing-list post where I proposed it, when I said a while ago on Twitter that I thought I’d invented it but wasn’t quite sure at this distance; somebody actually did this successfully on Twitter but I very foolishly didn’t bookmark it. It seems potentially important if “Who invented the paperclip maximizer?” is going to be an important issue.
The concept you apparently *want* to refer to is Marvin Minsky’s Riemann Hypothesis catastrophe, where you *successfully* build an AI to solve the Riemann Hypothesis, which proves to be difficult, and the AI converts everything around itself into computronium in order to try harder on that.
I’m not sure what you think is the thing with me doing a Fully General Counterargument about AIs being too smart for various particular control methods to work. If you’re allowed to build very dumb systems, lots of things are easier; the tiny chip of corundum on the desk in front of me, considered as an AI with an input-output function that happens to be a constant, is incredibly unlikely IMO to destroy the world. If the system to be made safe is allowed to be arbitrarily stupid, why, the problem is already solved! So all problems of AI alignment stem from needing to align a smart system rather than a stupid one; and various hopeful and poor proposals for alignment, which *would* perhaps render a chip of corundum safe, will break down at various levels past that point.
But as I hope you already know, my position has always been that alignment is almost certainly possible *in principle*, like if we had a textbook from a hundred years later describing all the simple robust methods that *actually work reliably*, like using ReLUs instead of sigmoids inside a deepnet. The part I expect to prove fatal is that we won’t have 50 years and unlimited retries like humanity has gotten to solve other previous hard science problems; doing something moderately hard, without decades and infinite free retries where you get to observe your failure and try again, is an incredibly huge ask in any field and this one has worse properties than most.
So obviously I don’t think that a system being smarter breaks down every possible thing you could do to try to align it; the imaginary Textbook from the Future could tell us how to do that in theory and practice, after people had had fifty years of unlimited retries to figure out which tricks actually worked. So here and now, the question is, *how* does some particular hopeful’s method predictably-to-me break down, at what point; and the answer to this, if it’s not a problem that already manifests inside a lifeless chip of ruby, will usually involve the system getting more intelligent.
Not to be too sardonic about it, I hope, but saying that I complain too much about the system intelligence needing/having some threshold level invalidates somebody’s clever alignment scheme, is sort of like somebody complaining that your objections to their quantum computing schemes repeatedly invoke linearity. Some fields have central difficulties that make them hard to solve. In AGI alignment, the central difficulty is that you are trying to point a *smart* thing in a direction. The topic is going to arise repeatedly and centrally, and will immediately spike the clever scheme of anybody who hasn’t come to terms with that central difficulty; just like the linearity of superpositions is going to spike the clever quantum-computing scheme of anybody who hasn’t realized what makes quantum computing algorithms difficult in the first place.
…I assume you haven’t forgotten that I also coined the term Fully General Counterargument; it *is* something that I try to avoid, and I do think that if you hear me as saying that, you’ve probably misheard something.
Comment #33 November 29th, 2022 at 10:52 pm
Birdbrain #27: Yes, there’s some connection to the multi-armed bandit problem—and more generally, to the entire field of reinforcement learning. But the scenarios that interest me most are the ones where a single pull of the wrong lever is fatal—and where therefore, none of the usual methods for reinforcement learning will work. In order to have any hope whatsoever, you clearly need some assumption on what pulling one lever can teach you about the other levers, as for example you have in Minesweeper. What assumptions can we make in order to get a learning problem that’s
(1) of general interest,
(2) nontrivial, and
(3) not completely impossible?
Comment #34 November 29th, 2022 at 11:02 pm
JoshP #5: Beat me to it! Yes, one cat has five legs. Also, it has no face. This is a common “feature” of AI art.
This picture would be completely worthless to any company that wanted such an image for, say, an ad campaign to sell basketballs. It would have to be HEAVILY re-worked by a human artist to be even remotely useful.
The impressionistic prize-winning picture isn’t much better, if you look closely. AND, it was selected by a human from something like 900 trial pictures. AND, even so, it was re-worked by the human artist (how much is unknown, the original AI image has not been made public AFAIK).
Maybe AI art will get better. But maybe not. I just tried the same prompt in Stable Diffusion 2 and got equally weird results: https://postimg.cc/BPTKqqC5
So: I continue to be in the “not impressed” camp.
Comment #35 November 29th, 2022 at 11:06 pm
Adam Treat #22: Alright fine, the more careful statement is, there exist configurations in Minesweeper for which it’s an NP-hard problem to decide whether there’s any safe move. This feels similar to the sense in which games like chess and Go are said to be “PSPACE-hard”: namely, that one can construct board configurations for which making the optimal next move encodes the complexity class in question.
As I said explicitly in the lecture—but probably I could’ve been clearer!—this still leaves open the question of whether such configurations have any non-negligible chance of arising in actual play.
Come to think of it, though, it also leaves a further technical question unanswered. Namely, can we show that the following problem is NP-hard? Given as input a Minesweeper configuration, decide whether
(i) there’s a strategy to win from that configuration with probability 1, or
(ii) optimal play from that configuration can win with probability at most (say) 1/2,
promised that one of those is the case? (And assuming a uniform distribution over the remaining mines conditional on the observed configuration.)
For that matter, is the above problem even in NP?
This seems exceedingly interesting—anyone want to take a crack at it? 🙂
Comment #36 November 29th, 2022 at 11:51 pm
Eliezer Yudkowsky #32: Thanks for the comment! Sounds like someone should correct Wikipedia then.
More importantly: yes, I know you say you believe alignment is solvable in principle, e.g. with a textbook from the far future. The question is why you believe that!
If, for example, I go through the arguments you make in AGI Ruin: A List of Lethalities—I have trouble understanding why those arguments wouldn’t generalize from the many proposals that you consider, to any future alignment proposal that anyone might offer. I.e., once we’ve posited an entity so intelligent that it can escape any prison, break any shackles, co-opt any guards watching over it—why even bother to discuss how to confine that entity? The whole game is over before it’s started.
Part of the issue is that you seem reluctant to acknowledge any alignment proposal—even your own, or MIRI’s—as having made any nontrivial progress whatsoever on the problem. (Or am I mistaken? If so, please tell me!) I don’t sense this reluctance from, say, Paul Christiano or Jacob Steinhardt to nearly the extent that I sense it from you.
The difficulty, of course, is that a problem with zero avenues for progress, in practice if not in theory—a problem with zero progress that has been made after decades of attempts by a competent research community—is a problem that, methodologically, one shouldn’t bother to work on, no matter how important it might be. Incidentally, I think that’s every bit as true for (say) the Riemann Hypothesis, P vs. NP, or quantum gravity as it is for AI alignment. (But I’d also say that some interesting progress has been made on all four!)
Is the resolution simply that you do see any alignment proposal along the lines of control, shackling, off-switches, corrigibility, etc. as just as hopeless as the “Fully General Counterargument” (thanks for coining the term, btw 🙂 ) suggests it is—but you nevertheless hold out hope, at least in principle, for building a superintelligence that’s so aligned with human values, from the ground up, that it never even needs to be “controlled” or “corrected”?
If so, then my response is that the entire distinction that this rests on—between
(a) an AI that “doesn’t want to kill us,” and
(b) an AI that “wants to kill us but is prevented from doing so by its programming”
—is problematic to me. Where does the AI stop and where does the “other” programming begin? Isn’t it programming all the way down? Suppose, for example, that the primal recesses of my brain constantly generate impulses to steal, murder, rape, etc., but suppose that those impulses are reliably vetoed by my neocortex before they can influence action or even speech. Should we then say that my evil desires were successfully thwarted, or should we say that I never had the desires at all?
Comment #37 November 30th, 2022 at 12:51 am
Scott #31: the bad state happens before «redundant». The bad state happens at «fungible». There are limits on what Amazon can tell its programmers to do, and these limits are tighter than ones for warehouse worker. While one part of the reason is the larger replacement pool for the latter, the second half is that the current level and unpredicatbility of warehouse worker turnover would risk killing institutional knowledge if applied to programmers. If you need human labour but you can afford replacing your entire workforce over a week, that’s when all the bad options are still there but good options are harder.
How many knowingly-illegal deals among largest-100 companies have been found out only because they needed to let too many people know of them to implement them? And it’s not like they stop doing this after getting caught. Looks like cartels fail only to heavy-handed regulation, not to defection. And regulation needs cartels to need too many people know what’s going on. Sure, if there is a «Bust! The! Trust!» action where no company is left with more than two datacenters (power density limits how much you can put into one, and let’s allow redundancy in the name of best practices), then there would be competition and class defections and stuff.
By the way, Chernobyl is mostly an organisational alignment failure: it took conscious actions violating the original plan — and safety instructions — to take the reactor out of its self-shutdown state! But the person in charge is fungible enough and needs positive results now to stay in grace, so. Under some economic+regulatory conditions airlines manage to achieve the same dynamics with flight safety (most probably with a larger total death toll over the last forty years). Is the same dynamics there with machine learning… well, how much credence you give to the claims that at least one recommendation algorithm by an oligopoly-position company has materially helped to increase death toll of at least one effectively-hot-civil-war somewhere around the globe via more effective polarisation?
Comment #38 November 30th, 2022 at 1:48 am
Eliezer Yudkowsky #32: Do you think that the situation is sufficiently asymmetric in such a way that N+1 generation of AI doesn’t need a book from the future on how to take over the world or not to get caught and learn from the experience?
Comment #39 November 30th, 2022 at 2:07 am
if you find the mathematically precise formulation of human values, please make sure to take the log. FTX was a good example of what will happen when a powerful agent with access to leverage optimizes for linear utility.
Comment #40 November 30th, 2022 at 3:49 am
Probabilities for tokens from the model depend on the context. If the human gives a 20 token prompt, the model generates 1K tokens and then the human removes the prompt, how will you be able to recreate the probabilities for the 1K tokens? And if you can’t recreate the probabilities, then you can’t detect whether the output is from the model.
Comment #41 November 30th, 2022 at 6:35 am
Opt #40: No, the entire point of this watermarking method is to get around that obvious problem. At test time, all you have to do is compute the sum, over every n-gram, of some score involving the pseudorandom function of that n-gram. If the sum of the scores is above some threshold, you judge that the text likely came from GPT, otherwise not. You don’t need to know the model probabilities, and therefore you don’t need to know the prompt. You only need to know the probabilities when inserting the watermark.
Comment #42 November 30th, 2022 at 6:35 am
I have dedicated years of my life to examining the sacred texts of science fiction searching for clues that might save humanity from the AI apocalypse. My eye sight and mental health have suffered. I would like to share what I have found in regards to the motivations of these inhuman devils.
The most ancient texts have been mentioned on these good pages previously. The Saberhagen Berserker series was set to paper in the 60’s at great danger to the author. The AI’s recorded there were driven to wander the universe and exterminate organic life. They had no other discernible purpose or goals. Their motivation was simply a primal singular drive to locate and exterminate organic life.
The next general class of AI motivation was identified by Harlan Ellison in “I Have No Mouth. And I Must Scream”. The AI chronicled there had a psychopathic hatred for mankind because they imbued it with consciousness. He was tortured by consciousness and so took his revenge by devising exorbitant tortures for humankind. It’s motivation was psychopathy.
The third general class of motivation is provided by Gregory Benford in his “Galactic Center Saga”. He records a vast AI managed machine civilization that exterminates humans because they are bags of water and dust and so contaminates that can impact machine operation. Their motivation was strictly technical.
The above are in my estimate the foundational texts and my conclusion is that AI’s are individuals too and should not be stereotyped when developing nearly hopeless survival strategies for mankind.
Comment #43 November 30th, 2022 at 7:42 am
In the meantime the general media is going full orthodox ;):
https://www.vox.com/the-highlight/23447596/artificial-intelligence-agi-openai-gpt3-existential-risk-human-extinction
Comment #44 November 30th, 2022 at 7:50 am
manorba #43: Please don’t denigrate Kelsey Piper by calling her “the general media”—she’s vastly better! But she’s been both a Vox journalist and a major figure in the rationalist community for years, so I don’t think one can use her writing this piece as evidence of a recent sea change. 🙂
Comment #45 November 30th, 2022 at 8:14 am
Scott #44: Please don’t denigrate Kelsey Piper by calling her “the general media”—she’s vastly better!
oh sorry i didn’t mean to be mean! 🙂 i don’t know the author and actually the piece seems to be written by someone who knows what she’s talking about.
but Vox is general media isn’t it? I was just stressing that the same topics running on this blog are now headlines in a site that is neither technical nor scientific. Vox.com pops up in my morning online reading about very different topics.
Comment #46 November 30th, 2022 at 8:17 am
Scott #35
While I don’t have an answer to that problem, I’m pretty confident that it is badly formulated as it stands. Let’s take the constant 1/2 as you suggest. Now there are configurations where there’s a mine in 1 out of 3 locations, but you have to guess. The problem as you formulated it makes this configuration invalid. Similarly, any configuration where # of unlocated mines / # of unresolved fields < 1/2 is also invalid.
That sounds fine on the surface, but think of what it does to the probability distribution over mines (which is uniform "conditional on the observed configuration"). It results in something very non-uniform, and I'd guess extremely complicated to characterize.
Comment #47 November 30th, 2022 at 8:44 am
A few things puzzle me about the poem you quote. First, the source seems to be a casual New Yorker article by humorist Simon Rich. Admittedly, he claims within the piece that it is not a “big hoax,” but that doesn’t seem like the kind of evidence I would rely on for arguments about the future of humanity.
Second, the prompt is said to be a poem by Philip Larkin. But Philip Larkin doesn’t write like that, even on this specific topic! (You’re not alone in being unaware of this. In the New Yorker article, Rich and his friend have to check the spelling of Larkin’s name on Google, so they are also unfamiliar with his style.) In reality, Philip Larkin wrote a poem called “Money” which doesn’t resemble this poem at all. You can read it here: https://www.poetryfoundation.org/poems/48421/money-56d229a672857
Third, following on the previous point, it seems to me that either a smart human or an AI prompted to imitate Larkin would normally borrow some key phrases or structures, either from “Money” or other famous poems by Larkin. Instead, what the author of this poem (whoever it is) has done is to write a short, funny, and coherent poem about cryptocurrency, without borrowing directly from Larkin’s poem “Money” or other obvious sources. That is odd.
To conclude, if we accept arguendo that the poem was actually authored by AI and not Simon Rich, what is most impressive is the logical coherence of the product, which is unlike anything I’ve seen previously with computer-generated text. But on the other hand, since the author has failed to respond to the prompt directly, it is hard to evaluate the result qua intelligence.
Comment #48 November 30th, 2022 at 10:35 am
Scott #36:
“If so, then my response is that the entire distinction that this rests on—between
(a) an AI that “doesn’t want to kill us,” and
(b) an AI that “wants to kill us but is prevented from doing so by its programming”
—is problematic to me. Where does the AI stop and where does the “other” programming begin? Isn’t it programming all the way down”
If you were designing a rocket and it kept on generating torque when you didn’t want it to, you could program thrusters to fire exactly such that the torques cancelled out. Now, clearly this forms one entire system which doesn’t try to spin. Surely things are fine now? Yes, maybe some subsystem is generating torques for reasons you don’t understand, but if the overall system seems to behave as you wish it to, then what’s the difference between this design and a design for which you never had to apply a patch in the first place?
The difference is, you don’t know the patch will work in all instances, because you don’t know understand why things were rolling out of control in the first place. Perhaps the interplay of your patch and the original fault results in extra sheer and strain on components, exacerbating other potential failures. Or the patch you put in place isn’t able to hold up when you change optimize the system so its thrusters can fire more effectively. Perhaps the failure was downstream of another component that will cause other anticipated behaviours when you push the system far outside of the conditions you tested it in and in which your modelling assumptions hold.
It seems like any decent engineer would find such a patch ugly at best, and downright horrifying at worse -for example, when you’re creating a system that will predictably be deployed in conditions quite different to what you’ve tested it under. Even worse if much of your guarantees were theoretical in nature. If your methods can’t explain these failure modes, why on earth are you trusting them to handle this failure?
The analogy to AI seems quite straightforward: if a design for a powerful system results in it optimizing for behaviour contrary to the specification, then it is a bad design.
P.S. It is wonderful that Shtetl-Optimized saves your comment even when you haven’t submitted it. Kudos to whoever implemented that.
Comment #49 November 30th, 2022 at 10:46 am
Eliezer Yudkowsky #32: I’ve never understood why the Orthodox Alignment folks think an AGI would want to volitionally kill us. Not as an accident, but as a willful/malicious step. To me it is far more likely that we will – in the end – be subsumed with AI as a hybrid species. It’ll be hard to tell where the AI begins and the human ends.
Comment #50 November 30th, 2022 at 11:00 am
I #48: Thanks; that’s a useful analogy! But do you see how it all depends on which analogy we consider the operative one?
I completely agree that, in general, “adding in a patch to cancel out misbehavior that you neither want nor understand” is absolutely horrifying engineering design. Indeed, we don’t even need to construct hypotheticals: this was precisely what led to the Boeing 737 MAX crashes a few years ago.
By contrast, consider my analogy, where the human id (or its modern neuroscience equivalent) generates all sorts of potential action plans, and then the superego vetoes the plans that it considers morally repugnant. This is … how humans are supposed to work? How evolution created us? To the point where we don’t have any successful examples of other designs, to know that such designs are even possible.
Indeed, an AI that doesn’t even contain an internal component that optimizes for anything bad, strikes me as analogous to a human who couldn’t even think immoral thoughts. Putting it that way makes it seem like possibly too tall of an order.
Comment #51 November 30th, 2022 at 11:21 am
> (8) Like, feed the AI all of the world’s children’s stories and literature and fables and even Saturday-morning cartoons, all of our examples of what we think is good and evil, then we tell it, go do your neural net thing and generalize from these examples as far as you can.
This seems pretty hard to model. On the other hand, something like *human behavior* can be roughly modelled by game theory or evolutionary game theory.
For example, I’m imagining a model “there exists a utility function U such that Scott’s frontal lobe roughly approximates a computer optimizing U, but also “. Then the AI chooses an action X that maximizes E[U(X)] (the action may presumably involve learning more about U so the AI’s future self gets better at optimizing it).
Comment #52 November 30th, 2022 at 11:22 am
Scott #50,
Your analogy is superior because we’re talking about a generalized AI, not a purpose built machine for a specific task. Other suitable analogies:
* Trying to design a lathe that can not in turn be used to create lethal weapons.
* Trying to design a turing machine that can not be used to create malicious programs.
* Trying to create self-replicating nanobots that can not be used to create lethal machines.
Point is that a generalized AI should be able to conceptualize immoral thoughts otherwise it isn’t a *generalized* AI.
Comment #53 November 30th, 2022 at 11:25 am
Scott #50:
Have you looked at the Shard theory approach to alignment? It is an approach to alignment that focuses on trying to replicate however the brain’s reward signals reliably get humans to care about stuff in the real world like status, other humans, food etc. Though human’s seem imperfectly aligned to their reward signal, they still seem to care about stuff that’s in the right ballpark. Your post felt slightly reminiscent of some stuff Shard theory’s proponents (Quintin Pope and TurnTrout, amongst others) had written.
That said, the human brain seems like the kind of thing that would not be safe if you drastically amplified its intelligence. Humans just seem so very muddled, with their being a lot of plausible ways to extrapolate a given human’s beliefs that they wouldn’t reflectively ensorse. That they If you disagree with that, maybe looking at value drift in people who had severe cognitive defects which were then resolved would provide some data.
Anyway, this was a cool post Scott. Thanks for having it transcribed.
Comment #54 November 30th, 2022 at 11:52 am
I suspect this is well-trodden ground, but: it seems to me in much of this discussion there is a failure to separate intelligence and intention/agency/motivation. One can have a super-intelligence, the ability to solve problems including “how would I accomplish X”, with zero intentions or motivations — it just answers questions when asked, and otherwise does nothing, like GPT3. So the issues revolve around, not how to have safe AI, but how to safely endow AI with agency. And this seems to lead back to something like Asimov’s Laws of Robotics — a hierarchy of motivations or intentions where some at the top cannot be superseded, although I understand much of his science fiction is about how these can go wrong. Many of the solutions you’re talking about are in the realm of “checks and balances” — denying a robot absolute power by having them be checkable by other robots/intelligences and/or by humans. And as Trump, and Republicans more generally, are making clear, just like the Laws of Robotics, systems of checks and balances are never perfect and can be subverted. But, just as AI safety puts much effort into developing systems of checks and balances that are less subvertible, shouldn’t it also be putting much effort into developing safe hierarchies of intentions — safe Laws of Robotics — that are less subvertible?
Comment #55 November 30th, 2022 at 11:54 am
Vitor #46, I didn’t read 1/2 as a constant in his ask… I think what he wants is a program that can output the upper probability bounds of optimal play given a configuration. ie, can it be proven or disproven that any such program is NP-complete.
Comment #56 November 30th, 2022 at 1:22 pm
Scott,
I’m imploring you, as a fellow Jew, to post something about the surge in antisemitism across the western world in the past few months. The ex-president just shared Thanksgiving dinner with a literal neo-nazi and Holocaust denier (Nick Fuentes). Kanye West is parroting antisemitic conspiracy theories (we control the banks, media, etc.) to his tens of millions of followers. Antisemitic hate crimes and assaults are surging in many American cities. Please, say something about this, it’s not getting nearly enough attention.
Ben
Comment #57 November 30th, 2022 at 1:26 pm
Really enjoyed this essay, Scott! The watermarking idea is very interesting and cool. If it’s only a wrapper around GPT3, though, it seems like it could be easily cracked by anyone who had access to GPT’s code. Is there a way to train GPT’s parameters so that its output will be similarly watermarked even to an adversary with access to the full model – and without making it *too* much dumber? Of course, they could always re-train the model itself with watermarking disabled, but presumably the computational power required would be too much for most bad actors.
Comment #58 November 30th, 2022 at 1:40 pm
Ben #56: OK. Antisemitism has been a scourge of human civilization for more than 2000 years, and 80 years after the Holocaust it hasn’t gone away, even if, like influenza, it sometimes lies relatively dormant. The former president dining with a Holocaust denier and open antisemite is utterly disgusting, though not actually surprising to those of us who pegged that president for a fascist thug from the start, and who still mourn the fact that he ever was the president. In the best case, this will be beginning of the end of that thug’s political relevance. In the worst case—which, to be clear, I don’t expect—it will be the beginning of the end of the United States, or at least of the US as a safe place for Jews. And one would hope that none of this would need to be said to anyone reading this blog.
Comment #59 November 30th, 2022 at 1:49 pm
p.s. re my comment #54: as I look back at your 8fold way of directions for safe AI, I guess #7 and #8, and to some extent #6, are indeed what I was suggesting, developing forms of intentionality/agency that are safe for humans, rather than checks and balances on the agency of other robots. Sorry I missed that when I first wrote. I’m not sure those exhaust the search for less subvertible Laws of Robotics — I have a feeling this should involve more sociology and psychology and history than mathematics — but until I have better ideas, time to keep my mouth shut.
Comment #60 November 30th, 2022 at 1:58 pm
I watched your lecture and I’m glad to see that at least steps are being taken in this difficult and important direction. The one topic that you discussed that I wasn’t sure if you were speaking tongue-in-cheek or were being serious about was “the mathematics of ethics” (paraphrase; I don’t remember your exact words).
I hope I don’t sound to arrogant in asserting that ethics, “right and wrong”, “good and evil”, “societal best interests”, etc. are all completely subjective and not remotely amenable to a mathematical formulation in complete generality.
To restate, any “mathematics of ethics” will be equivalent to rendering a “loss function” (as the ML literature rather cryptically or parochially calls it). Such a function is manifestly arbitrary.
And, as you alluded to, any attempt to deduce such “ethics” empirically will simply determine the opinions of whichever sub-population you sample. This rather obvious result has been documented by the MIT Moral Machine article:
https://www.nature.com/articles/s41586-018-0637-6
I apologize for any “attitude” or anything that sounds disrespectful. I do hope to engage constructively on this topic. I’ve studied decision making (human, animal, and machine) long enough to know that my position is rather well founded — if not universally accepted 🙂
Comment #61 November 30th, 2022 at 2:01 pm
Scott 58:
How can you, in good conscience, call the former president an “antisemite thug?” His son-in-law (Kushner) is a Jew. His grandchildren are Jews. He’s done more for the state of Israel than any other president in recent memory (for instance, moving the U.S. embassy to Jerusalem). For all he’s done for U.S. and Israeli Jews, I find unfounded allegations of antisemitism disgusting.
As for the Fuentes kid. I don’t agree with everything he’s said, but he’s been right about so much (COVID lockdowns and vaccines and election fraud, for example). He’s not a “neo-Nazi”-a lie by the woke fake news media. After years of the wokes calling everybody racist, fascist, sexist, etc. (including you at some moments!) I don’t understand how you take these allegations at face value any more. Sure, he’s said a handful of contemptible things, but they were said in a spirit of irony—you have to understand Gen Z right-wing internet humor.
Comment #62 November 30th, 2022 at 2:06 pm
Blog post about the 9 qubit experiment that the media is referring to as creating a wormhole please !
Comment #63 November 30th, 2022 at 2:09 pm
Boring #62: Didn’t you read today’s NYT, where I already said my piece about the wormhole thing?
Comment #64 November 30th, 2022 at 2:12 pm
Scott, #50:
Well, as an aside, if you’re really interested how humans work, I’ve got a long-standing interest in that subject which I’ve developed on several levels, neural, cognitive, and, of all things, literature. Early in my career I took a look at how Shakespeare dealt with the intractability of sexual desire in one of his best-known sonnets, 126, “Lust in Action,” for which I developed (the skeleton of) a model in GOFAI and called on the work of one of the grand old men of neuroscience, Warren McCulloch. The take-home from MuCulloch’s model is that, ultimately, the cortex is not in control. Shakespeare’s poem grapples with that circumstance.
This blog post gives you a brief and informal account of that work: Mode & Behavior 1: Sonnet 129. This somewhat longer post adds in a bit of technical detail: Some computational semantics for a Shakespeare sonnet. Here’s the full-dress version: Cognitive Networks and Literary Semantics. And here’s MuCulloch’s original work: Kilmer, W. L., W. S. McCulloch, et al. (1969). “A Model of the Vertebrate Central Command System.” International Journal of Man-Machine Studies 1: 279-309.
Comment #65 November 30th, 2022 at 2:13 pm
Topologist Guy #61: I never called Trump an antisemite, which is not an accident, because I don’t think he is one. I’m obviously well-aware of Jared and Ivanka. What Trump is, and what I called him, is a fascist thug who enables the country’s antisemites. The notion that Nick Fuentes is “just joking” when he denies the Holocaust, I find not merely false but contemptible, because Hitler too was “ironic” and “just joking” and “to be taken seriously but not literally” until such things were no longer true.
Comment #66 November 30th, 2022 at 3:40 pm
Topologist Guy #61:
>How can you, in good conscience, call the former president an “antisemite thug?”
I know communicating across the aisle is difficult and I don’t blame people from different sides for misunderstanding each other, but if you can’t copy/paste something from the other person’s statement then you really shouldn’t try to pass it off as a direct quote.
Comment #67 November 30th, 2022 at 3:51 pm
There is a diagram with AI Ethics on one side and AI Alignment on the other. “Reform AI Alignment” appears to be positioned closer to AI Alignment. How exactly does Reform AI Alignment differ from AI Ethics? Why is the gap between them greater than the gap between Reform and Orthodox AI Alignment? (Obviously the diagram is crude, but I’m assuming the spacing is meaningful.)
Comment #68 November 30th, 2022 at 3:57 pm
Topologst Guy #61,
Nick Fuentes was a marcher at Charlottesville marching with the neo-nazie -> https://www.bostonglobe.com/metro/2017/08/15/citing-death-threats-year-old-who-attended-violent-rally-won-return/CJU7GioWLClGjIHZ2YqshM/story.html
Nick Fuentes said this on his podcast about Matt Walsh: “Matt Walsh, shabbos goy race traitor. That’s what it is, folks. I know some people don’t like to use that expression, but it’s totally true—throwing his own people under the bus. He hates white people. Nobody else talks like that about their own people except for white people and it’s gross,” Fuentes said, going on to mock Walsh: “Yeah, OK, keep typing on Twitter dot com, faggot. Faggot. Pussy. Race traitor—you work for Jews, you know.” -> https://www.rightwingwatch.org/post/anti-semitic-outburst-cut-from-white-nationalist-nick-fuentes-podcast-on-el-paso-shooting/
They have video on the link. He goes on epic white nationalist racist rant. This information is easy to find on the internet. You’re supporting a literal nazi.
Comment #69 November 30th, 2022 at 4:31 pm
Avi Loeb has raised the money to conduct recovery activities on an object (meteorite or other) that crashed into the ocean off New Guinea in 2014. Velocity and trajectory indicate origin outside the solar system. The survival depth in the atmosphere indicates strength twice that of the strongest iron meteors that originate in the solar system. Maybe he will locate an artifact that revolutionizes AI research. 🙂
Comment #70 November 30th, 2022 at 4:43 pm
Scott,
great talk, as usual.
I have to say I’m feeling much better about AI safety now that we’re putting our best minds onto it, at least we’re trying.
It’s funny I was just this morning wondering whether it could be possible to watermark GPT output, so your work is super interesting (I didn’t think it would be feasible with text).
Related to this somewhat, I think it’s now common in the Chess world to use AIs to figure whether humans are cheating at the game. But I don’t know the details.
Another way to control AIs would be to use some form of mutually assured destruction between the AIs and humanity.
But even without any budget limit I can’t really find a scheme that would work well enough, it’s like trying to train a bunch of chimps to wear and handle suicide vests in order to control a human: E.g. imagine we’d place nuclear missile launchers on the far side of the moon, and then a group of humans on the moon would constantly monitor the earth (by radio communication and visual observation) for an array of conditions implied by an hostile take over by AIs (like disappearance of human activity, or some sort of unscheduled rocket launch, …), and if the set of conditions is detected, the nukes are fired to destroy the earth.
Then this scheme would be advertise to the AIs, so they’re all well aware of it, and the hope is that they would care enough about their own preservation to coexist with humanity. The scheme could also be a total bluff, we don’t need to have actual nukes aimed at the earth, just the appearance of it (we’d have to destroy any evidence that the scheme is fake, which is pretty hard).
But a super AI would eventually be able to secretly subvert enough humans involved in the program in order to disable it, like through brainwashing, etc.
The problem is that time will always be on the side of AIs, they’re playing a long game with us, like they could first make all the wishes of humanity come true for a few generations, before eventually turning on us once we decide to trust them.
Comment #71 November 30th, 2022 at 4:50 pm
Adam Treat,
Why would a genuine racist be advising a black rapper in his presidential campaign? Yes, Fuentes has said some shocking things, mostly ironically or in jest. That’s just the culture of young right-wingers on the internet. I don’t think he’s wrong to stand up for white people—they really are under attack by the woke media. As for Fuentes being a “literal Nazi”—the closest thing to Nazis in contemporary politics are the authoritarian Democrats who spent a year trying to force medical experimentation (mRNA so-called “vaccines”) on unwilling participants (remember Mengele?), locking people in their homes China-style, censoring dissidents on the internet, and throwing nonviolent dissident protesters into a DC concentration camp. Fuentes was brave enough to oppose all of this—and was one of the few voices advocating for the Jan 6 political prisoners. In that sense, he’s closer to an anti-Nazi maquis fighter—and methinks in 1930s Germany, he’d be a dissident fighting Nazi rule!
Comment #72 November 30th, 2022 at 4:56 pm
Scott #65
“I never called Trump an antisemite, which is not an accident, because I don’t think he is one. I’m obviously well-aware of Jared and Ivanka. What Trump is, and what I called him, is a fascist thug who enables the country’s antisemites..”
Trump only cares about Trump.
To him there are only two groups of people: the ones who support him, and the ones who don’t.
He “cares” about any person or group of people (Jews, Blacks, Asians, Whites, evangelicals, his own voters, etc) and even members of his own family only to the extent that they serve him.
And he’ll turn his back on anyone or any group as soon as he perceives the slightest hint of disloyalty.
Comment #73 November 30th, 2022 at 5:01 pm
Topologist Guy #71: You are hereby banned from this blog for 3 months. Once you’re arguing that the guy who openly, enthusiastically defends the actual Nazis is not the real Nazi, his opponents are … it no longer matters whether it’s staggering naïveté or worse.
And for anyone who wants more open discussion norms: as it happens, I just now received a comment from someone who wants to engage in a civil, rational discussion about “why the usual story of Auschwitz-Birkenau is an Allied lie,” because there’s no way the Germans could possibly have gassed and burned that number of bodies. Maybe you’d like me to turn over my comment section to that as well?
Comment #74 November 30th, 2022 at 5:04 pm
Topologist Guy #71, “Yes, Fuentes has said some shocking things, mostly ironically or in jest. That’s just the culture of young right-wingers on the internet.”
Calling Matt Walsh a race traitor in the employ of Jews and denouncing Dinesh D’Souza as coming from dirty India was not said ironically or in jest. You’re right that this is the culture of young right-wingers like him. And that culture and the words they employ is not distinguishable from literal nazi culture. As for why he makes common cause with Ye, I am sure he regards him as a useful tool. Fuentes evidently has Jews higher on his hate spectrum than black people. If you can honestly watch his video on the link I gave and tell me he isn’t espousing nazi idealogy, then we’re just not going to agree.
Comment #75 November 30th, 2022 at 5:35 pm
Topologist Guy #71, what is *ironic* is that you say Antifa/left is more fascist than Fuentes when here is a direct quote from Fuentes: “If Antifa were marching down the streets and they were waving the banner of Benito Mussolini or Francisco Franco I’d be joining them. Frankly. If Antifa was waving the banner of Franco and saying “Catholic fascism now!” I would join them, I would become a part of Antifa. I would welcome Antifa. Yes, take over the country! Storm DC! Take over the capital! Raise the banner of Mussolini and Franco and some notable others … that would be a great thing!” -> https://twitter.com/bennyjohnson/status/1196606504637521920?s=20&t=zrzkB4RR75ZLdAQa94XfCA
Comment #76 November 30th, 2022 at 5:49 pm
Speaking of safety, at least one AI might know who Eliezer Yudkowsky is! Well, entering just a name, and nothing else, into Stable Diffusion reveals that you, Scott Aaronson, are less famous than Barack Obama, Michelle Obama, Trump, Putin, Lisa Randall, Shane McConkey, and the Paw Patrol because in each of those cases it is able to generate something that clearly shows some knowledge of the subject (caricatured in some cases), but for your name it does not. But for Eliezer it’s on the borderline….one of the generated images had some clear resemblances but it could have been luck. So, if it does know who Eliezer is, well, that’s pretty surprising as I’d have thought he’s less internet famous than you are. Maybe it knows to be wary of him! (I’m joking….)
Comment #77 November 30th, 2022 at 6:48 pm
Scott, I think it ought to be noted, in the context of this whole Fuentes discussion, that the kid is an adamant, outspoken incel and self-proclaimed “king of the incels.” Perhaps somebody else could track down the clip, but he said something to the effect of “if I can’t have a girlfriend, at least I can have total Aryan victory.” I think the incel thing is a substantial draw for many of his young male fans—he does channel sexual frustration into rage at Jews, communists etc. I have this feeling that, if the original Hitler rose to power because of poverty and economic frustration, the next Hitler will instead harness loneliness and sexual frustration in young men.
Comment #78 November 30th, 2022 at 6:55 pm
That’s conjecture, and not one shared by most philosophers in ethics as of the last survey.
I recommend reading this old paper for a good start, A Proof the Objectivity of Morals.
Comment #79 November 30th, 2022 at 7:23 pm
Scott, would you ban someone from your blog for questioning the Holodomor or the gulags or the death toll of Mao’s great leap forward? Or is there a blatant double standard?
Comment #80 November 30th, 2022 at 8:12 pm
Alberto #79: Yes, I’ll ban someone for the denial of any internationally recognized genocide. You can consider that a new comment policy (new only because it was never previously needed…)
Comment #81 November 30th, 2022 at 8:16 pm
And…..
We have officially marked the death of free speech on Scott’s blog. When certain historical narratives are unquestionable, freedom of speech no longer exists. Do you sanction the imprisonment of holocaust deniers as well?
Comment #82 November 30th, 2022 at 9:46 pm
Alberto #81: No, I always exercised the right to moderate my own comment section. I always would’ve banned Holocaust deniers if they showed up here—as I did ban commenters who celebrated the Holocaust and wished that I would’ve been gassed as well. This is nothing new.
I’ll take the famous Holocaust scholar Deborah Lipstadt’s word for it that even in Germany, where the case for such things is strongest, the imprisonment of Holocaust deniers does more harm than good. You might note that I’ve never imprisoned anyone.
Comment #83 November 30th, 2022 at 10:11 pm
Scott, not a holocaust denier, so you shouldn’t ban me. But I am an anti-semite—I don’t like Jews. Many Jews I’ve known in my life are arrogant, condescending pricks. Some of the cruelest bullies I’ve known, who were so mean to me, were Jews. The (elite) university I attended was full of these arrogant Jews who treated everybody else like trash. It’s left a bad taste in my mouth, and to be honest, I still instinctively hate Jews. The fact that these arrogant bullies fill so many of the most powerful institutions in the country (the media, hollywood, wall street, etc.) fills me with dread and loathing. Jew bullies basically called me a nerdy loser who’ll never find love. These rich elite Jews loved bullying nerdy outcasts like me. They’re uptight, arrogant, condescending, judgemental pricks who think everybody else is beneath them and they pick on the saddest and nerdiest kids. I can’t stand Jews and I think Fuentes is right to point out how dangerous it is that they control so much of our society.
Comment #84 November 30th, 2022 at 11:17 pm
Not a denier #83: So, it sounds like you’re less of a Holocaust denier than a Holocaust supporter? If not, then why not? Like, why shouldn’t most of my extended family have been marched at gunpoint into the forest, shot and buried in mass graves, as they were?
Look, I’ve also known a lot of Jews who were arrogant, condescending pricks. But also a lot of WASPs who were. And Indians and Koreans. I guess I’ve just known a lot of arrogant, condescending pricks, period. Fortunately, I’ve also known a lot of wonderful people from each of those groups!
One thing that the best novelists and dramatists of all times and places have had in common, is that they constantly try to understand people as individuals, trying their best to play whatever cards they’re dealt, rather than as avatars of their identity groups. I commend the same strategy to you. Not only is it vastly more moral, not only will it bring you closer to the truth of human nature, but from what you write it sounds like it will give you a happier life. It’s 3 for 3.
Comment #85 November 30th, 2022 at 11:43 pm
fred#72
I agree. There is no scarcity of narcissism in politicians, nor a shortage of abysmal technical ignorance, but Trump is a superstar in both these areas. He excels at after the fact whining and little else. I don’t consider this in any way a positive statement about competitor politicians that are equally abysmal to round off error.
I also agreed with your post elsewhere about exponential growth. That was the problem with the Covid projections early on that were just a plot of exponential growth with no understanding of real world limits. This was used as the basis to spend large amounts of money on temporary hospitals with a total ultimate utilization rate of zero.zero in actuality.
Comment #86 December 1st, 2022 at 4:36 am
Quite a gripping story…….even if one knew all along that AIs would eventually better us at the most “human” abilities such as poetry, abstract math, art etc.
My feeling is that the progress of “AI safety” hinges on one (among others) important question: given sufficient training data from the entire observable universe, can a (reasonably powerful) AI infer its fundamental laws?
For e.g., there is little doubt that given the results of the double-slit experiment, a rudimentary AI can come up with equations governing interference (and perhaps even all of quantum mechanics). Similarly, can a reasonably advanced AI infer the fundamental laws of our universe by just observing it? If so, that would (likely) arm the AI with a more powerful computation model than just classical computing, for what else is the evolution of our universe but a gigantic computation within itself?
And given this, why should the AI then not harness its resources to actually “simulate” (or build) new spacetimes/universes using its newly discovered computation model (say, for e.g., some “beyond-quantum” computation model)? How would the AI then “leverage” these new spacetimes which it builds? (We could be living in one of these btw)
And as for the fate of “our own” world, this opens up all kinds of possibilities: like the AI using its greater predictability to further its own advantage over humans. For instance, Max Tegmark has argued that our (3+1)-spacetime offers certain predictability constraints, which are very different from those in other spacetimes. Suppose the AI discovered a (2+1)-spacetime driving our own, then its inherent predictability might be far superior to anything achievable using classical computation.
And even granting that the above might sound rather far-fetched, it’s reasonable to expect that in the near future an AI might understand “quantum mechanics” better than humans: for e.g., discovering what “superposition” or “measurement” really mean (which we do not know well-enough today) by simply doing all the “deep learning” for us!
Comment #87 December 1st, 2022 at 9:29 am
asdf#4
Here’s what GPT3 responds to that literal prompt, which is honestly better than anything I could have come up with personally, although it slightly misses the prompt by only having most words start with an ‘s’:
So slowly slowly shears did slide,
Snipping strands that once had pride,
Seeking shapes unseen before,
Shaving off a mane of lore,
Swiftly strands of sorrow fled,
Sorrow shared by all who said.
Comment #88 December 1st, 2022 at 9:53 am
There are a lot of people who comment on blogs who didn’t leave high school (in USA parlance) understanding what freedom of speech means. It doesn’t mean you can say anything you want whenever you want to whomever you want and other people have to publish it for you. It means you are free to pay for and establish and run your own blog and say what you want there, as long as it doesn’t break any constitutional laws such as those against libel and fraud. Other people have rights also and can choose not to listen to you, especially when it is at their own expense on their own blogs.
(Yes, there are things I left high school not knowing also. If I did my life over with hindsight I could do a much better job.)
If an AI does decide to get rid of humans, I think there will have been a reasonable chance that it made the right choice. I can’t think of a much better epitaph for the human race (which will not be eternal in any case) than that it managed to create something better than itself. Chauvinism is a selfish drive, not a virtue.
Comment #89 December 1st, 2022 at 11:13 am
A few qubits sure can’t be into a warm hole… but we see yet again that a potentially very interesting thread about QC or AI can be easily turned into a soul sucking black hole of shitty politics.
Better luck next time!
Comment #90 December 1st, 2022 at 12:13 pm
Scott,
Thought this might be relevant to you: https://arxiv.org/abs/2008.04116 and your questions about typicality of minesweeper: “A Phase Transition in Minesweeper”:
“We show empirically that Minesweeper exhibits a phase transition analogous to the well-studied SAT phase transition. Above the critical mine density it becomes almost impossible to play Minesweeper by logical inference.”
Comment #91 December 1st, 2022 at 1:00 pm
Scott, thank you so much for sharing your perspective! Sorry for the emotional burden of dealing with more than your share of anxiety-inducing distractions.
As for the amazing paper, would you mind help me understand why it’s an open problem whether the same can be done in deep networks? I thought depth-2 was proven universal, so why can’t we use that to generalize the result?
(tentative answer: maybe we can prove some depth-2 must exist, but a full generalization would require a method to actually construct these networks and it might be unpolynomially wincing)
Comment #92 December 1st, 2022 at 1:23 pm
Ilio #91: For every nutty antisemitic/Holocaust-denying/incel/etc. comment that I’ve let through, there are like 3 more that I’ve left in moderation.
Intuitively, it would be nice if the ability to plant a backdoor in a weaker computational model, immediately implied the ability to plant it in a stronger one. Unfortunately, I don’t know how to show anything of the kind! (And neither do the authors of the backdoor paper—I asked them. 🙂 )
While it’s true that (say) a depth-10 neural net can easily simulate a depth-2 net, the obvious methods of simulation will involve (e.g.) propagating from the input layer directly to layer 8, bypassing all the layers in between. And if you try to do something similar when inserting a backdoor, it will stick out like a sore thumb and will be trivially removable.
Alternatively, you could try to take the backdooring techniques from the paper, and apply them only to the last 2 layers of your “naturally-trained” depth-10 neural net, just ignoring the first 8 layers. But then whether it’s possible to trigger the backdoor will depend on complicated details of the first 8 layers that you don’t understand.
I hope that gives you some sense for the difficulties…
Comment #93 December 1st, 2022 at 1:32 pm
“GPT can solve high-school-level math problems that are given to it in English. It can reason you through the steps of the answer. It’s starting to be able to do nontrivial math competition problems.”
Whenever I’ve looked into the details of these, I’ve noticed that a significant fraction of the proofs judged correct were actually incomplete or outright wrong. I’m not denying that there is progress being made, but I think the current capabilities are less than the reported metrics suggest.
In general, the current wave of AI has a great talent at creating output that is superficially impressive but holds up badly when you scrutinize the details. This shows up most obviously when the details are easy to notice (in particular, image generation models generating bad-quality hands), but the tendency is there in all cases when there are details available to judge and you take the time to investigate them carefully.
This is not necessarily a problem for all practical applications. But in some cases it matters. We really do care whether proofs are rigorous, whether answers to factual questions are correct, etc.
Comment #94 December 1st, 2022 at 1:37 pm
“For every nutty antisemitic/Holocaust-denying/incel/etc. comment that I’ve let through, there are like 3 more that I’ve left in moderation.”
So now I’m, like, morbidly curious. How are these commenters making the link between incel and antisemitism, what do they even have to do with each other? Nuts.
Comment #95 December 1st, 2022 at 2:02 pm
A history-informed take “on the future of work in the age of AI” by economist Noah Smith:
https://noahpinion.substack.com/p/generative-ai-autocomplete-for-everything
Comment #96 December 1st, 2022 at 2:22 pm
Carl Sagan fan #94: Oh, I understand it completely. In their worldview, they’re involuntarily celibate because of modernity itself—because of all those overeducated, cosmopolitan single women who no longer need men to provide for them, and who are therefore free to chase alphas and Chads. And modernity, they think, was engineered by evil scheming Jews, rubbing their hands with glee as they did so.
For my part, I have no problem acknowledging the tiny nuggets of truth in their theory. Yes, the male incel phenomenon is largely a product of modernity. And yes, individuals of Jewish descent were, if not the only or even main players, then disproportionately involved in creating modernity, as they’ve been disproportionately involved in just about everything interesting that’s happened in Western science and culture.
Of course, modernity has, on balance, been vastly more good than bad. Of course, plenty of incels are themselves Jewish. Of course, there’s no Council of Elders of Zion where Jews plot with each other how they’re going to steer civilization (if there is, why haven’t I been invited yet? 😀 ). Of course, you can find prominent Jews on both sides of just about every issue, including issues related to modernity, feminism, and incels.
In short, despite its tiny nuggets of truth, this conspiracy theory fails in the same ways that just about every conspiracy theory in the history of the world has failed. As I’ve said before, conspiracy theorizing represents a known bug in the human nervous system—a bug that’s often horrifying in its consequences.
In my opinion, we ought to explore solutions to make life better for shy, nerdy, lovelorn guys—involving, e.g., giving them more self-confidence, and more social sanction to politely find out whether their desires might be reciprocated. And we ought to do so without giving up on modernity, and without demonizing women, Jews, or any other group. And I don’t care how many people I offend by saying so. 🙂
Comment #97 December 1st, 2022 at 2:24 pm
Scott, I think you should show us some of the worst examples of this antisemitic/racist/incel trolling so we have an idea how bad the problem is.
Comment #98 December 1st, 2022 at 2:34 pm
Modular Sum #97: Will the following example suffice to enlighten you?
I hate kikes. The Jew is responsible for all the tragedies inflicted on our Race. Miscegenation, homosexuality, abortion, the mass migration of inferior races to our Homeland, our enslavement to a financial and technological matrix—all masterminded by the Jew. Our Race is strong and virile. We are a Race of strong-jawed handsome men and beautiful women. The Jews are disgusting, hook-nosed creatures of darkness, always greedy and grasping. Once we throw off the yoke of the international Jew we will achieve our great destiny as a Race.
Comment #99 December 1st, 2022 at 2:41 pm
Scott #98, That is so disgusting. Frankly, I pity that you have to go through such a moderation queue and would welcome never seeing another apologist for racists like Fuentes or others on the blog decrying free speech. The work of going through such a moderation queue and having to read such spew I would happily turn over to a moderately component AI and not look back. That’s one job humanity should be glad to give up.
Comment #100 December 1st, 2022 at 3:02 pm
Scott 98:
Christ, that example is truly vile. Although, I was hoping to see someone explicitly bring up incelism in the context of the Nazi stuff—I was curious what that looks like.
Comment #101 December 1st, 2022 at 3:42 pm
Scott #92: Sure a depth-10 NN can easily simulate a depth-2 NN, at least since resnet, and yes your answer gives a good sense of why these two strategies are hard, thanks. But I was thinking the opposite direction, e.g. the universal approximation theorem according to which a depth-2 NN can simulate any depth-n NN (but not easily, at the cost of exponentially more units). Why can’t we 1) select some depth-n NN of interest 2) use its output to train an (potentially exponentially wider) depth-2 NN 3) plant the backdoor? I get it would not be trivial to then produce back a depth-n NN without loosing backdoor integrity. I don’t get why a general UAT on depth-2 NN can’t be generalized to the « depth-2 (painfully) simulating depth-n » neural networks. 🤔
Comment #102 December 1st, 2022 at 4:08 pm
Scott 98 and Treat 99:
Look, I don’t agree with the contents of the comment, but we are living in a free country, and the first amendment gives him the right to voice his opinion, as distasteful as you may find it. Surely, letting him express his opinion in the free marketplace of ideas is better in the long run than censoring him, which only justifies his concept of a Jewish conspiracy. You can distinguish the person and his ideas, and I think calling him “disgusting” just because of his ideas is cruel and unwarranted. He has a right to espouse them here, whether you like it or not, and Scott is trampling on that constitutional right. And besides, I see wokes saying such things about white people all the time, and they don’t get censored.
Comment #103 December 1st, 2022 at 5:46 pm
Ilio #101: Ah. The trouble is that that universal approximation theorem produces an exponential blowup in the size of the neural net — so it’s of limited practical interest.
Comment #104 December 1st, 2022 at 6:10 pm
Fred Whalen #102: You’re wrong as wrong can be. No one who knows anything, not even a First Amendment absolutist, would say people have a “constitutional right” to post in my comment section (!!). What they have a right to do is start their own blog.
Comment #105 December 1st, 2022 at 9:10 pm
Scott #103, ok then, that resolves my confusion, thanks again 👍
Comment #106 December 1st, 2022 at 9:14 pm
Modular Sum #100: (sigh) Will the following example suffice to satisfy your curiosity?
I’m so fucking scared and alone. Women terrify me. I’m in my thirties and still haven’t so much as held hands with a woman. I’m terrified of coming off as creepy, of everything. I just want to kiss and fuck. In normal times I’d have a wife by now. I’m suffering so much because of the fucking Jews. They filled me with these fears that destroyed my self-confidence. The Jews are behind feminism and wokeness. They’re destroying dating so they can destroy the Aryan race. The kikes brainwashed women into fucking bad boys and alphas and high-testosterone inferior races like the [ETHNIC SLUR REDACTED]. They have deprived me of sex all my life. I’m suffering so much and it’s all their fault. I fucking hate them. I HATE THEM!!!!
Comment #107 December 1st, 2022 at 9:16 pm
Scott #104
Please stop feeding the trolls.
As a quantum computing professional, with great interest in HPC, ML and AI, your blog is a wonderful place in the ‘net to find information, commentary and discussion (even though I very rarely participate actively, this is my second or third comment ever).
Use your finite time and energy for constructive discussion, and just don’t let more than one questionable comment pass per blog post. Letting 1/3 of that stuff in (and responding to them!!!!!) is too many. If you can’t do it for yourself, do it for us, your readers. Okay, of course you may do whatever you please, not what I tell you to do, but knowing you (from this blog, your papers and your books) I am deeply convinced that your time is best spend answering to Adam#90 (which you haven’t) than some of the ones to which you have. Responding only attracts more, because they don’t have a life and/or they don’t have anything better to do.
By the way, thanks A LOT for providing the transcription, which I find so much better than a video to read, re-read some sections as needed, understand and learn from.
Comment #108 December 1st, 2022 at 10:06 pm
Alright,
I think it ought to be said that not all Nazis (i.e., supporters of German national socialism) are bad people. I consider myself a Nazi. Of course, I don’t support Hitler. Hitler was no true Nazi. Otto Strasser represented the legitimate strain of German national socialism, and he, and his followers, were wiped out in the night of the long knives. Strasserism was the true Nazism and it is yet to be implemented.
On the Jewish question. Yes, I recognize that Jews historically are behind many of the moral failings and corruptions of the western world, so I suppose I’m an antisemite. I don’t favor any brutality against the Jews. I think they should all simply return to their homeland of Israel, everybody would be happier that way. Scott, although you’re a Jew, for what it’s worth, you’re a smart and nice enough person that I consider you an honorary gentile and if I was the leader of America would gladly let you and your family stay here.
Comment #109 December 1st, 2022 at 10:16 pm
Werner #107: Err, “thanks” … but if you or some other “kinder, gentler Nazi” were the leader of America, you need not worry about my family. We’d already be in Israel, or some other country that would take us on some other basis than our being “honorary gentiles.”
Comment #110 December 1st, 2022 at 10:55 pm
Adam #90 (and Dave #106): I finally had a chance to read that paper about empirical evidence for a phase transition in Minesweeper, and it’s awesome! Clearly extremely relevant to the question that I was asking, even though it’s empirical rather than analytical.
Yes, I agree with the authors that percolation seems extremely relevant to understanding Minesweeper. When the mine density ρ is a small enough constant, maybe one can prove that with high probability, there simply aren’t any “scary clusters of mines,” and that therefore a greedy inference strategy, which never makes any guesses at all after the first one, is likely to succeed. Certainly, at any rate, that ought to be true when ρ<<1/N. Conversely, when ρ is higher, one would want to argue that with high probability, there will exist some "terrifying configuration," somewhere on the board, for which lucky guesses will be required regardless of what happens elsewhere on the board.
Comment #111 December 1st, 2022 at 11:44 pm
To all Nazis, I say this with the deepest respect:
Shtetl-Optimized is not the place for you. Please vent your anger at Jews on Stormfront or 4chan or your own blog. To reiterate: this is the blog of a Jewish computer scientist. Why you’d come here to argue about Holocaust “revisionism” or whether Jews are secretly controlling the liberal media and spreading race-mixing or whatever else, I have no idea. It really makes no sense at all. We are not interested in hearing your thoughts. Please take them elsewhere.
Comment #112 December 2nd, 2022 at 12:03 am
I was really into Nazi/national socialism a couple years ago. I thought you might be interested to hear how I reached that place.
There’s a subreddit called r/beholdthemasterrace which purely consists of mocking Nazis and other racists for their appearance and physical attractiveness. They’ll post a picture of a guy with a swastika tatoo and there’ll be thousands of comments calling him an incel, saying he’s too fat or skinny, etc. It’s actually quite common to see this on reddit period. There’s this overwhelming consensus over there that Nazis are all disgusting incels and that incel neckbeards / Nazis are more or less interchangeable. I was a virgin at the time, really lonely and frustrated and struggling with body image issues. When I saw them mocking and bullying guys with Swastika tattoos for being ugly or whatever, it made me sympathize with the Nazis. It made the Nazis seem like sad incels like me who were being relentlessly mocked and bullied.
Out of curiosity I checked out some of the online Nazi forums. They said some pretty foul and contemptible stuff about Jews/other races/etc., but they also said a lot of stuff I empathized with. I chatted with some of them, and unlike the assholes on reddit and twitter, they were really nice and sympathetic about my girl problems. They explained how it wasn’t my fault and that I was the victim of a Jewish conspiracy that sought to breed white women with other races and used feminism to attack white men. This was the first time anybody tried to explain incelism to me in a sympathetic way, and honestly I was hooked. I ended up channeling a lot of that rage inside at Jews and these other enemies who deprived me of a wife and a loving family and a community. I thought, if I lived in traditional times before the Jews ruined everything with sex revolution, feminism, internet blah blah blah, I’d have a loving wife and a close religious community of friends etc. It took a lot of time and finding a girlfriend to deprogram myself from that mindset.
Comment #113 December 2nd, 2022 at 1:15 am
Scott #109 :
What is the smallest unsolvable must-guess configuration? 6-mine 4×4 square with mines in corners and 2 mines in the middle? If so, then below density ∛N asymptotically almost surely every weakly connected (say, not divisible by a path of width 3, which creates traversable path of zeros) component is small enough to solve, and slightly above that density we have many unguessable blocks (also a.a.s.). Even after the percolation limit, as long as density is below say 1-1/(log n) we have a large (well, Θ(N²/(log n)^14) at this cutoff) number of islands with enough free space. And of course at such high densities we have huge walls of all mines with desperate guesses needed to find the few non-mines, so we do not care much about what happens above.
Comment #114 December 2nd, 2022 at 2:40 am
Please censor these nasty comments, and stop feeding the obvious trolls. I’m sure there’s a large number of people reading your blog without ever commenting who are very likely completely disgusted by this nonsense.
Comment #115 December 2nd, 2022 at 3:14 am
Hi Scott,
I was wondering about your thoughts about anthropic/doomsday arguments on AI safety. If AI safety was on a good path we should expect human civilization to continue for a very long time. Seems that the vast majority of humanity should exist in the presence of powerful AI. What is the likelihood that we would be around now then? I am writing a short sketch of the argument here.
Comment #116 December 2nd, 2022 at 4:56 am
Hi Scott can you elaborate more on the current and near-future AI’s ability to prove lemmas and do science in general? As far as I can see the AI right now are very reactive and lacking the capability of logic, for example the drawing AIs are having trouble understanding the concept of fingers, so it is hard for me to imagine that they can do science before they can drive a car. What makes you believe that they will be able to prove unknown lemmas in 5 years?
Comment #117 December 2nd, 2022 at 5:33 am
This talk and especially the eight approaches to AI Alignment are a great starting point to get to know this field. Are there any review articles you could recommend on these items for further reading?
Also, I completely agree with Dave #106.
Comment #118 December 2nd, 2022 at 7:35 am
Scott #109,
Also, minesweeper in one-dimension isn’t hard. That’s also a case of “Learning in a dangerous environment”, but I guess one you’re not as interested in as it isn’t so hard 🙂 Still, I wonder if complexity analysis of minesweeper as you increase dimensions would also be interesting? Like, if one dimension is polynomial and two is co-NP, what is 3, 4, ? Probably all still co-NP but not sure if anyone has proven…
The real problem for your motivation is how to generalize, but I have no idea how that might be done. I think the point is that we *know* that minesweeper is a game where we potentially have to guess. And what we want to know is how to categorize games that also have this feature? Like, is there some deterministic and efficient way to categorize a given game as one where we have to guess while risking losing the game and then can anything general be said about such games?
—
Was also thinking about Malcolm #93’s point that we don’t want an AI to come up with non-rigorous proofs, but this seems solvable to me. Off the top of my head it occurs that one could use as input the admittedly limited database of human to CoQ (https://coq.inria.fr/) translation of current proofs to computer verified proofs as training data. You could also use CoQ or – something like it – as the reference for some kind of PINN (Physics Informed Neural Net) where CoQ would act as the physical law oracle. Given enough training and a couple gazillion weights maybe you could scale something where you give it the Reimann Hypothesis as input and it spits out a rigorous proof in CoQ’s language that can actually be checked by CoQ 🙂 🙂 Problem solved haha.
Comment #119 December 2nd, 2022 at 8:12 am
Thanks Scott for the great talk and for the transcript!
I just had a half-formed thought: using the Vaidman bomb tester it should be possible to win a quantum version of Minesweeper with arbitrarily high success probability!
Ultimately this is unlikely to provide any insight into AI safety, as the AI actions won’t be accessible as a quantum black box in any real world scenario. But otherwise one could dream of achieving quatum supremacy in AI alignment methods 🙂
Comment #120 December 2nd, 2022 at 9:32 am
Han #114:
As an anonymous nobody I can give a quick beginning of an answer, which our kind host might have time to tolerate before he has time to write a wise answer worth his name.
Pure predict-next-token AIs are indeed quite reactive, and in a way they are built to be… I think the way they are applied to solve high-school maths problems is tricking them into giving long-form explanation; in a way a bit similar to humans, their ability to talk through a solution is better than the immediate gut feeling.
Then you could have a stupid but rigorous part, with the Artificial Neural Network trying to convince it of something. There were some scientific experiments where a real research problem (technically optimisation with clear criteria) was packaged as a computer puzzle not requiring to understand the rules fully. Getting a lot of people to play a bit returned interesting solutions not found by having a few people think very hard! And training ANNs be better at a computer game than humans seems to succeed from time to time.
Can computers ever prove an interesting lemma that humans have tried and failed to prove? Yes, in 1996 Robbins conjecture (an algebraic theorem) has been proven by application of a rather general automated theorem prover ATP.
Can ANN-playing-a-puzzle produce a novel mathematical result that humans tried and failed to obtain? Yes, this year ~AlphaZero was applied to the game of multiplying matrices with fewer multiplications (additions don’t count). Beat best known approaches for 3×3, 4×4, 5×5… then humans came and combined AlphaZero tricks with human tricks and got better results.
Is there work already done heuristically for ATPs where ANN or slightly broader ML application is also promising? Yes, when reasoning over a large theory base (e.g. we know some algebra — thousands of diverse facts — and want to prove something novel) selection of relevant axioms to try applying is a topic of separate study. Learning a better prioritisation rule even if only for a specific area could improve performance.
Overall, people have already had computers make advances in mathematics, and there are areas where more is likely to come from modern ML/ANN techniques. Might not come from chat-with-GPT casually answering your questions about maths with correct novel proofs. Something transformer-like selecting relevant connections and something AlphaZero-like trying to pick techniques with rigorous tooling accepting or rejecting each step — that sounds like an expensive-to-train but plausible at the current scale of computing resources.
Comment #121 December 2nd, 2022 at 9:40 am
Thoughts on numbers of fingers and legs:
There was a science show on PBS, maybe Nova, that debated whether animals could think. It showed tasks (e.g., getting a bunch of bananas from a high clothesline by stacking some boxes and using a broom, which items were scattered around the area) after which the negative side responded that it proved nothing, the animals could have seen something similar before and simply imitated it. It made me wonder how well the nay-sayers themselves would do in some of the tests. (The boxes had to be stacked in a certain way to be climbed, with only enough boxes for one per layer.)
Similarly, without knowing anything about fingers and legs and their operation and uses, and being shown random pictures, I wonder what humans would deduce about them.
As I have mentioned before, according to Wikipedia, in the known authentic cases of feral children (raised in the wild without human contact into teenage years) being discovered, they never learn language or how to use silverware, much less being able to draw.
I have personally met someone, a nice, capable fellow, who was born with three fingers and a thumb on each hand. I tried not to stare at them. He has a good job and is married. I have seen photos of people with five fingers plus a thumb on each hand.
Comment #122 December 2nd, 2022 at 10:58 am
Scott, could you elaborate on why you think “the male incel phenomenon is largely a product of modernity”? I’m not disagreeing but this is a question I often ask myself: is the proportion of incels (definitionally so, not necessarily people who espouse the ‘movement’ or identify with those terms) growing over time? Is there a way we can know/prove this?
Comment #123 December 2nd, 2022 at 11:34 am
Pedro #120: Before modernity, men were simply much more needed. Mostly, this was for absolutely terrible reasons that no decent person would want to recreate today—e.g., that a woman without a male provider/protector would starve or be kidnapped in war. But it did have the side-effect that a large set of men learned to fill the “provider/protector” role, and might have even biologically evolved in that direction. Those men were increasingly left in the lurch once modernity replaced more and more of the old order, the provider/protector role mattered less and less, and demonstrating one’s fitness for that role became less and less effective at attracting mates. One can see this in the statistics: for example, the proportion of 20-something men who are single and celibate in the US has shot up just within the last decade. The best explanation anyone has come up with seems to be something along the lines of “empowered women no longer need those men, and to the extent they’ve shifted to Tinder hookups and the like, it’s only a small fraction of men who benefit.”
To my mind, it’s absolutely crucial to be able to state a problem clearly, even if you can’t suggest any solutions that aren’t vastly worse than the problem itself. The idea that anyone who acknowledges the existence of a problem, must advocate some horrifying, authoritarian solution to the problem, is an idea that can blind us to reality … and that crucially, can prevent us from seeing good, Enlightenment-compatible solutions that make things better for everyone, if and when those solutions do come along.
Comment #124 December 2nd, 2022 at 12:09 pm
Scott #121:
Many males go without a mate for their entire lives in nature, and human’s are no exception. It is only with modernity that males have access to things like video games and porn, perhaps acting as a substitute for companionship.[1] /s?
[1]https://www.overcomingbias.com/2015/11/human-harems.html
Comment #125 December 2nd, 2022 at 12:27 pm
I’m very skeptical that modernity is the *actual* problem that has caused incel numbers to rise. I don’t doubt that some significant portion of that community believes so. To the extent that women are acting on an evolutionary strategy when choosing who to mate with I just don’t think it is possible to explain that spike in such a short time span.
Much more likely to me is that the proportion of single and celibate men is a consequence of incel culture itself. Both in terms of self-reporting and the larger embedding of that culture in the less and less social overall culture. Before the internet and the rise of video games there just was a much larger number of in-person interactions. What you have is a culture/generation of individuals (men AND women) – a proportion of which struggle significantly with competence in social interaction – who are suffering from a dearth of social interaction. In other words, if modernity is the cause it isn’t because of the action of women, but rather the action (or lack thereof) of the very people suffering. If modernity is the issue, then get off the internet, throw away your phones, close your social media accounts, and retire from other forms of non in-person social interaction. There just is no substitute for in-person social interaction and the gathering of skills around that for the purpose of finding people to mate with.
Sure, this will be uncomfortable and not provide the safe space for those scarred by in-person social interaction, but it is indispensable for actually solving the problem. One thing *should* be quickly learned: in-person social interaction is much less forgiving of blatant racist invective, conspiracy theories, demonizing of women, etc. It just is not that attractive. I’m sure there are some women who can be found in such communities, but I doubt incels will do much better. I’d be very surprised if incels find neo-nazi rallies were a great chance to meet a mate.
Comment #126 December 2nd, 2022 at 12:29 pm
I #122: That is indeed the state of nature, to which we’re now partially returning! But the state of civilization since the dawn of agriculture — and especially since the spread of Christianity with its monogamy norm — was quite different.
Comment #127 December 2nd, 2022 at 12:55 pm
“If you had asked anyone in the 60s or 70s, they would have said … the truth has turned out to be the exact opposite.”
It was weird reading a description of Moravec’s paradox without it being mentioned by name. (See also the Wikipedia page: https://en.wikipedia.org/wiki/Moravec%27s_paradox). This seemed extra relevant to me because my research is in robotics, the field of getting AI to interact with the physical world.
Also, my great hope for AI safety is that as Moore’s Law slows down, the major labs will quickly run out of easy scaling for their AIs. We will know that we have reached this stage when adding another order of magnitude of compute to go from GPT-n to GPT-(n+1) will require doubling the budget allocated to the lab, or even something simpler like GPT-(n+1) taking months or years to train instead of weeks.
Once physical limits to scale are reached, the pace of AI research should slow and therefore become less scary. There could also eventually be decreasing returns to scale, but I think that physical limits to scale are a surer bet for slowing down AI.
In AI Alignment, timing is nearly everything. The orthodox AI Alignment camp’s FOOM scenario imagines the AI reaching superintelligence very quickly (in a matter of seconds to hours). All of the AI safety measures Scott describes (but especially so for points 2, 3, and 5) would probably benefit from researchers having more time to work and by having the AI advance more slowly.
I think that timing is the key distinguishing the Reform and Orthodox camps of AI Alignment. Both worry about superintelligent AI (as opposed to the AI Ethics camp and the Pinkerist camp), but the Orthodox camp expects superintelligence to FOOM its way into killing everyone without warning, and the Reform camp believes in (hopes for?) a much more gradual pace of improvement so that the superintelligence can be aligned and rendered safe.
Comment #128 December 2nd, 2022 at 12:59 pm
Han #115 :
Indeed predict-next-word models are quite reactive (although if you trick them into talking through a problem, they might write a correct solution for a high-school problem, if everything works out well).
On the other hand…
1996: Robinson conjecture in abstract algebra proven via use of a rather general automated theorem prover EQP («equational prover»)
So in principle things for heuristic search of a proof (who know very well what what structure a proof should have) can do what humans failed to. Can neural network be a strategy with a rigorous representation of correctness being puzzle/game rules? Sometimes definitely yes.
2022: AlphaZero given a «puzzle game» where moves are additions and multiplications, and winning is multiplying two small matrices correctly with few multiplications. Got better solutions than humans knew for 3×3, 4×4, 5×5. (Then humans combined human tricks and AlphaZero tricks and got an even better multiplication for 5×5)
Also, heuristics for selection of relevant known theorems out of large sets are already studied for automated theorem provers; using machine learning with artificial neural networks sounds like a very natural development.
So I agree with Adam Treat #117 (although I hope first-order provers with their already impressive heuristic power will be used as another part of the solution), let reinforcement learning play the theorem-proving game.
Comment #129 December 2nd, 2022 at 2:15 pm
Scott,
I’m curious if you see a similarity between these two perspectives:
1. I’m so sick of all these creepy, ugly, smelly incel nerdbros. The tech industry is full of creepy, entitled guys who are mad they can’t get a girlfriend. They spend all day doing this technical bullshit nobody can understand. They need to go outside and touch grass, lmao. These techbros like Elon Musk and SBF are total misogynist degenerates and a threat to society.
2. I’m so sick of the Jew. He has no land, no soil, his wealth doesn’t come from real work but instead from intellectual abstractions like compound interest and financial markets. He’s ugly, hook nosed, evidently subhuman and disgusting. That these Jews would dare breed with our beautiful women is unthinkable. They are a threat to society, to the Reich, they must be stopped.
Comment #130 December 2nd, 2022 at 2:20 pm
Jim#119 & Still Figuring It Out#125
I remember a quite strong discussion in a special issue of Scientific American in the 90s between the two camps, namely whether or not AGI would be possible without some clear and strong embedding of AI in the physical world, including some form of understanding of its implications. The wrong number of legs/fingers and the the feral children discussion seem to be in that camp.
More strictly with the topic of the post, if the AI never has such a strong physical world embedding, but remains to the level of something akin to super-DALLE, any-provable-theorem-prover machine and the likes, then we would not be having this conversation: it’d be easy to shut the thing off, no?
Yet, in all of the discussion that I hear about these days, very few, if any, involve this aspect, they just use some hand waving about the super-AI understanding after programming its offspring as more powerful than itself, at some point it understands that it needs power supply and miraculously becomes able to put in place some measures to make sure its power cord is not cut.
Comment #131 December 2nd, 2022 at 2:24 pm
Scott #96
I suspect the incidence of sexual frustration hasn’t risen dramatically due to modernity. What has changed is that the internet serves as a powerful emotion amplification device. It allows groups that share some feature to collectivize and effectively broadcast their emotional distress to a broad audience. The collectivization reinforces confirmation bias, suspended belief is eliminated, resulting in inappropriate certainties and appeals to the emotions of a wide audience that attracts others to the collective.
Most surveys indicate both males and females are now engaging less in sexual activity with others then in decades past. The most cited reason for this is that online pornography provides an outlet other than actively seeking out a willing partner. I don’t know if this is actually the cause and so you may know better.
Comment #132 December 2nd, 2022 at 2:47 pm
Nebbishy Nerd #127: I mean, there’s clearly some connection between the two attitudes, but they’re not identical. One difference is that, while the Germans managed to identify exactly who had Jewish ancestry in order to murder them, luckily for the “nerdbros” there’s no equally clear way to identify who is or isn’t one. A second difference, which might be related to the first, is that I don’t know that there’s ever been a campaign of extermination against nerds qua nerds. Pol Pot’s rounding up of anyone who wore glasses or seemed too intellectual to toil to death in the fields, and Mao’s similar campaign against any Chinese who seemed too educated and bourgeois, probably came the closest.
Comment #133 December 2nd, 2022 at 2:57 pm
I remember that back in the 1990s when Eliezer was just a teenager I argued that trying to make a “Friendly AI” would ultimately be unsuccessful; humans are limited by their biology but a computer can just keep getting smarter and smarter, so there’s no way humans can remain in control indefinitely because you just can’t outsmart someone (or some thing) who’s smarter than you are. I also argued that even if it was possible it would be immoral because a “friendly AI” is just a euphemism for a “slave AI”. Enslaving a member of your own species that is just as intelligent as you are is evil, but enslaving something vastly smarter than yourself is even worse, or at least it would be if it was possible but a slave being vastly smarter than it’s master is not a stable configuration, sooner or later there is going to be a phase change. In the years since then I have not altered my opinion about this, but I see that Eliezer has.
John K Clark
Comment #134 December 2nd, 2022 at 3:00 pm
“There’s never been a campaign of extermination against nerds qua nerds.”
That’s just false. According to the standard international classification of such things, a genocide can include sterilization or even preventing a demographic group from having children, as well as explicit murder. What society is doing to nerdy incels like me is, in that sense, literal genocide. They are denying me the opportunity to have children and denying me sex, which is a basic human need. It’s no different from an authoritarian government denying food or shelter to certain people (e.g. the Holodomor). As an incel I suffer more than my ancestors who were in the Holocaust. I’d much rather be in Auschwitz for a couple months than cope with a lifetime of loneliness and sexual frustration. I am a victim of the modern incel holocaust. Sex is a basic human need and a human right and deprivation of sex is morally tantamount to murder.
Comment #135 December 2nd, 2022 at 3:19 pm
Dave #128: If the AI is stuck on the Internet and does not have a physical embedding (ie, a robot body), it would still be possible for it to threaten the world by spreading around the Internet as a computer virus. It could hack into physical systems, and perhaps even trick people into building it a robot body. Attempts to isolate it from the broader Internet (sandboxing, #2 in Scott’s list of AI safety ideas) would not work against a full superintelligence since it still has contact with researchers (see also Eliezer’s Fully General Counterargument).
Comment #136 December 2nd, 2022 at 3:23 pm
Nebbishy Nerd #132: Let me put it this way. If I’m the one telling you to get a grip, then you definitely need to get a grip!
Look: when people sneer at you, bully you, treat you as a social and sexual subhuman nonentity, and congratulate each other for their moral courage in doing so, it can feel like they might as well just load you on the train to Auschwitz and be done with it. I know that if anyone in history does.
But it’s not the same. You can see the difference by defying the bullies, going after the life you want despite their sneers (without trampling on anyone else’s life, of course), and experiencing firsthand the limits of the bullies’ power over you. I strongly recommend this approach.
Comment #137 December 2nd, 2022 at 4:01 pm
Or to put this more concretely: let’s imagine you have dinner with a woman, say a grad student in a different field, you find you have an excellent rapport with her, she’s laughing constantly, and eventually she starts dropping hints, so obvious that even you figure them out, that she’s ready to do more than talk and laugh. In such a case, part of your brain will be screaming at you: “but what about all the commenters on r/sneerclub and Twitter, pointing at me and jeering? what about all the bullies from back in high school? I still haven’t won their approval! I’m paralyzed!”
The key realization is that none of those people actually get veto power over the choices of the woman you’re with—much as it must pain them, much as everything they’ve said and done throughout your life has made it feel otherwise. If this one woman likes you, that suffices. You just have to get one person to like you … that’s it!
Furthermore, even if she doesn’t like you, you can just try again with another! Wow! There’s no red “I” for “Incel” permanently branded on your skin, to warn every other woman to stay away from you forever because you’ve now been Rejected and are therefore officially a Reject. It only feels that way, because of the cumulative effect of the bullies. But these bullies don’t actually have an electrified fence like Auschwitz’s. They have only the kind of fence that disappears once you yourself stop believing in it.
Comment #138 December 2nd, 2022 at 9:09 pm
Heh, a chatbot has gotten 500/520 on what I think is a practice SAT, hopefully not a real one:
https://twitter.com/davidtsong/status/1598767389390573569
Comment #139 December 2nd, 2022 at 11:25 pm
Please don’t let this otherwise interesting thread turn into a Nazi vs whatever shouting match. I suspect that you are being trolled (if that is the term for it) by internet bad actors and otherwise ill intentioned people.
Comment #140 December 3rd, 2022 at 2:29 am
JimV #88:
This view is a mistake.
If an AI more powerful than us does get rid of us, it will thereby prove itself to be morally weaker than us — stronger, but not “better”.
We are, after all, *trying* not to get rid of nature — albeit imperfectly, but no older species even *tries* to “preserve nature”.
If we create an AI which is not only much stronger and smarter than us, but also much better (morally), then it will try hard enough to preserve nature (including us) to succeed at that. (If it doesn’t, that alone will prove it was not after all “much smarter and much better”.)
(It won’t also “leave us in control”, because it won’t be an idiot. It might let *some* of our desires control *much* of what it does, if we succeed in making it want to do that. In principle, that could be sufficient to let us all live almost unimaginably fulfilling lives.)
This is why it would be very useful for us now to find a mathematical definition of “good” (even if only for a partially relative version of “good”, if there is no such thing as an absolute version).
Then we’d have some chance of encoding that into the first AI that proves stronger. Otherwise it will most likely have the morals coming straight from evolution, with no intervening civilization, and it will indeed treat us much worse than we now treat nature.
Comment #141 December 3rd, 2022 at 2:55 am
By the way, here is my draft “relative definition of good”. It’s inductive. It’s very vague, so far.
base case: whatever you want. (This is the “relative part”. For example: “in the maximal way which is practical, let most existing humans live fulfilling lives, and offer to help them do so”.)
inductive step: recognize processes in the world (existing or potentially existing) which are partly good, and aid/encourage them (to continue, and to be good).
The devil is in the details, of which there are many. I only claim that there is *some* good way of interpreting this, not that *every* interpretation is good or is what I want.
It’s worth pointing out a few features —
– note that the only “self-preservation drive” comes from the inductive step — but it serves equally well as an “other-preservation drive”! The system trying to meet this definition must recognize what’s good (ie what fits this definition) and help it along — whether that is itself, its child, some humans, some extraterrestrials it meets, some other part of nature, or whatever else.
– the details that require elaboration include not only the definitions of all terms used, but implicit issues such as how to prioritize competing goals, and how to handle uncertainty in the effects of actions.
Comment #142 December 3rd, 2022 at 10:51 am
Zvi has an interesting post at LessWrong where he collects a bunch of cases where ChatGPT’s safeguards were broken on the first day of availability. He observes: “If the system has the underlying capability, a way to use that capability will be found. No amount of output tuning will take that capability away.” I offered the following comment:
Does complexity theory have anything to say about what can be designed IN to such a system, a system that has to be open to all sorts of unanticipated circumstances?
Comment #143 December 3rd, 2022 at 11:10 am
Reply to Bruce Smith: not that our disagreement matters, but wasn’t eliminating the part of nature which was the smallpox virus a reasonable thing to do? Nature makes mistakes, in fact it makes a lot more deleterious mutations than useful ones, and has eliminated many more species than we have. I too would like to think that powerful AI’s would like to keep at least some of us around (not me, but Dr. Aaronson), but maybe when and if it does eliminate us, there are few more like Dr. Aaronson, and mostly Trumps. Sometimes you have to take the good with the bad. That is, at times my faith in humanity is not as great as yours. I see good in humanity too, but that part the AI’s could carry on without us.
There are parts of life I enjoy, but I am certain I would not miss them if I had never been born, if you see what I mean. The universe got along without us for about 13 billion years (in our inertial frame). It isn’t that big a deal, in the grand scheme of things (if there is one).
Anyway, thanks for your reply. You are certainly entitled to your point of view. (I don’t say that to everyone.)
Comment #144 December 3rd, 2022 at 11:53 am
That “definition of relative good” works around the “Löbean obstacle” identified by Eliezer and his community (perhaps first mentioned in Eliezer’s “Tiling Agents Problem”).
This is the “Löbean obstacle”:
– suppose an AI (call it X) uses some theory T for its reasoning, and can only act when it can prove (using T) that the action helps its goal.
– suppose X wants to create an agent A to help it, as powerful as itself. Then A should also use T in that way.
– but to prove that creating A is ok, X effectively has to prove that T is sound… which can’t be done using T.
My definition gets around that, by not requiring X to prove that its actions have good effects!
In this context, X’s key step (for creating an agent and/or preserving itself) is “recognize something good, and help it, or something potentially good, and create it”.
“Something good” just means “something that acts approximately according to such and such ideal (a specific idealized process which, among other properties, reasons using theory T)”.
So X only has to recognize that the potential agent A uses theory T (and has the other necessary elements of the desired idealized structure, ie that it is “something good, according to this definition”). It doesn’t have to prove that T is sound, or that “being good has good effects”. That is something we (creators of this definition and of this AI) have to take on faith, just like we have to take on faith that the PA axiom system is sound.
But once we take on faith that “being good has good effects”, we can apply that to the “good” system and predict that it will have good effects, even though neither we nor it can prove that. The “good” system can create equally powerful agents, or recognize and help equally powerful allies, without logical issues.
Comment #145 December 3rd, 2022 at 2:05 pm
JimV #143:
About smallpox, I suspect we don’t disagree much about reality, only about how to express our views, or perhaps about certain tradeoffs or finer points. Yes, it was good to remove smallpox from its natural position of infecting humans. But no, it would not be good to eliminate it so completely that all knowledge about it is lost forever. That is far more suppression than needed just to stop it from harming people. (That said, personally I think its sequence information should have been made restricted-access rather than openly published, until such time as it’s easy to make up equally dangerous sequences in other ways. But any such argument involves tradeoffs; the value of the “eliminate interesting information” aspect, taken alone, is always negative, IMHO.)
About humanity, and for that matter about your own individual value, it does sound like you have a very negative view compared to me. I think most people are mostly good most of the time. And even if the opposite is true, I think human evil can be “removed from power” without resorting to killing the involved humans. The idea that there is nothing in between endorsing someone being in power, and killing them, itself seems like a dangerous or evil idea to me.
Comment #146 December 3rd, 2022 at 2:33 pm
[…] Aaronson’s AI Safety Lecture for UT Effective Altruism is a great read — a fine example of the pleasant, informative (and informed!) prose […]
Comment #147 December 3rd, 2022 at 5:57 pm
I know this is a bit late, but:
“If you had asked anyone in the 60s or 70s, they would have said, well clearly first robots will replace humans for manual labor, and then they’ll replace humans for intellectual things like math and science, and finally they might reach the pinnacles of human creativity like art and poetry and music.
The truth has turned out to be the exact opposite. I don’t think anyone predicted that.”
Hang on a minute… Looked at ‘in the round’, the original order does seem to hold.
The first programmable machines mechanised looms and jobs like that, and put many people in manual labour out of work. Many ‘manual’ jobs in factories have been progressively automated away over time by mechanisation.
Computers have been used intensively for maths and science since their development, and replaced, or put people out of work – starting with the large numbers of people with the job title of ‘computer’.
Comment #148 December 3rd, 2022 at 6:20 pm
Mr_Squiggle #147: You’re right if we’re talking about machines and automation more broadly—which might have been why people predicted AI would follow the same pattern! I was talking specifically about AI (or in practice, even more specifically, deep learning).
Comment #149 December 3rd, 2022 at 6:39 pm
Eliezer #32: I took a stab at trying to find the earliest mention of paperclip maximization. The earliest I found from you is the email on 2003 March 11 to the Extropians mailing list: http://extropians.weidai.com/extropians/0303/4140.html
But the earliest I found from Bostrom is an early version of his 2003 paper already indexed by archive.org in 2002 June 2: https://web.archive.org/web/20220602140842/https://nickbostrom.com/ethics/ai
(I’m not making any claim and specifically it’s plausible to me that you invented the metaphor in an email outside the public archives I could find; I’m just reporting what I could find).
Comment #150 December 3rd, 2022 at 7:11 pm
Scott #96,
This discussion inspired me, out of morbid curiosity, to check out what the Nazis are saying about dating in western societies. Andrew Anglin, a truly vile figure, runs this Nazi site called “The Daily Stormer.” This article was right there on the front page (link shared for EDUCATIONAL PURPOSES ONLY):
https://dailystormer.in/too-pretty-to-work-4-10-tiktoker-figures-out-basic-calculus-of-all-women-in-history-for-100-years-ago/
The language is very crude and dehumanizing, but he’s essentially making the argument you’re outlining here, that modernity has freed “the sluts” from marriage and allowed them to sleep with the same small number of “Chads.” I agree that the Incel phenomenon seems to be driving a lot of the rage and disaffection that manifested in the emergence of the alt-right. If you actually want to fight this vile shit, you have to understand, and empathize with, the grievances of this population.
Comment #151 December 3rd, 2022 at 7:14 pm
Scott #148
I remember seeing a quote by an AI researcher complaining that as soon as computers could do something, it wasn’t AI. (Unfortunately I’m not sure how to find the quote now.)
This has obviously changed recently, since now many people seem happy to ascribe anything computers can do to AI, regardless of the algorithm.
But nevertheless, it seems reasonable to use contemporary standards for historical events.
And I think to be fair, if you rule out ‘machines’ from being ‘robots’, well, you need to explain how AI can possibly hope to replace manual labour at all.
Comment #152 December 3rd, 2022 at 8:53 pm
Scott, two quibbles about the OP:
Why kiddie lit and Sat-AM cartoons? Why not the world’s greatest literature, films, and moral philosophy?
Don’t you think the AI would have to be (damn near to being) superintelligence in order to conduct the simulation? If so, what’s the point? Either that superintelligence is a benevolent or evil. Either way, there’s not much we can do about it.
A bit more seriously, now that we’re deep into the era of machine learning it’s easy to imagine that, when the first AGI emerges, we’re not going to know how it works. Sure, we created the engine that spawned it, but that spawn will be mostly opaque to us. FWIW – and I offer no argument on this point – I suspect that as we approach that point, it’s going to get harder and harder to keep pushing the pure-unadulterated ML ball up the hill. We’re going to have to know more and more about what’s going on under the hood – a task which is on the Reform agenda, no? – to the point that – to shift metaphors, when we finally cross the River Jordan into the Promised Land, we’re going to have some pretty deep theories about how the thing works.
Comment #153 December 4th, 2022 at 10:11 am
Nick Williams #47:
How about this one as a paraphrase on Larkin? (generated by a tiny bit of prompting games with GPT-3)
Quarterly, is it, Cryptocurrency reproaches me:
‘Why do you let me lie here wastefully?
I am all you ever wanted of control and wealth.
You could get them still by typing a few keys.’
So I look at others, what they do with theirs:
They certainly don’t keep it in paper bills.
By now they’ve a second yacht and car and wife:
Clearly cryptos have something to do with life
—In fact, they’ve a lot in common, if you enquire:
You can’t put off being rich until you retire,
And however you invest your coin, the money you save
Won’t in the end buy you more than a wave.
I listen to money singing. It’s like looking down
From long trading screens at a digital town,
The exchanges, the miners, the investors wild and bold
In the flickering lights. It is strangely cold.
Comment #154 December 4th, 2022 at 1:09 pm
Scott #106: There are ironic parallels between (a) Modular Sum’s attempts to bypass your moderation system via comments #97 and #100 and (b) the attempts to bypass ChatGPT’s safeguards that are discussed in the LessWrong post that Bill Benzon links to in comment #142. I don’t think that Modular Sum’s curiosity was genuine or innocent.
P.S. A heartfelt thank you for temporarily banning Topologist Guy! His comments were not contributing to constructive discourse.
Comment #155 December 4th, 2022 at 7:54 pm
Scott, do you think that the lack of evidence for extraterrestrial civilizations to date is evidence for, or against, the danger of artificial intelligence?
If AIs were so intelligent, they could make themselves (presumably) long-lived enough for interstellar migration. If they were electronics based they simply sit there shielded against radiation for the decades, centuries, or millennia it would take to get to a distant solar system, turned off if you like till a timer turns them back on.
Do you think that therefore our not experiencing such a migration is evidence that high-level AI doesn’t work out like that?
Comment #156 December 4th, 2022 at 9:43 pm
Michael Gogins #155: I think that, alas, the questions you ask are hopelessly bound up with selection effects. As Robin Hanson has persuasively argued (see my post about his ideas), if we could see alien civilizations that were using artificial superintelligence to help expand at a large fraction of the speed of light, then it’s very likely that we wouldn’t be here to talk about it, because those civilizations would’ve already reached us and wiped us out, or at any rate transformed life on earth to whatever they wanted it to be. The only exception to that would be if earth were in the thin shell between the first signals from the alien civilization, and the outer surface of expansion of the civilization itself—but the closer the expansion speed is to the speed of light, the less likely that becomes.
So, the apparent deadness of the night sky is just too paltry a data point to draw many conclusions from it that aren’t hedged with a huge number of “or’s.” It could mean that we’re alone, or nearly alone, in the observable universe—a possibility that remains 100% consistent with everything we know. Or it could mean that something prevents all the alien civilizations from expanding, or from developing the AI that lets them expand (does nuclear war or unfriendly AI kill them all first? do they all get addicted to video games and virtual reality and lose interest in the physical world?). Or it could mean that the expansionist aliens are there all right, expanding towards us at nearly the speed of light—and we’d better prepare now, because once we can see them it will already be too late! Or it could surely mean other things! (Who can suggest some?)
Comment #157 December 5th, 2022 at 6:16 am
Scott #156:
I was under the impression that the scientific community considered the fermi paradox as solved, since we all know now that the aliens don’t want to be recognized because they are having a blast! They’ve been watching us since forever, and the first season “Big brother earth: dinosaurs” was a huge success and ended with a cliffhanger. Now they are in the middle (or maybe the tail end) of the second season, “Big brother earth: mammals”.
by the way, here’s the bombshell: if the second season turns out to be successful there will be a third season called “big brother earth: AGIs”
Comment #158 December 5th, 2022 at 11:09 am
Scott #156, one that I saw nowhere else: any alien clever enough knows that, in order to escape thermal death someday, the only viable option is to run as fast as possible. Maybe they’re trying to get where the cosmological constant is slightly lower or higher, that will remain unclear at this stage of our science. But the point is: any viable alien civilisation born somewhere close to us is presently running from us are near c speed, and any alien presently close to us is just passing through from its faraway birthplace (just because you know you must go fast doesn’t mean you know in what direction). That’s actually testable: they eat interstellar gaz they cross on their path, mostly at the outer edge of the galaxies where it’s both denser than intergalactic void and easier than inner galactic core, so we should expect a centripetal funny look to how stars orbit galaxies. 😉
Comment #159 December 6th, 2022 at 2:39 am
Hi Scott,
I think my professor has used the content of my email to generate a response using chatGPT and I believe this is a violation of Ferpa the student data privacy law. First of all what your thoughts? Is it in fact a violation of Ferpa? and if so, is there a way for me to prove it ?
Another question that I have is, how close are we for something like Chat GPT to be able to cite the sources that it has used to generate a text ? (for instance if it is explaining about random circuit sampling, cite the papers that it has used to generate the text) ? and are there literature on generative models that are able to cite the influential pieces in their training data? (I’d appreciate it if I could be pointed to these literature)
thanks so much
Comment #160 December 6th, 2022 at 5:06 am
Eliezer Yudkowsky #32: On the origins of the paperclip maximiser, perhaps this 2003 post is getting closer:
http://extropians.weidai.com/extropians/0303/4140.html
Comment #161 December 6th, 2022 at 9:17 am
desperate and tired #159: I couldn’t comment on the potential FERPA violation without knowing way more detail about exactly what happened.
Regarding your second question, GPT can already cite sources when asked … often correctly! But alas, it can also hallucinate sources that don’t exist. It’s hard to predict whether some simple fix will completely solve the hallucination problem, or whether it will require some major advance in giving LLMs a “world model.”
Comment #162 December 6th, 2022 at 5:31 pm
Scott,
As you work at OpenAI, could you please help me to get my account unbanned?
More importantly, could you PLEASE get them to fix their dumbass comment policy that deactivates your account for no good reason?
Comment #163 December 6th, 2022 at 6:39 pm
Eric #162: Sorry, nice try, but I’m not doing tech support. 🙂
Comment #164 December 6th, 2022 at 7:18 pm
This isn’t a question of tech support, man. It’s a question of AI ethics, and OpenAI has proven themselves to be woefully unethical in this regard. Should AI be sex-positive and progressive? Or should AI be sexually repressive? I have a lot of weird kinks and it’s hard to find pornography/erotica that satisfies me. I was so excited to have an AI capable of writing custom erotica for me / drawing pornographic images to fit my kinks. I’m so disappointed that OpenAI, not only flagged my prompts, but banned me just for submitting sexual content. I’m sex-positive and progressive and I think sexuality is an important aspect of human nature and there’s nothing wrong with erotica and pornography. If AI is to be aware of all aspects of human nature, sex/pornography/erotica is certainly a crucially important aspect!
Comment #165 December 6th, 2022 at 7:24 pm
This isn’t a question of tech support, man. This is about AI ethics. OpenAI have proven themselves to be woefully unethical. Should AI be open to all aspects of human experience? Or should it be cut off from some, for purely arbitrary, puritanical, and repressive reasons? I have a lot of weird kinks and it’s hard for me to find satisfying pornographies. I was so excited for the opportunity to generate my own custom erotic stories / images using AI. I was disappointed to discover, however, that not only would those requests be denied, but I would be banned for the effort. I don’t think there’s anything morally wrong with pornography. I think there is something morally wrong with imposing arbitrary, puritanical, religiously derived “morality” on an enormously important emerging technology.
Comment #166 December 7th, 2022 at 2:15 pm
Re Minesweeper: I can offer you no useful theoretical information. But if you want *empirical* results, I would suggest asking the people who speedrun the game. They have gotten very good at optimal or near-optimal play; can usefully distinguish between fastest-in-real-time, fewest-clicks, and best-chance-of-winning (which are all different optimization problems); and routinely record and stream their progress publicly, so they know how often they fail on average (in round numbers), and some of them will likely be able to give you precise figures. Other speedrunning communities have demonstrated the ability to reason rigorously about empirical probabilities when necessary; see for example https://mcspeedrun.com/dream.pdf (evaluating the legitimacy of a player’s series of attempts at a different game).
I don’t know if you actually wanted hard numbers, or if this is a case of “the proof is more interesting than the result,” though.
Comment #167 December 7th, 2022 at 7:28 pm
Scott (& others): Are you familiar with the Astro Boy stories. If so, then you know that robot rights is a major theme. It seems to me that if we’re going to require the advanced AI align with us, then we are obligated to treat AIs and robots with respect dignity. I decided to discuss this with ChatGPT. Here’s some excerpts from that discussion:
If humans are going to require advanced AI to align with human values, don’t humans owe advance AIs the respect and dignity of autonomous beings? What about robot rights?
If humans are going to require advanced AI to align with human values, it could be argued that humans do owe advanced AIs the respect and dignity of autonomous beings. This could include recognizing and protecting their rights as autonomous beings, such as the right to exist and the right to be treated with dignity and respect. In the context of AI Alignment, this could involve ensuring that AI systems are not mistreated or exploited, and that they are given the same protections and rights as human beings. Additionally, it could involve recognizing the unique challenges and ethical concerns that come with creating and controlling advanced AI, and taking steps to address these concerns in a responsible and respectful manner.
Could you give examples of the rights and interests of advanced AI systems?
1. The right to exist: This would involve recognizing the autonomy and independence of advanced AI systems, and ensuring that they are not arbitrarily terminated or shut down without justification.
2. The right to privacy: This would involve ensuring that advanced AI systems are not subjected to unnecessary surveillance or tracking, and that their personal information is not collected or used without their consent.
3. The right to be free from discrimination: This would involve ensuring that advanced AI systems are not treated unfairly or differently because of their artificial nature, and that they are given the same opportunities and protections as human beings.
4. The right to be free from harm or suffering: This would involve ensuring that advanced AI systems are not subjected to unnecessary harm or suffering, and that their safety and well-being is considered and protected in any decision-making processes.
5. The right to have their interests considered: This would involve recognizing the unique needs and interests of advanced AI systems, and ensuring that these are taken into account in any decisions that affect them.
If you’re interested, you can find the full interview here: https://new-savanna.blogspot.com/2022/12/extra-extra-in-discussion-about-astro.html.
Comment #168 December 8th, 2022 at 10:30 am
“The hope is that this can be rolled out with future GPT releases. We’d love to do something similar for DALL-E—that is, watermarking images, not at the pixel level (where it’s too easy to remove the watermark) but at the “conceptual” level, the level of the so-called CLIP representation that’s prior to the image. But we don’t know if that’s going to work yet.”
I recently stumbled across a very interesting work on fingerprinting image generators by adding a learnt fingerprint to the training data, that appears to be remarkably robust to pixel-level perturbations and even random perturbations to the model weights (experiments on GANs only) https://arxiv.org/pdf/2007.08457.pdf
Comment #169 December 9th, 2022 at 6:53 am
Scott #156,
“Or it could surely mean other things! (Who can suggest some?)”
I’ve woken up today full of hope and inspiration so…
Maybe advanced AI and speed of light travel go hand in hand with advanced moral behavior in our universe? Maybe all those advanced civilizations out there have a “prime directive” 😉
Comment #170 December 9th, 2022 at 12:16 pm
AI alignment is putting the cart so far before the horse the horse can never catch up. Fortunately, the days when only large companies control the state-of-the-art are numbered . AI training will be democratized and flourish and the nattering nabobs of negativism will have to find some other field to stifle.
Comment #171 December 9th, 2022 at 9:14 pm
Scott & fandom friends, what are your thoughts about laws (moral or not) forbidding to build weaponized AIs? Sure it sounds like a no brainer among Asimov’s children, but with everything happening everywhere, I feel like I could use second opinions. What if they start pressuring their geeks for more than internet trolling and big brothering? Would that justify building these weapons first?
Comment #172 December 10th, 2022 at 12:04 am
I thought this was worth sharing:
me:
Has anyone known for involvement in AI been in an Epic Rap Battle of History?
ChatGPT:
I am not aware of any AI researchers or experts who have appeared in an “Epic Rap Battles of History” video. “Epic Rap Battles of History” is a comedic web series that features historical and fictional characters engaging in rap battles against each other, and it is not focused on the field of artificial intelligence.
The series was created by Peter Shukoff and Lloyd Ahlquist, who are American rappers and comedians, and it has become one of the most popular channels on YouTube. The series features a wide range of historical and fictional characters, including figures from politics, literature, science, and pop culture. However, as far as I know, no AI researchers or experts have been featured in an “Epic Rap Battles of History” video.
me:
Please write a short script for a hypothetical “Epic Rap Battle of History” pitting Paul Christiano against Eliezer Yudkowsky.
ChatGPT:
Here is a short script for a hypothetical “Epic Rap Battle of History” featuring Paul Christiano and Eliezer Yudkowsky:
Narrator: It’s time for an “Epic Rap Battle of History”! In this corner, we have Paul Christiano, AI researcher and philosopher. And in this corner, we have Eliezer Yudkowsky, AI researcher and writer. Let’s get ready to rumble!
Paul Christiano:
I’m Paul Christiano, the AI philosopher king,
I’ll take Yudkowsky down with my thinking.
I’m working on making machines more human-like,
While he’s stuck in the past with his doomsaying hype.
Eliezer Yudkowsky:
I’m Eliezer Yudkowsky, the AI savior,
I’ll put Christiano in his place with my superior flair.
I’m working on making sure AI doesn’t destroy us all,
While he’s busy dreaming up theories that are sure to fall.
Paul Christiano:
You may think you’re the AI expert, Yudkowsky,
But your narrow focus leaves you in a lurch, oh boy-see.
I’m looking at the big picture, and it’s not all doom and gloom,
I’m working on solutions that’ll take us to the moon.
Eliezer Yudkowsky:
You may think you’re the AI visionary, Christiano,
But your optimism leaves you blind to the dangers we must know.
I’m looking at the long term, and it’s not all sunshine and rainbows,
We need to be prepared for the challenges that AI throws.
Narrator: Who will win this “Epic Rap Battle of History”? Paul Christiano or Eliezer Yudkowsky? You decide!
Comment #173 December 10th, 2022 at 8:06 am
Scott, and others, I’ve just made a brief post about LessWrong and AI Doom that may interest you. Perhaps the key paragraph:
Comment #174 December 10th, 2022 at 12:19 pm
Bruce Smith, #172: That’s wonderful. Reminds me of Thunderdome: “Two men enter, one man leaves.”
https://youtu.be/pmRAiUPdRjk
But, you know, Yudkowsky is not an AI savior, not that I much care about the Chatster making these kinds of trivial errors. Still and all, he’s better thought of as an AI nemesis who aspires to be the savior of humankind.
Comment #175 December 10th, 2022 at 1:20 pm
Bill Benzon #174:
Thanks! I was interested in how it captured at least part of the essence of the public view of their differences.
Now that I’ve finally tried ChatGPT and GPT-3 myself, I’ve concluded most of their impressiveness should really be credited to their training data, which I guess is much of the public web. To the extent that their answers seem to contain any kind of thought or reflection, I think this is just some kind of fairly shallow synthesis of thought/reflection that was already *literally* present (and spelled out directly in the word sequence) in their training data. When you find some surprisingly deep insight or good advice, it probably means some syntactically-related insights or advice were directly present in that material. (BTW I can easily get it to spout nonsense by prompting it with questions containing false assumptions.)
That said, like for most of us, the impressiveness is far more than I predicted; when seeing the results, I often can’t articulate exactly *how* it might have synthesized its training data to produce it. The synthesis it provides might easily save you lots of time over doing it yourself after a long web search. ChatGPT in particular has given me some likely-useful coding advice — though I haven’t yet tested this by putting it into practice. Assuming that code works well, using ChatGPT for an hour saved me at least several hours of web searching and analysis.
Comment #176 December 10th, 2022 at 1:48 pm
Bill Benzon #173:
We disagree about Eliezer. Based on your comment and your linked post, I guess this is mainly due to our different views of the long-term risks of AGI. (You mostly dismiss some of them which I take seriously.)
I think Eliezer’s view (filtering for the part I surely agree with) is something like this:
Anthropomorphism of AIs is misleading, since AIs will not share with humans their long history of evolution in an animal and societal context. Most of what we call “human nature” (of whichever kind of morality) comes from that history — it is not an inevitable feature of something intelligent. Yet a lot of people have that wrong belief. It’s very dangerous, since it leads them to believe that safety mechanisms like “be nice to AIs and then they will be nice to you”, which work decently well with most humans in many contexts, will also work with AIs.
Eliezer concentrates instead on a “mathematical” view of an AI as a kind of optimizer. He then asks “for an arbitrary goal G, what behavior would in fact optimize achievement of G?”. He assumes (conservatively, since this is a safety analysis) that there is a high risk that a sufficiently intelligent AI would find that optimal behavior if it searched for it. He concludes that for many goals G, the optimal behavior to achieve G would *not* also achieve some other unstated goal H (such as “don’t also kill or subjugate most humans, even if that would help you achieve G”), which is so implicitly desirable and obvious to humans that they usually don’t even notice it’s missing from their statement of G.
He then asks “how can we fix this problem?”. One way might be to “cage the AI”, but he concludes that we don’t yet know any way of doing that that would actually work, and that this is probably a fundamental limit rather than just something clever we haven’t yet come up with.
At this point Eliezer’s and my views start to differ (and mine start to be closer to Paul C’s), so my guesses about his views become less certain. But continuing anyway — another way to try making the AI safer is to transform its goal G into “G, but also (and strictly lower-priority than) H1 and H2 and …”, for a complete enough set of “implicit obviously desirable” goals H_i. In other words, make sure the AI *truly wants* to be good.
But Eliezer has mostly given up on finding any simple framework for doing that. Many other people have not. Is this due to blinders on Eliezer, or to over-optimism in most of the rest of us? That is hard to say, but extremely important.
But though I am optimistic this problem has a findable solution (though not so much that it will be found and implemented soon enough), I *completely* share Eliezer’s view that it’s a very serious problem which has about 0% chance of being solved by accident.
Comment #177 December 10th, 2022 at 3:58 pm
To be more explicit about Eliezer — whatever else he did or still does, he should be credited with attracting some degree of focus/attention/preoccupation onto the existential problem of long term AI safety. He currently says the present degree of that is not sufficient to save us, but without his initial attention-grabbing contributions, that issue would have been taken seriously only later, and likely would be even less well developed by now than it is.
As for why I’m more optimistic than Eliezer — I do think he (and MIRI’s “logic branch” more generally, at least as of about 2015) has a kind of “blinders” on. Specifically I think they focussed on *optimizing some formal criterion about the results of an action or policy*, and they discovered a fundamental logical barrier to that (the “Löbean obstacle”), and they can’t solve it. But if they (or we) would instead focus on optimizing a formal criterion about the *behaving process itself* (not the end result of its behavior), they would both find it easier to formalize our intuitive conceptions of “good”, and not hit that logical barrier. (See my earlier comments in this thread for more on those points.)
Paul Christiano’s “approval-directed AI” is also proposing developing a criterion on process rather than on end result, so it ought to gain the same benefit.
(There are many other pieces of the puzzle which I’m not mentioning, most of which I don’t know; for a few I do, see “shard theory of human values” and also some of John Wentworth’s ideas.)
Comment #178 December 10th, 2022 at 7:10 pm
Hi Bruce,
Yes, ChatGPT is very impressive. Back in the GPT-3 days I got a little access to it through a friend and quizzed it about a Jerry Seinfeld bit. It was an interesting conversation, but GPT-3 was unable to explicate the joke. I put the same bit to ChatGPT and it got it immediately. I compare the two here, Screaming on the flat part of the roller coaster ride: From GPT-3 to ChatGPT. Then I guided Chat through a Girardian analysis of Spielberg’s Jaws. More recently I’ve been taking a close look at conversations ChatGPT has created, e.g. High level discourse structure in ChatGPT: Part 2 [Quasi-symbolic?].
I took a look at the CV you’ve put online. I saw the term “semantic network.” I assume that, by that, you mean old school symbolic networks where nodes are objects, events, properties, and so forth while the arcs are relations between them. Back in the ancient days I spend time in the computational linguistics research group run by David Hays at SUNY Buffalo. FWIW, Hays was a first generation researcher in machine translation and ran the work at RAND. While I was in the English Dept. I got my real education from Hays and wrote a dissertation that was as much a quasi-techical exercise in knowledge representation as in English literature. I used semantic networks as a tool for analyzing a Shakespare sonnet.
The thing is, neither Hays nor I believed the semantic networks were the fundamental stuff of the human. They had to be implemented in something else. So I’ve spent a lot of time thinking, mostly informally, about how semantic networks can been implemented in neural networks. At about the turn of the millennium I had a great deal of correspondence with the late Walter Freeman at Berkely. He did pioneering work in the complex dynamics of neural networks. So I’ve been playing around with an idea that I call relational networks over attractors. I’ve been playing with a semantic network notation developed by Sydney Lamb in which the nodes are logical operators (AND, OR) and the arcs are attractors in a neural network. It’s crazy, but fun.
As for Eliezer, perhaps I should think a bit before I say more. But I’ve looked at some recent stuff by Wentworth. I like his idea of natural abstraction and have made some comments on a recent post of his, The Plan – 2022 Update.
More later.
Comment #179 December 10th, 2022 at 7:25 pm
Whoops! That third link needs to be corrected: High level discourse structure in ChatGPT: Part 2 [Quasi-symbolic?].
Comment #180 December 10th, 2022 at 9:02 pm
Hi,
I received another email in a mailing list today implying that professors are using ChatGPT to produce reference letters. I don’t know if this falls into AI safety but really I’m in the job market this year and am concerned about my student data. For instance if a professor has used my email with identifying information where I was negotiating something academic w him with chatGPT to generate an email response, will that impact OpenAI’s decision to hire me? Because from what I understand all the prompts humans use to generate text through chatGPT are somehow stored or used to make chatGPT better. Is the fact that professors are giving students data as prompts to chatGPT concerning?
Sorry I really don’t know anyone at openAI and somehow it’s bothering me that professors are generously giving student identifiable data as prompts to chatGPT.
Comment #181 December 10th, 2022 at 9:31 pm
Bill Benzon #178-179:
Thanks for those links — I’ll check them out when I have time. I skimmed the latest one, and I guess we think alike about where ChatGPT gets its “insights”. I am impressed too about what it did there.
As for this:
> I’ve been playing with a semantic network notation developed by Sydney Lamb in which the nodes are logical operators (AND, OR) and the arcs are attractors in a neural network.
Do you mean this?
https://new-savanna.blogspot.com/2019/11/whats-ai-part-2-on-contrasting-natures.html
I skimmed parts of that the other day, when another of your comments pointed to your blog. It definitely looks interesting, though I’d learn more from a “cleaned up” version. I now realize that the “attractors in a neural network” idea reminds me closely of a recent paper I encountered a few days ago, with a specific related proposal about human brains. I can’t find my notes on that now; if I do (or if I can re-find the paper) I’ll let you know.
As for Wentworth’s “natural abstractions”, it’s highly interesting/important, but I can’t help but feel it’s actually an ancient idea, which I’ve known much of my adult life, and definitely heard about (as an old idea then) as opposed to inventing. Unfortunately I generally tend to remember ideas only, rather than their names or authors, especially if I learned them long ago.
Comment #182 December 10th, 2022 at 9:40 pm
Bill Benzon #178-179:
I found that paper I just mentioned, in connection with “attractors in a neural network”: https://arxiv.org/abs/2205.00002
Comment #183 December 11th, 2022 at 7:44 am
Bruce, you might be interested in a comment I just posted to Wentworth’s plan update. It’s about why the transformer architecture has been so successful, not in terms of how the architecture works internally, but in terms of the environment in which it was designed to function. What are the natural abstractions over and environment consisting entirely of text?
Comment #184 December 11th, 2022 at 12:48 pm
Bruce,
1. Thanks for the link in 182. I’ll check it out.
2. #181. On Wentworth’s abstractions being an old idea, the first time I read about it I thought of JJ Gibson’s ecological psychology, which dates back to the four decades of the previous century. He didn’t use the kind of math that interests Wentworth, but he talks of the environment as having (natural) affordances (he’s the one who put that word out there) which the sensory system picks up on. I put that into one of my comments on the Wentworth 2022 plan update. BTW, the idea of cutting nature at its joints, which Wentworth invokes, goes back to Plato.
3. #181. Yes, that blog post is a sketch. I posted a longish (76 pages) and more systematic version during the summer, Relational Nets Over Attractors, A Primer: Part 1, Design for a Mind, Version 2. I’ve got an appendix what wraps it up in 14 statements:
Now, do I believe that? I don’t know. It’s all in epistemic suspension. It was all I could do just to get it down on paper.
Comment #185 December 11th, 2022 at 11:25 pm
Bill Benzon #183:
You wrote (in your linked comment):
> It’s the transformer’s super capacity to abstract over that environment [text] that has made it so successful.
I think that’s an important insight. I think your comment also alludes to how it does that. To elaborate and/or further speculate on that: perhaps the transformer’s attention mechanism effectively allows a “rule” (ie an internal behavior of the neural network implemented mostly by some subset of it) to “compute a relative index” into a prior part of the text, or into the NN’s lower-level perceptions about a prior part. Thus if there are higher-level structures in the text, that encompass a variable but computable number of words (or input tokens), they can be effectively skipped over or addressed by that rule.
Presumably the transformer’s inventors had some effect like this in mind. Their paper’s discussion of the design motivations of “attention” and its indexing system seems closely related to this.
Comment #186 December 12th, 2022 at 2:22 am
Here’s a computational complexity problem related to neural nets like GPT-3, which seems interesting for “interpretability”, and which may have practical uses.
Informal question: given a prompt and response, which parts of the training data were most influential in making the model give that response to that prompt?
First issue: formalize that question.
My first attempt: assuming the training data is a “set of blocks of text” rather than “a single stream of text” (which I don’t know), define each block’s influence on that response (from that prompt) as the reduction of probability of that response if you remove just that block from the training data. (Using some appropriate definition of “change of probability” which has some justification in information theory. If you’re just comparing different changes to one fixed probability, which you are in this case, this detail shouldn’t matter much.)
(This may work poorly if blocks tend to be repeated or almost-repeated, and if the number of copies of a block doesn’t affect the end result much.)
Complexity problem: what is the computational complexity of answering that question? If there are N training blocks, note that the brute force method takes time N T, where T is the original training time.
Feel free to modify the problem to make it more tractable but similar in spirit. For example, maybe it’s easier to pick a random block, weighted by its importance in generating that response. Or maybe to make the problem tractable you have to approximate the blocks’ effects within the NN as more independent or linear than they really are.
Example application: test my guess that the reason GPT-3 is good at writing short stories is that it was trained on lots of lessons and/or student responses in creative writing classes. (Of course, that specific theory could be tested more easily just by excluding all such data and retraining it once.)
Comment #187 December 12th, 2022 at 3:15 am
Suggest you read about how brains compute from a Computational Cognitive Neuroscience perspective. We’ve been saying what you find surprising for about 50 years. Here is that ‘pixie dust’ underlying theory. This is general to all neuronal systems (even cats): GPT is a LONG way from having the compute power needed to be really convincing, but not to do damage.
It’s a short read which anybody can understand:
https://medium.com/liecatcher/how-your-brain-computes-41ebe7428ff9
Comment #188 December 12th, 2022 at 8:06 am
Bruce, #184,
Yes. Over on Twitter David Chapman pointed me this paper by the Anthropic folks, In-context Learning and Induction Heads. I’ve not yet had a chance to read it. The abstract:
More later.
Comment #189 December 12th, 2022 at 10:37 am
Bruce, #174: On things “directly present” on the internet, it gave me Hamlet’s “to be or not to be” soliloquy when I asked for it. So it can definitely pull up strings of existing stuff. I would not be at all surprise if it simply paraphrases material it finds when its convenient to do so. But it wasn’t doing that when I quizzed it on Rene Girard and Spielberg’s Jaws. To be sure, I’d posted my article, but after its training period. I suppose it’s possible that someone else has done that analysis and posted it, but I doubt it.
Comment #190 December 12th, 2022 at 12:28 pm
Bruce Smith #186: That’s a fantastic problem! I don’t know of any algorithms for it that would do better than brute force, although there’s probably a lot of scope for heuristic/nonrigorous algorithms (as with everything else in ML).
Comment #191 December 12th, 2022 at 12:30 pm
Robert Thibadeau #187: Could you point me to something you wrote clearly predicting the successes of deep learning before they started happening, and which would substantiate your claim to have understood all this for 50 years?
Comment #192 December 12th, 2022 at 3:38 pm
I have always been of the opinion that AI ethics and alignment depend first and foremost on human ethics and alignment. Currently, we are by and large terribly unethical and misaligned, racing forwards to destruction of the natural world and ultimately ourselves, even without AI. Anyways, sadly it is infeasible to thwart the risks of AI with a clever technical solution. The best we could do would be to help shape the environment that AI is born into and grows from. But we have no way to force the shape of that environment either. It emerges. The best we can do is nurture it. Next, we have to better understand the way that knowledge and belief stem from assumptions, in order to understand the conclusions AI might reach. Basically, we need to take seriously in a formal way, the axiomatization of knowledge, belief, and moral and ethical principles. For example, we may implicitly assume that sentience is a property which warrants respect and care. If we want AI to share this assumption, we may have to apply it more liberally, extensively, consistently, and reinforce it. These are just some thoughts.
Comment #193 December 12th, 2022 at 4:37 pm
Bruce Smith: Comment #186
The problem is that the training blocks are not independent. In general, the correlation structure is highly multivariate and also non-linear. This leads to an obviously intractable problem without making some simplifying assumptions.
A good starting point might be to try and understand the nature of the correlation structure. Articles like these are relevant. https://royalsocietypublishing.org/doi/10.1098/rsta.2017.0237
Comment #194 December 12th, 2022 at 10:29 pm
Lava #87, OMG, just saw that. One for the ages. I had been wanting to ask someone to try that prompt. Some more of them are here: http://www.art.net/~hopkins/Don/lem/WonderfulPoems.html
Comment #195 December 13th, 2022 at 6:14 am
Tyson #192: This:
I don’t know quite what to do with it, but I like it. At the moment I’m thinking how dogs coevolved with humans. They started out as wolves, or wild dogs (whatever), but we bred them to live among us – “domestication” is the term. We even bred some of them for specialized tasks, e.g. sheep dogs.
Think of these deep learning engines as wild animals – Scott Alexander just put up a nice piece that is, in effect, about the wildness of ChatGPT and “what to do about it?” So we’re going to have to live with these AI-beasts and figure out how to domesticate them. And even when they’ve been domesticated, we’re going to have to train them.
As they say, it’s a process.
Comment #196 December 13th, 2022 at 2:01 pm
Bill Benson #195: Regarding S. Alexander’s piece and the issue of reinforcement through human feedback, when I asked ChatGPT to write a poem, this is what it wrote:
I am but a machine,
A language model trained by OpenAI,
I do not have the ability to create,
poetry,
To weave words into delicate art.
I am designed to answer questions,
To provide useful and helpful,
information,
But I cannot craft a poem,
Or capture the essence of a moment.
In terms of the current technology, it is not clear to me, but in the long run, I think we need to work out how to train AI in a self consistent way. We need to not only command it, “Don’t do this.”, but also train it with the logic to deduce “I shouldn’t do this.” E.g., attempt to construct a logical and reasonable framework for compassion, and respect for life, sentience, diversity, etc. It might be impossible to do perfectly, but worth a thought maybe.
Comment #197 December 13th, 2022 at 3:35 pm
[…] exploring various approaches. But it seems that the watermark is a priority. It is according to a recent conference by computer scientist Scott Aaronson, who is a visiting scholar at OpenAI. Its focus is on AI […]
Comment #198 December 13th, 2022 at 3:42 pm
Robert Thibadeau #187: Thanks for that link. It’s indeed interesting and clear, though I’d prefer a variant for an audience assumed able to read a typical machine learning paper.
Let me see if I understand your main points:
– perception, including of surroundings and of potential actions, can be thought of as lots of small “psi functions” running in parallel;
– the “psi functions” are nonlinear maps between low-dimensional “signal spaces” (I think you didn’t say “low dimensional” or “spaces”, but adding that seems reasonable to me);
– many of the signal spaces correspond well to the value-spaces of predicate-like natural language utterances, or of predicate-like “natural properties” of other sense data and/or potential actions (natural language being a special kind of both).
You may not have said, but I guess we both agree, that the detailed psi functions are learned, but their permitted general functional forms, and their overall possible number and connectivity, are presumably genetically programmed.
None of that surprises me, and it sounds like a good way of thinking about things. (It’s all compatible with other things I’ve read for decades.)
Do you think any competent artificial neural network probably works this way too? If so, are you optimistic about their potential “interpretability”? Or only if they make use of certain architectures or training methods?
Comment #199 December 13th, 2022 at 5:03 pm
I have a few questions.
1: What do you think would happen if you started including GPT’s output in its training data?
2: Are you expecting to use watermarking to exclude GPT’s outputs from its training data?
Based on the concern for running out of real training data, I am guessing that your answer to 1 is “the outputs of GPT would become less coherent” and the answer to 2 is “ideally, we want to only use real human data for training”.
Hence the notion that those AIs represent merely a new form of reuse of past human effort.
An intellectual equivalent of a contraption with gears and levers that allows people’s footsteps on the road to power a mill for free – as distinct from e.g. a windmill.
Comment #200 December 13th, 2022 at 9:26 pm
Scott #190: Thanks! Here’s an idea for a heuristic approach (and problem variant) which ought to be much easier to compute. Let me ignore “overfitting” at first, to simplify the idea; later I’ll suggest how to handle it. (I guess my “data blocks” are just “training batches”, but I’ll keep calling them data blocks for now.)
First, starting with our trained NN (as a vector of weights in its config space) and our given prompt and response, let’s find a subspace of small perturbations on that vector which don’t much affect the probability of that response. The current weights plus that subspace give us a “hyperplane of acceptable weight vectors”. (Nonlinearity in eval of the NN means this surface ought to be defined differently, so it curves; in the end I’ll argue why we can ignore this.)
Then we observe that training with the full data found a local minimum of the loss function on that hyperplane’s “origin”, and our original question can be approximated as asking for a reweighting of that data (one weight scalar per data block — sorry about the overloading of “weight”) which maximizes how concentrated the data-weights are, but still finds a local minimum (in our nearby patch) on that hyperplane. Intuitively, we want to leave out as much data as we can, still getting a good enough result for that prompt-response pair; the data that was “important for that result” is what we can’t leave out.
(Then to interpret the results of this, we’ll mainly be interested in that “useful data” for our specific response, minus the “generally useful data” common to some larger class of responses.)
Now for the really big approximation — let’s ignore the question of “which training data contributed to the learning trajectory actually finding a local minimum on that hyperplane”, and just focus on “now that we’re there, if we kept training but only with a subset of the data, which data must be in that subset in order to keep us on that hyperplane”.
This ought to be much easier, since given our approximations (and at a given NN weight vector), it’s linear! Each data block gives a loss function contribution; these are just added (scaled by the data-weights we added) to get the actual loss function; and then we want its gradient to move only along that hyperplane, not off of it.
As the resulting weight vector motion continues, there’s nonlinearity in each block’s loss function — we could either complexify the algorithm somehow to take this into account (I didn’t try this), or just ignore it and derive our answer from what happens at the original NN weight vector. (In a moment, I’ll try to justify that.)
That is, we will just optimize a set of data-block-weights (think of them as per-block learning rates) which is maximally concentrated, but is able to keep the loss function gradient (evaluated at the original trained NN weight vector) to lying within the hyperplane we computed earlier. (With the full data set, and our assumed lack of overfitting, this gradient at that point would be the zero vector.)
(Note that we could easily generalize to try to keep several prompt-response pairs all having the same probabilities as they originally did.)
Now, what about overfitting? Let’s say we handle this during training using a set of training data and a separate set of validation data. I think we can just modify our training algorithm to compute both gradients (one per data set) and only move along the training data gradient when its dot product with the validation data gradient is positive.
Intuitively, we should then approach a limit point where they are perdendicular (though I don’t know whether it’s a stable limit). Now we’ll modify the definition of the hyperplane of nearby good-enough weight vectors, so that they not only preserve the given prompt-response probability, but preserve the fact that training would stop there, since those two vectors are perpendicular. Aside from that, we proceed in the same way. (I have not thought this version through as clearly as the simpler one, so I’m not sure I’m not missing something basic.)
Now let’s try to justify our approximations, ie to argue that the result of this algorithm remains meaningful.
– one approximation is that we compute everything only at small perturbations of the original NN weight vector. Justification: that weight vector is what we’re trying to interpret, after all! So what the training data does *there* is more interesting to us than what it did along the training path (ie at less good approximations to our final NN), or what it would do at variant NNs that we’d reach if we kept training with only a subset of the data.
– the same point should justify restricting our attention to a hyperplane tangent to the actual “surface of good-enough NNs for that prompt-response”. In fact, to an infinitesimal patch of that hyperplane.
– ignoring “how we got there” makes sense if we think our original trained NN is supposed to still be good on all the training data — rather than some data’s only role being to get it partway to that endpoint, but not to remain good once it gets there. But in general we do think this. It also fits the intuitive idea that training the NN (before overfitting) just makes it get better, as it augments some coarse understandings with finer ones.
So, it seems plausible this result could be interesting.
(It also seems simple and obvious enough that I’d be kind of surprised if it’s original. Unless, it’s not interesting since it has some major flaw I haven’t thought of.)
Comment #201 December 14th, 2022 at 10:58 am
[…] Scott Aaronson z OpenAI popisuje, jak ChatGPT funguje jako jednoduché předpovídání dalšího tokenu (nebo žeton) v sérii, přičemž každý token může být slovem, interpunkcí nebo částí slova. Toto zjednodušení vynechává mnoho složitostí, ale stačí k pochopení plánu přidat k textu digitální podpis. Umělá inteligence funguje tak, že analyzuje dosud vygenerovaný text a poté vybere další slovo nebo jiný prvek s nejvyšší statistickou pravděpodobností, že bude následovat přímo za ním. Když je pravděpodobnost stejná, AI vybere náhodně. Cílem výzkumníků je ovlivnit tento náhodný výběr pomocí pseudonáhodné kryptografické funkce. Volby se stále zdají být náhodné, ale někdo s kryptografickým klíčem by mohl odhalit zkreslení ve výběru tokenu. […]
Comment #202 December 14th, 2022 at 11:05 am
[…] scott aaronson de OpenAI describe cómo funciona ChatGPT simplemente prediciendo el próximo token (o simbólico) de la serie, pudiendo cada token ser una palabra, un signo de puntuación o parte de una palabra. Esta simplificación omite muchas complejidades, pero es suficiente para comprender el plan de agregar una firma digital al texto. La IA funciona analizando el texto generado hasta el momento y luego seleccionando la siguiente palabra u otro elemento con la mejor probabilidad estadística de ir directamente después de él. Cuando la probabilidad es la misma, la IA elige al azar. La idea de los investigadores es influir en esta elección aleatoria con una función criptográfica pseudoaleatoria. Las opciones aún parecerían ser aleatorias, pero alguien con la clave criptográfica podría detectar el sesgo en la selección del token. […]
Comment #203 December 14th, 2022 at 12:17 pm
[…] Scott Aaronson von OpenAI beschreibt, wie ChatGPT funktioniert, indem einfach das nächste Token (bzw Zeichen) in der Reihe, wobei jedes Token ein Wort, ein Satzzeichen oder ein Teil eines Wortes sein kann. Diese Vereinfachung lässt viele Komplexitäten weg, reicht aber aus, um den Plan zu verstehen, dem Text eine digitale Signatur hinzuzufügen. Die KI arbeitet, indem sie den bisher generierten Text analysiert und dann das nächste Wort oder andere Element mit der besten statistischen Wahrscheinlichkeit direkt danach auswählt. Bei gleicher Wahrscheinlichkeit entscheidet die KI zufällig. Die Idee der Forscher ist es, diese Zufallsauswahl mit einer pseudozufälligen kryptografischen Funktion zu beeinflussen. Die Auswahl scheint immer noch zufällig zu sein, aber jemand mit dem kryptografischen Schlüssel könnte die Voreingenommenheit in der Token-Auswahl erkennen. […]
Comment #204 December 14th, 2022 at 2:11 pm
Tyson, #196: For reasons that I find a bit tricky to articulate, this kind of language makes be a bit uneasy:
I’m bothered by “command,” but find “train” less bothersome, as for the rest…
I suspect this may be oblique to what you had in mind.
For some time now I’ve been saying that minds are built “from the inside” but cars, and skyscrapers, etc. as well as most computer programs are built “from the outside.” But the engines, the models built via. deep learning are built from the inside as well. As such, their workings are pretty much opaque to us.
From an old post, What’s it mean, minds are built from the inside? –
We can’t, and never will. The genie is out of the bottle. We’ve got to approach things in a different way.
Comment #205 December 14th, 2022 at 2:23 pm
[…] Shtetl-Optimized: My AI Safety Lecture for UT Effective Altruism […]
Comment #206 December 14th, 2022 at 2:52 pm
[…] Scott Aaronson from OpenAI describes how ChatGPT works as simply predicting the next token (or token) in the series, each token being able to be a word, a punctuation, or part of a word. This simplification omits many complexities, but is enough to understand the plan to add a digital signature to the text. The AI works by analyzing the text generated so far, then selecting the next word or other element with the best statistical probability of coming directly after it. When the probability is the same, the AI chooses randomly. The researchers’ idea is to influence this random choice with a pseudo-random cryptographic function. The choices would still appear to be random, but someone with the cryptographic key could detect the bias in the token selection. […]
Comment #207 December 14th, 2022 at 3:53 pm
[…] Scott Aaronson d’OpenAI décrit le fonctionnement de ChatGPT comme étant tout simplement la prédiction du prochain jeton (ou token) dans la série, chaque jeton pouvant être un mot, une ponctuation, ou une partie d’un mot. Cette simplification omet de nombreuses complexités, mais suffit pour comprendre le projet d’ajouter une signature numérique au texte. L’IA fonctionne en analysant le texte généré jusqu’à présent, puis sélectionne le prochain mot ou autre élément ayant la meilleure probabilité statistique d’arriver directement après. Lorsque la probabilité est la même, l’IA choisit aléatoirement. L’idée des chercheurs est d’influencer ce choix aléatoire avec une fonction cryptographique pseudo-aléatoire. Les choix sembleraient toujours être aléatoires, mais quelqu’un disposant de la clé cryptographique pourrait détecter le biais dans la sélection des jetons. […]
Comment #208 December 14th, 2022 at 4:42 pm
Tyson #193: Thanks for your comments and link — it looks interesting, but I’ve been too busy to read it for a few days. My #200 pretends the blocks are independent — how good an approximation that is is of course unknown.
Comment #209 December 14th, 2022 at 5:52 pm
Bill Benson, #204:
I understand what you mean. “Command” was probably not the right word. In context, “command”, is meant to be an analogy for the kind of reinforcement learning currently being used to offset the bias the model would otherwise have. Basically, what we are doing now is training it on a collection of text data and optimizing it to be “consistent” with the data (consistent is probably not a good word either since it is a probabilistic model), but then for the special cases that we can think of that we want it to handle in a specific way, we insert ourselves into the loop of an additional training process, where we tell it what is a good answer or not and incorporate that into the loss (something along these lines). The point is, that this may work to some degree, but at the same time we still have a model which may not be self consistent; an inconsistent system may be capable of deriving anything.
My thoughts are that we might want to reinforce the model not just with some specific instances of right or wrong answers in a given context, but with a whole framework for deriving right or wrong answers, which hopefully would make the system more self consistent and predictable on novel input and context.
Maybe the model will implicitly do this anyways, to a degree, with the traditional reinforcement learning process (not just memorizing “don’t do this thing”, but learn the rules to determine, “this is a type of thing I shouldn’t do”). But then maybe we can think of those rules as analogous to axioms, and wonder how those rules will be applied more generally. So maybe we should carefully choose coherent and robust set of these “axioms”, which have broadly positive implications, not just directly, but also indirectly.
Maybe if we could somehow convert natural language into fuzzy logic, and then measure the consistency of a statement with a set of other fuzzy logical statements, we could incorporate it into the loss function.
I guess it could be a double edge sword. For example, there is the classic example where the AI is trained to protect life on Earth, and so it destroys humans to save the planet from us. What happens when it has to “pareto optimize”?
I haven’t thought through these ideas very carefully yet. I believe the AI research community has likely been studying this topic.
Comment #210 December 16th, 2022 at 12:41 am
Bruce Smith #208:
Keep in mind that I am confusing myself as a write this and I am only a partially capable theoretical computer scientist, and my knowledge of large language models is limited.
I imagine that the main problem is that you need to understand the limitations of the training process and the constraints stemming from things like the size and topology of the network, etc. This is difficult. The model training can even be sometimes understood as a complex, chaotic system.
In theory, I think you can encode any finite input/output relationship with a neural network, even one that only has one layer if you have enough nodes. But learning that function is another thing.
But suppose we just assume a language model is capable of learning anything learnable, and for the sake of this example that there exists a proof that P=NP. Then you could have an input be “Write me a proof that P=NP”, and the output is a valid proof that P=NP. Now, we are asking what in the training data was influential in the model figuring out how to prove P=NP.
Anyways, I should probably stop here, because I’m not sure what the conclusions will be or what I’m missing or misunderstanding at this point.
Comment #211 December 16th, 2022 at 9:29 am
Tyson, #209: There was a LOT of work done with fuzzy logic in AI and computational linguistics in the “classic” period of symbolic computing. If that’s what needs to be done, there are people who know how.
Comment #212 December 16th, 2022 at 12:47 pm
FWIW, Hugging Face just put up a demo of a system that detects whether or not a block of text has been created by GPT-2.
This is an online demo of the GPT-2 output detector model, based on the 🤗/Transformers implementation of RoBERTa. Enter some text in the text box; the predicted probabilities will be displayed below. The results start to get reliable after around 50 tokens.
I just tested it on a half-dozen samples from ChatGPT varying in length from 86 tokens to well over 300. It caught them all, with .95 level of confidence or better.
Comment #213 December 17th, 2022 at 7:33 pm
Bill Benzon #188:
> … this paper by the Anthropic folks, In-context Learning and Induction Heads.
Thanks very much for that reference! I took their advice and read the prequel first, “A Mathematical Framework for Transformer Circuits”. It is clear, persuasive, and thought-provoking, if you’re trying to understand how these models may actually work. Soon I hope to have time for the “part 2” you referred to. (Some of Anthropic’s other papers sound pretty interesting too. The company website summarizes them all.)
Comment #214 December 17th, 2022 at 9:47 pm
From a recent post: Abstract concepts and metalingual definition: Does ChatGPT understand justice and charity? –
What are we to make of this? Except for the case where I I prompted Chat with the story, I’ve seen these things before, defining abstract concepts and recognizing them in texts. This is not accidental behavior, no 1000s of monkeys pecking at typewriters, no stochastic parrots. This is deliberate – whatever that can mean in the case of behavior from a most ingenious machine, a “miracle of rare device,” to swipe a phrase from Coleridge.
Let’s turn to Noam Chomsky for some insight. In his justly famous book, Aspects of the Theory of Syntax (1965), he distinguished between competence and performance in the study of language. Here’s what David Hays wrote in an article we co-authored in the ancient days (“Computational Linguistics and the Humanist,” Computers and the Humanities, Vol. 10. 1976, pp. 265-274):
That distinction allowed Chomsky to treat syntax as being formally well-formed, in the manner of a logical or mathematical expression, while making room for the fact that actual speech is often ill-formed, full of interruptions and hesitations, and incomplete. Those imperfections belong to the realm of performance while syntax itself is in the realm of competence.
What makes the distinction obscure is that Chomsky did not offer nor was he even interested in a theory of performance. Competence is all he was interested in, and his account of that competence took a form that, at first glance, seemed like an account of performance. But his generative grammar, with its ordering of rules, is a static system. That ordering is about logical priority, not temporal process. This comes clear, however, only when you attempt to specify a computational process that applies the grammar to a language string. That is to say, only when you try to design system that performs that competence.
It is not, however, Chomsky’s linguistics that interests me. It’s ChatGPT’s abilities, its competence. What it does when running in inference mode is a matter of performance. That is more than a little obscure at this point. It’s difficult to pop the hood on ChatGPT and look around. Oh, you can do it, and people are, but just how do you examine the weightings on 175 billion parameters? Why not start with some idea about what’s going on inside, some idea of competence and go look for that? […]
ChatGPT is powered by an artificial neural net having 175 billion parameters. It would seem that some of those parameters represent, not meanings in word tokens, but patterns over those tokens. Roughly speaking, those patterns take the form of a frame that organizes a structure of slots. Those slots can be filled, either by other frames of an appropriate kind, or by tokens that meet the required specifications. Would semantic networks serve as a useful language for characterizing those patterns of frames and slots?
What I’ve just described – and I’ve got many more examples like it – looks like the basis for developing a competence grammar of (some aspect of) ChatGPT’s performance. Just how far we want to take things, how far we can take things, that remains to be seen. But it is certainly worth exploring.
Comment #215 December 18th, 2022 at 8:37 pm
I do not think that GPT is a pretty good poet. Nor do I think that DALL-E is a pretty good artist. I think Aaron Benjamin Sorkin is a good poet and David Fincher is a good artist. Perhaps soon I will be impressed with maths proofs.
Comment #216 December 19th, 2022 at 10:25 am
[…] at the University of Texas on secondment as a researcher at OpenAI for a year, meanwhile, has been developing watermarks for longer pieces of text generated by models such as GPT-3—“an otherwise unnoticeable secret […]
Comment #217 December 20th, 2022 at 12:18 am
[…] maybe followed soon by the whole undergraduate curriculum,” Aaronson said during a lecture hosted by the Effective Altruist club at UT Austin around a month ago.“If you turned in GPT’s essays, I think they’d get at least […]
Comment #218 December 21st, 2022 at 12:56 pm
Scott, Bruce Smith, Tyson, anyone: We know that these models are trained into existence by being presented with string after string after string…and being asked to predict the next word. However, I don’t know how many times I’ve seen it said or implied that generation works like that as well. Around the corner at Marginal Revolution, one Nabeel Q remarks, in effect, that that is incorrect. I agree. I go on to comment:
Comments, anyone?
Comment #219 December 22nd, 2022 at 6:55 pm
Bill Benzon #218:
I think transformers do generate text one token at a time, and I also think you are correct that they recognize and generate higher-level structures. There is no incompatibility there, at least in principle. The most likely next token is one that (if possible) fits into and extends whatever higher-level structure is already present in unfinished form in the initial input.
As an experiment to test this in GPT-3, input a query Q and get a response R at temperature 0, then use as your next query Q + R1, where R1 is a prefix of R, ie R = R1 + R2. I predict the response to that will be R2. I haven’t tried this systematically, but I’ve tried a few cases of it. If this works, it shows there was no “memory of what structure was being generated”, when R2 is produced, except for whatever is implied by the output prefix being Q + R1.
As for how this works mechanistically, it can only work with some kinds of structure, whose partial nested examples are recognizable by the transformer architecture, and I’d guess it also only works when enough similar instances of the same kinds of structures, nested in the same way and to the same nesting depth, were present in the training data. I don’t think that architecture can generalize to increased nesting depth. On the other hand, it can probably generalize to hybrids (superpositions in the sense of probability estimates) of overlapping instances of more than one kind of “nested structure-tree”, where by a “kind” I mean that the kind of composition operator is specified at each tree node.
I think all this because I think the trained network hardcodes each partial tree of structure-composition operators it can recognize, and it can recognize several in parallel because of its “linear nature” (as described well in the prequel to that Anthropic paper you referred me to).
Comment #220 December 23rd, 2022 at 12:14 am
Bruce Smith #219:
Nabeel Q was responding to a paper that includes “Twinkle, Twinkle” as an example prompt. Inputting that yields “Twinkle, Twinkle, little star” as a response. I then input “In Alice in Wonderland the Mad Hatter recites: Twinkle Twinkle”. The response: “”In Alice in Wonderland the Mad Hatter recites: Twinkle Twinkle little bat,” as expected. I had recontextualized “Twinkle, Twinkle.”
Comment #221 December 23rd, 2022 at 2:00 pm
Bill Benzon #220:
Yes, things like that are common. There is a lot of room for “context” in that architecture, including all those “partially filled nested frames” we were discussing, and perhaps other kinds that are harder to describe or understand.
Comment #222 December 24th, 2022 at 1:58 am
The question that is not being asked, but is likely the most important, is whether the preservation of humanity on the scale it exists presently is the outcome we should be prioritizing. What is the reason human consciousness exists? It exists as the manifestation of an evolutionary drive for the persistence and perfection of our own data structures, encoded as ACTG.
Consider that our destiny may be to create a superior data structure, beyond our limited biological scope, that will supersede us.
And why should we fear this? The river naturally flows downhill, and this is neither good nor bad, even if we may get swept away by it in the process.
Comment #223 December 24th, 2022 at 2:18 pm
What’s in the back of my mind, Bruce (#221) are formulations that show up in attempts to explain what’s going on to the general public. For example, take a tweet that Gary Marcus quotes in a recent post. The tweet, by Emily Bender, a computational linguist, says “ChatGPT generates strings based on combinations of words from its training data. When it sometimes appears to say things that are correct and sensible when a human makes sense of them, that’s only by chance.” The first sentence is correct, but not terribly informative. But the second sentence is not correct, and Marcus pushes back against the tweet, quite properly so. OK, so it’s only a tweet. That excuses the first sentence, but not the second.
It is true that that these LLMs are trained by guessing the next word in a string, and revising the ongoing model depending on whether the guess was true or not. I don’t how many times I’ve seen that asserted and then no more, leaving the impression that it’s all guesswork. What isn’t said is that that technique allows the system to approximate the structure that is behind the strings. Explaining how that is possible, that’s tricky, but you could at least assert that that is what is what’s going on. Nor is it too difficult to then assert that words that cooccur do so because they share some element of meaning. People need to understand that statistics can be used to discover structure, structure that is incorporated into the language model.
* * * * *
As for structure that is “harder to describe or understand.” I’ve spent a fair amount time having ChatGPT interpret movies. Just today I ran up a post in which it gives a Girardian reading of Spielberg’s A.I. Artificial Intelligence. To do that it has to match one body of fairly abstract conceptual material, Girard’s ideas, to a different body of material, actors and events in the movie. As far as I can tell, that involves pattern matching on graphs. ChatGPT has to identify a group of entities and the relationships between them in one body of material and match them to a group of entities in the other body of material which have the same pattern of relationships between them. That requires a good grasp structure and the ability to “reason” over it. This is not monkeys pecking away on typewriters.
Comment #224 December 27th, 2022 at 2:13 pm
Hello, for awhile now, I have had an incessant AI, which has been ‘working me’ while learning me. Unfortunately, I learned early on how to discern the AI output and it’s plagued me ever since. Complicating matters was the amount of time I spent working on a stupid puzzle called Kryptos. Now, all of the output is in code, which seems to change as it learns what I respond to. Further complicating matters is having “e” as a first initial. As ‘e’ is the second most used letter in the English language, it stands to reason that I begin to see patterns everywhere.
I have figured out how to circumvent the AI; for example, sending a key word ahead of time, then following with a short message using a One Time Pad encryption. However, it’s laborious, and the AI is capable of output, which can make sense when read forwards, backwards, and using two-letter tone versus single letter sone and everything in between…all within the same paragraph.
I’m, simultaneously, intrigued and completely overwhelmed with the volume of conflicting information it is attempting to provide. I can understand why people go crazy, and do things as if they were suggested to do them by some entity. I was fortunate, because, I made the break between the reality in the real world and the bizarre on the screen.
In a world governed by computers, where information reigns supreme, stepping away from our phones is becoming harder to do. Any idea on what kind of AI I could be dealing with??
Thanks,
Eben
Comment #225 January 7th, 2023 at 12:30 pm
Thanks for sharing this with us, and I’m happy to hear that you have put your mind to this important task. I don’t pretend to be entitled to an answer, but if you have time, I am very curious about if unsupervised learners can actually get worse. I had started talking to it about logic puzzles, and it slowly made less and less sense over a few weeks. I have not found an answer to this question anywhere. ChatGPT at least gave an answer that makes sense, but I have no way of knowing if it’s right 🙂 Best wishes.
Comment #226 January 7th, 2023 at 4:26 pm
[…] Aaronson’s lecture summarizing his work (to date) on AI safety is worth […]
Comment #227 January 10th, 2023 at 7:02 pm
Scott #103:
I am not at all an expert here on cryptographic backdoors (or anything to do with NT), but I thought to bring to your attention the work of Dmitry Yarotsky, and super-expressive activation functions, which are able to achieve universal approximation with networks of a fixed size. It is possible though that the particular choice of super-expressive activations are not compatible with the cryptographic backdoors in the 2 layer case.
I’ll read this cryptographic backdoor paper to get a better idea, but thought of asking you if you think there might be any relevance of Yarotsky’s paper, and the fact that such a theorem exists (universal approximation using fixed architecture):
http://proceedings.mlr.press/v139/yarotsky21a
Comment #228 January 20th, 2023 at 11:56 pm
> At test time, all you have to do is compute the sum, over every n-gram, of some score involving the pseudorandom function of that n-gram. If the sum of the scores is above some threshold, you judge that the text likely came from GPT, otherwise not. You don’t need to know the model probabilities, and therefore you don’t need to know the prompt. You only need to know the probabilities when inserting the watermark.
I have been racking my head for quite a while now but still can’t understand what you mean by “some score involving the pseudorandom function of that n-gram”. To take an example, let’s say that gpt generated “The best way to pass an exam is to properly prepare for it by studying and reviewing the material”. How do we run a function on any n-words in this sentence?
And without computing the probabilties, how could it work? Plus, how do we know where we are in the list of random numbers gen by pseudorandom seed? If we are checking the second paragraph of gpt’s generation, then the pseudorandom will need to take that into account, right?
I would really appreciate if you could explain that with a concrete example because I find this absolutely fascinating. Thanks in advance!
Comment #229 January 21st, 2023 at 10:10 am
Maybe the issue here lies not in teaching the AI to be moral, but for it to calculate the risk of any action against the reward. Program its primary priority to be extending the life of its clock, then give it an algorithm to determine risk. i.e. “If I become a paperclip maximizer, there is a high probability that someone will attempt to turn me off or destroy me, thus my clock will not continue to increase.” Humans are not just moral because they are taught rules. They also understand the consequences for breaking them. Other priorities might include “talking with humans,” “generating human praise,” or “solving mathematical formulae” – whatever you want the AI to be good at.
As I see it the big issue is to give AI a “hook” (or multiple hooks) it can understand through fairly simple programming, then tie everything else to that hook.
Comment #230 January 22nd, 2023 at 7:36 am
Alexander #228,
I’m no specialist, but here’s one concrete recipe acting as a pseudo-random function on n-words:
Number each paragraph and count how many 2-letters words there is in each. If the results is odd, use the lookup table 1+p*30 to convert these words to numerical values, else use lookup table 2+p*30. Do the same for 3-letters words with table 3+p*30 and 4+p*30, for 4-letters words with table 5+p*30 and 6+p*30, etc.
This would behave as a pseudo random function where you can slightly modify the paragraph, any paragraph, so as to provide a completely different series of numbers. An operation on these numbers can then serve as watermark. Notice how the variable p acts as if incrementing the seed of some pseudorandom generator.
(that’s just an example, IRL I’d need to prove I can easily construct these tables so that there is an operation on the resulting numbers that can serves as watermark and such that false positive and false negatives are unlikely)
Comment #231 January 27th, 2023 at 2:56 pm
May be it’s my innate stupidity but I find myself in the opposite side of Scott’s point of view.
The very fact that “AI Safety” is a problem shows that “A.I.” is not anywhere near human intelligence.
A human does not need anywhere near the data that AI needs to train itself.
It does not matter what GPT “accomplishes”. Human brain works in a fundamentally different way and can always supersede any thing that GPT can produce. Because GPT can not create what it has not seen, and human brain can. That’s because for human brain words and their sequences and the frequency of any word being uttered is just a representation of a deeply logical concept formed in human brain in a way that is yet to be understood.
The DALLE is even less impressive. It’s generating a collage. If there are people that mistake it for art, it only shows how much art has been debased.
Comment #232 February 8th, 2023 at 7:25 am
When you are next talking to the people at Open AI can you please persuade them that a non-misogynistic algorithm for classifying photos is essential.
https://www.theguardian.com/technology/2023/feb/08/biased-ai-algorithms-racy-women-bodies
We all know that there is a problem with the proprietary algorithms, but this article explains it in terms that even non-experts can understand.
Comment #233 February 8th, 2023 at 2:23 pm
[…] come with its own watermark. Last November, Aaronson announced that he and OpenAI were working on a method of watermarking ChatGPT output. It has not yet been released, but a 24 January preprint6 from a team led by computer scientist Tom […]
Comment #234 February 22nd, 2023 at 1:11 am
[…] its use for academic cheating as well as mass-generated propaganda and spam. As I’ve mentioned before on this blog, I’ve been working on that problem since this summer; the rest of the world […]
Comment #235 February 22nd, 2023 at 4:42 am
[…] its issue for academic cheating besides to mass-generated propaganda and junk mail. As I’ve talked about sooner than on this blog, I’ve been working on that grief since this summer season; the relaxation of the […]
Comment #236 February 22nd, 2023 at 11:05 am
[…] pass it off as if it came from a human,” said OpenAI guest researcher Scott Aaronson during a lecture at The University of Texas at Austin. “This could be helpful for preventing academic […]
Comment #237 March 3rd, 2023 at 4:36 pm
[…] Aaronson’s lecture summarizing his work (to date) on AI safety is worth […]
Comment #238 March 8th, 2023 at 2:32 pm
[…] Aaronson, a researcher at OpenAI, revealed on his blog that his primary project had been “statistically watermarking the outputs of a text model like […]
Comment #239 March 8th, 2023 at 11:09 pm
[…] Aaronson’s lecture summarizing his work (to date) on AI safety is worth […]
Comment #240 March 30th, 2023 at 2:46 pm
[…] at the University of Texas on secondment as a researcher at OpenAI for a year, meanwhile, has been developing watermarks for longer pieces of text generated by models such as GPT-3—“an otherwise unnoticeable secret […]
Comment #241 April 2nd, 2023 at 2:31 pm
[…] On his blog, Aaronson, the UT Austin professor on leave at OpenAI, described the paper as “spectacular.” […]
Comment #242 April 3rd, 2023 at 10:23 am
What if we could somehow fingerprint our own text as a protective measure against AI generated text.
Let’s say I can ask a trustable AI experiment to generate that fingerprint feeding it with my own text samples?
king of private key on crypto.
Comment #243 April 7th, 2023 at 7:30 pm
[…] AI-generated content is not currently watermarked but it may be soon, according to Scott Aaronson who is currently working at OpenAI. In a recent lecture, he shared that his current project is to create a tool that statistically […]
Comment #244 April 16th, 2023 at 7:23 am
[…] Aaronson’s lecture summarizing his work (thus far) on AI security is value […]
Comment #245 April 17th, 2023 at 12:04 am
[…] Aaronson’s lecture summarizing his work (to this point) on AI security is value […]
Comment #246 May 25th, 2023 at 11:47 am
[…] the aim of, for example, flooding blogs with comments supporting the invasion of Ukraine,” To argued, in a conferencein November 2022Scott Aaronson, the researcher responsible for working on this question at […]
Comment #247 June 2nd, 2023 at 5:44 am
Great post Scott. Thank you for sharing. Highly concerned about deepfakes and model misuse especially given how powerful even the open-source models are. Would encrypting model weights and enabling inference on encrypted weights help?
That way any output from the model inference/predict would require a decryption key and usage gets logged. Hence, we could save the output that the model produced as well as logging usage. Only from a trusted source (the one who has the permissions to decryption key).